


Summary
In ordinary language, an average is a single number or value that best represents a set of data. The type of average taken as most typically representative of a list of numbers is the arithmetic mean – the sum of the numbers divided by how many numbers are in the list. For example, the mean average of the numbers 2, 3, 4, 7, and 9 (summing to 25) is 5. Depending on the context, the most representative statistic to be taken as the average might be another measure of central tendency, such as the mid-range, median, mode or geometric mean. For example, the average personal income is often given as the median – the number below which are 50% of personal incomes and personal incomes from a few billionaires. For this reason, it is recommended to avoid using the word "average" when discussing measures of central tendency and specify which type of measure of average is being used.
General properties edit
If all numbers in a list are the same number, then their average is also equal to this number. This property is shared by each of the many types of average.
Another universal property is monotonicity: if two lists of numbers A and B have the same length, and each entry of list A is at least as large as the corresponding entry on list B, then the average of list A is at least that of list B. Also, all averages satisfy linear homogeneity: if all numbers of a list are multiplied by the same positive number, then its average changes by the same factor.
In some types of average, the items in the list are assigned different weights before the average is determined. These include the weighted arithmetic mean, the weighted geometric mean and the weighted median. Also, for some types of moving average, the weight of an item depends on its position in the list. Most types of average, however, satisfy permutation-insensitivity: all items count equally in determining their average value and their positions in the list are irrelevant; the average of (1, 2, 3, 4, 6) is the same as that of (3, 2, 6, 4, 1).
Pythagorean means edit
The arithmetic mean, the geometric mean and the harmonic mean are known collectively as the Pythagorean means.
Statistical location edit
The mode, the median, and the mid-range are often used in addition to the mean as estimates of central tendency in descriptive statistics. These can all be seen as minimizing variation by some measure; see Central tendency § Solutions to variational problems.
| Type | Description | Example | Result |
|---|---|---|---|
| Arithmetic mean | Sum of values of a data set divided by number of values: | (1+2+2+3+4+7+9) / 7 | 4 |
| Median | Middle value separating the greater and lesser halves of a data set | 1, 2, 2, 3, 4, 7, 9 | 3 |
| Mode | Most frequent value in a data set | 1, 2, 2, 3, 4, 7, 9 | 2 |
| Mid-range | The arithmetic mean of the highest and lowest values of a set | (1+9) / 2 | 5 |

Mode edit
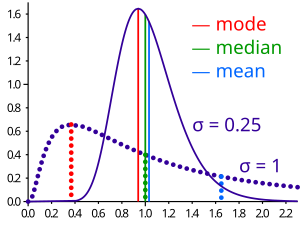
The most frequently occurring number in a list is called the mode. For example, the mode of the list (1, 2, 2, 3, 3, 3, 4) is 3. It may happen that there are two or more numbers which occur equally often and more often than any other number. In this case there is no agreed definition of mode. Some authors say they are all modes and some say there is no mode.
Median edit
The median is the middle number of the group when they are ranked in order. (If there are an even number of numbers, the mean of the middle two is taken.)
Thus to find the median, order the list according to its elements' magnitude and then repeatedly remove the pair consisting of the highest and lowest values until either one or two values are left. If exactly one value is left, it is the median; if two values, the median is the arithmetic mean of these two. This method takes the list 1, 7, 3, 13 and orders it to read 1, 3, 7, 13. Then the 1 and 13 are removed to obtain the list 3, 7. Since there are two elements in this remaining list, the median is their arithmetic mean, (3 + 7)/2 = 5.
Mid-range edit
The mid-range is the arithmetic mean of the highest and lowest values of a set.
