


Summary
In the analysis of data, a correlogram is a chart of correlation statistics. For example, in time series analysis, a plot of the sample autocorrelations versus (the time lags) is an autocorrelogram. If cross-correlation is plotted, the result is called a cross-correlogram.



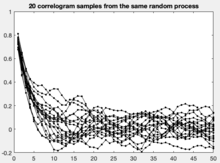
The correlogram is a commonly used tool for checking randomness in a data set. If random, autocorrelations should be near zero for any and all time-lag separations. If non-random, then one or more of the autocorrelations will be significantly non-zero.
In addition, correlograms are used in the model identification stage for Box–Jenkins autoregressive moving average time series models. Autocorrelations should be near-zero for randomness; if the analyst does not check for randomness, then the validity of many of the statistical conclusions becomes suspect. The correlogram is an excellent way of checking for such randomness.
In multivariate analysis, correlation