Summary of types edit
| Name | Equation or description | As solution to optimization problem |
|---|---|---|
| Arithmetic mean | ||
| Median | A middle value that separates the higher half from the lower half of the data set; may not be unique if the data set contains an even number of points | |
| Geometric median | A rotation invariant extension of the median for points in | |
| Tukey median | Another rotation invariant extension of the median for points in —a point that maximizes the Tukey depth | |
| Mode | The most frequent value in the data set | |
| Geometric mean | ||
| Harmonic mean | ||
| Lehmer mean | ||
| Quadratic mean (or RMS) |
||
| Cubic mean | ||
| Generalized mean | ||
| Quasi-arithmetic mean | is monotonic | |
| Weighted mean | ||
| Truncated mean | The arithmetic mean of data values after a certain number or proportion of the highest and lowest data values have been discarded | |
| Interquartile mean | A special case of the truncated mean, using the interquartile range. A special case of the inter-quantile truncated mean, which operates on quantiles (often deciles or percentiles) that are equidistant but on opposite sides of the median. | |
| Midrange | ||
| Winsorized mean | Similar to the truncated mean, but, rather than deleting the extreme values, they are set equal to the largest and smallest values that remain | |
| Medoid | A representative object of a set of objects with minimal sum of dissimilarities to all the objects in the set, according to some dissimilarity function . |







![{\displaystyle {\sqrt[{n}]{\prod _{i=1}^{n}x_{i}}}={\sqrt[{n}]{x_{1}\cdot x_{2}\dotsb x_{n}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a3740b9924a63fcde06a3fd26d9691c082910d78)






![{\displaystyle {\sqrt[{3}]{{\frac {1}{n}}\sum _{i=1}^{n}x_{i}^{3}}}={\sqrt[{3}]{{\frac {1}{n}}\left(x_{1}^{3}+x_{2}^{3}+\cdots +x_{n}^{3}\right)}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/87ea526bc6b48f6abb52bc522d57c9fedacbaf90)

![{\displaystyle {\sqrt[{p}]{{\frac {1}{n}}\cdot \sum _{i=1}^{n}x_{i}^{p}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b914d893b094e9e15a5681ef60069e9e5fac54ab)










The table of mathematical symbols explains the symbols used below.
Miscellaneous types edit
Other more sophisticated averages are: trimean, trimedian, and normalized mean, with their generalizations.[1]
One can create one's own average metric using the generalized f-mean:
![{\displaystyle y=f^{-1}\left({\frac {1}{n}}\left[f(x_{1})+f(x_{2})+\cdots +f(x_{n})\right]\right)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5fea48be50f3fe5836ae433848e3e4ca0c9827a5)
where f is any invertible function. The harmonic mean is an example of this using f(x) = 1/x, and the geometric mean is another, using f(x) = log x.
However, this method for generating means is not general enough to capture all averages. A more general method[2][failed verification] for defining an average takes any function g(x1, x2, ..., xn) of a list of arguments that is continuous, strictly increasing in each argument, and symmetric (invariant under permutation of the arguments). The average y is then the value that, when replacing each member of the list, results in the same function value: g(y, y, ..., y) = g(x1, x2, ..., xn). This most general definition still captures the important property of all averages that the average of a list of identical elements is that element itself. The function g(x1, x2, ..., xn) = x1+x2+ ··· + xn provides the arithmetic mean. The function g(x1, x2, ..., xn) = x1x2···xn (where the list elements are positive numbers) provides the geometric mean. The function g(x1, x2, ..., xn) = (x1−1+x2−1+ ··· + xn−1)−1) (where the list elements are positive numbers) provides the harmonic mean.[2]
Average percentage return and CAGR edit
A type of average used in finance is the average percentage return. It is an example of a geometric mean. When the returns are annual, it is called the Compound Annual Growth Rate (CAGR). For example, if we are considering a period of two years, and the investment return in the first year is −10% and the return in the second year is +60%, then the average percentage return or CAGR, R, can be obtained by solving the equation: (1 − 10%) × (1 + 60%) = (1 − 0.1) × (1 + 0.6) = (1 + R) × (1 + R). The value of R that makes this equation true is 0.2, or 20%. This means that the total return over the 2-year period is the same as if there had been 20% growth each year. The order of the years makes no difference – the average percentage returns of +60% and −10% is the same result as that for −10% and +60%.
This method can be generalized to examples in which the periods are not equal. For example, consider a period of a half of a year for which the return is −23% and a period of two and a half years for which the return is +13%. The average percentage return for the combined period is the single year return, R, that is the solution of the following equation: (1 − 0.23)0.5 × (1 + 0.13)2.5 = (1 + R)0.5+2.5, giving an average return R of 0.0600 or 6.00%.
Moving average edit
Given a time series, such as daily stock market prices or yearly temperatures, people often want to create a smoother series.[3] This helps to show underlying trends or perhaps periodic behavior. An easy way to do this is the moving average: one chooses a number n and creates a new series by taking the arithmetic mean of the first n values, then moving forward one place by dropping the oldest value and introducing a new value at the other end of the list, and so on. This is the simplest form of moving average. More complicated forms involve using a weighted average. The weighting can be used to enhance or suppress various periodic behavior and there is very extensive analysis of what weightings to use in the literature on filtering. In digital signal processing the term "moving average" is used even when the sum of the weights is not 1.0 (so the output series is a scaled version of the averages).[4] The reason for this is that the analyst is usually interested only in the trend or the periodic behavior.
History edit
Origin edit
The first recorded time that the arithmetic mean was extended from 2 to n cases for the use of estimation was in the sixteenth century. From the late sixteenth century onwards, it gradually became a common method to use for reducing errors of measurement in various areas.[5][6] At the time, astronomers wanted to know a real value from noisy measurement, such as the position of a planet or the diameter of the moon. Using the mean of several measured values, scientists assumed that the errors add up to a relatively small number when compared to the total of all measured values. The method of taking the mean for reducing observation errors was indeed mainly developed in astronomy.[5][7] A possible precursor to the arithmetic mean is the mid-range (the mean of the two extreme values), used for example in Arabian astronomy of the ninth to eleventh centuries, but also in metallurgy and navigation.[6]
However, there are various older vague references to the use of the arithmetic mean (which are not as clear, but might reasonably have to do with our modern definition of the mean). In a text from the 4th century, it was written that (text in square brackets is a possible missing text that might clarify the meaning):[8]
- In the first place, we must set out in a row the sequence of numbers from the monad up to nine: 1, 2, 3, 4, 5, 6, 7, 8, 9. Then we must add up the amount of all of them together, and since the row contains nine terms, we must look for the ninth part of the total to see if it is already naturally present among the numbers in the row; and we will find that the property of being [one] ninth [of the sum] only belongs to the [arithmetic] mean itself...
Even older potential references exist. There are records that from about 700 BC, merchants and shippers agreed that damage to the cargo and ship (their "contribution" in case of damage by the sea) should be shared equally among themselves.[7] This might have been calculated using the average, although there seem to be no direct record of the calculation.
Etymology edit
The root is found in Arabic as عوار ʿawār, a defect, or anything defective or damaged, including partially spoiled merchandise; and عواري ʿawārī (also عوارة ʿawāra) = "of or relating to ʿawār, a state of partial damage".[a] Within the Western languages the word's history begins in medieval sea-commerce on the Mediterranean. 12th and 13th century Genoa Latin avaria meant "damage, loss and non-normal expenses arising in connection with a merchant sea voyage"; and the same meaning for avaria is in Marseille in 1210, Barcelona in 1258 and Florence in the late 13th.[b] 15th-century French avarie had the same meaning, and it begot English "averay" (1491) and English "average" (1502) with the same meaning. Today, Italian avaria, Catalan avaria and French avarie still have the primary meaning of "damage". The huge transformation of the meaning in English began with the practice in later medieval and early modern Western merchant-marine law contracts under which if the ship met a bad storm and some of the goods had to be thrown overboard to make the ship lighter and safer, then all merchants whose goods were on the ship were to suffer proportionately (and not whoever's goods were thrown overboard); and more generally there was to be proportionate distribution of any avaria. From there the word was adopted by British insurers, creditors, and merchants for talking about their losses as being spread across their whole portfolio of assets and having a mean proportion. Today's meaning developed out of that, and started in the mid-18th century, and started in English.[b][9]
Marine damage is either particular average, which is borne only by the owner of the damaged property, or general average, where the owner can claim a proportional contribution from all the parties to the marine venture. The type of calculations used in adjusting general average gave rise to the use of "average" to mean "arithmetic mean".
A second English usage, documented as early as 1674 and sometimes spelled "averish", is as the residue and second growth of field crops, which were considered suited to consumption by draught animals ("avers").[10]
There is earlier (from at least the 11th century), unrelated use of the word. It appears to be an old legal term for a tenant's day labour obligation to a sheriff, probably anglicised from "avera" found in the English Domesday Book (1085).
The Oxford English Dictionary, however, says that derivations from German hafen haven, and Arabic ʿawâr loss, damage, have been "quite disposed of" and the word has a Romance origin.[11]
Averages as a rhetorical tool edit
Due to the aforementioned colloquial nature of the term "average", the term can be used to obfuscate the true meaning of data and suggest varying answers to questions based on the averaging method (most frequently arithmetic mean, median, or mode) used. In his article "Framed for Lying: Statistics as In/Artistic Proof", University of Pittsburgh faculty member Daniel Libertz comments that statistical information is frequently dismissed from rhetorical arguments for this reason.[12] However, due to their persuasive power, averages and other statistical values should not be discarded completely, but instead used and interpreted with caution. Libertz invites us to engage critically not only with statistical information such as averages, but also with the language used to describe the data and its uses, saying: "If statistics rely on interpretation, rhetors should invite their audience to interpret rather than insist on an interpretation."[12] In many cases, data and specific calculations are provided to help facilitate this audience-based interpretation.
See also edit
Notes edit
- ^ Medieval Arabic had عور ʿawr meaning "blind in one eye" and عوار ʿawār meant "any defect, or anything defective or damaged". Some medieval Arabic dictionaries are at Baheth.info Archived 2013-10-29 at the Wayback Machine, and some translation to English of what's in the medieval Arabic dictionaries is in Lane's Arabic-English Lexicon, pages 2193 and 2195. The medieval dictionaries do not list the word-form عوارية ʿawārīa. ʿAwārīa can be naturally formed in Arabic grammar to refer to things that have ʿawār, but in practice in medieval Arabic texts ʿawārīa is a rarity or non-existent, while the forms عواري ʿawārī and عوارة ʿawāra are frequently used when referring to things that have ʿawār or damage – this can be seen in the searchable collection of medieval texts at AlWaraq.net (book links are clickable on righthand side).
- ^ a b The Arabic origin of avaria was first reported by Reinhart Dozy in the 19th century. Dozy's original summary is in his 1869 book Glossaire. Summary information about the word's early records in Italian-Latin, Italian, Catalan, and French is at avarie @ CNRTL.fr Archived 2019-01-06 at the Wayback Machine. The seaport of Genoa is the location of the earliest-known record in European languages, year 1157. A set of medieval Latin records of avaria at Genoa is in the downloadable lexicon Vocabolario Ligure, by Sergio Aprosio, year 2001, avaria in Volume 1 pages 115-116. Many more records in medieval Latin at Genoa are at StoriaPatriaGenova.it, usually in the plurals avariis and avarias. At the port of Marseille in the 1st half of the 13th century notarized commercial contracts have dozens of instances of Latin avariis (ablative plural of avaria), as published in Blancard year 1884. Some information about the English word over the centuries is at NED (year 1888). See also the definition of English "average" in English dictionaries published in the early 18th century, i.e., in the time period just before the big transformation of the meaning: Kersey-Phillips' dictionary (1706), Blount's dictionary (1707 edition), Hatton's dictionary (1712), Bailey's dictionary (1726), Martin's dictionary (1749). Some complexities surrounding the English word's history are discussed in Hensleigh Wedgwood year 1882 page 11 and Walter Skeat year 1888 page 781. Today there is consensus that: (#1) today's English "average" descends from medieval Italian avaria, Catalan avaria, and (#2) among the Latins the word avaria started in the 12th century and it started as a term of Mediterranean sea-commerce, and (#3) there is no root for avaria to be found in Latin, and (#4) a substantial number of Arabic words entered Italian, Catalan and Provençal in the 12th and 13th centuries starting as terms of Mediterranean sea-commerce, and (#5) the Arabic ʿawār | ʿawārī is phonetically a good match for avaria, as conversion of w to v was regular in Latin and Italian, and -ia is a suffix in Italian, and the Western word's earliest records are in Italian-speaking locales (writing in Latin). And most commentators agree that (#6) the Arabic ʿawār | ʿawārī = "damage | relating to damage" is semantically a good match for avaria = "damage or damage expenses". A minority of commentators have been dubious about this on the grounds that the early records of Italian-Latin avaria have, in some cases, a meaning of "an expense" in a more general sense – see TLIO (in Italian). The majority view is that the meaning of "an expense" was an expansion from "damage and damage expense", and the chronological order of the meanings in the records supports this view, and the broad meaning "an expense" was never the most commonly used meaning. On the basis of the above points, the inferential step is made that the Latinate word came or probably came from the Arabic word.
References edit
- ^ Merigo, Jose M.; Cananovas, Montserrat (2009). "The Generalized Hybrid Averaging Operator and its Application in Decision Making". Journal of Quantitative Methods for Economics and Business Administration. 9: 69–84. ISSN 1886-516X.
- ^ a b Bibby, John (1974). "Axiomatisations of the average and a further generalisation of monotonic sequences". Glasgow Mathematical Journal. 15: 63–65. doi:10.1017/s0017089500002135.
- ^ Box, George E.P.; Jenkins, Gwilym M. (1976). Time Series Analysis: Forecasting and Control (revised ed.). Holden-Day. ISBN 0816211043.
- ^ Haykin, Simon (1986). Adaptive Filter Theory. Prentice-Hall. ISBN 0130040525.
- ^ a b Plackett, R. L. (1958). "Studies in the History of Probability and Statistics: VII. The Principle of the Arithmetic Mean". Biometrika. 45 (1/2): 130–135. doi:10.2307/2333051. JSTOR 2333051.
- ^ a b Eisenhart, Churchill. "The development of the concept of the best mean of a set of measurements from antiquity to the present day." Unpublished presidential address, American Statistical Association, 131st Annual Meeting, Fort Collins, Colorado. 1971.
- ^ a b Bakker, Arthur. "The early history of average values and implications for education." Journal of Statistics Education 11.1 (2003): 17-26.
- ^ "Waterfield, Robin. "The theology of arithmetic." On the Mystical, mathematical and Cosmological Symbolism of the First Ten Number (1988). page 70" (PDF). Archived from the original (PDF) on 2016-03-04. Retrieved 2018-11-27.
- ^ "average". Dictionary.com Unabridged (Online). n.d. Retrieved 2023-05-25.
- ^ Ray, John (1674). A Collection of English Words not Generally Used. London: H. Bruges. Retrieved 18 May 2015.
- ^ "average, n.2". Oxford English Dictionary (Online ed.). Oxford University Press. September 2019. Retrieved September 5, 2019. (Subscription or participating institution membership required.)
- ^ a b Libertz, Daniel (2018-12-31). "Framed for Lying: Statistics as In/Artistic Proof". Res Rhetorica. 5 (4). doi:10.29107/rr2018.4.1. ISSN 2392-3113.
External links edit
- Calculations and comparison between arithmetic and geometric mean of two values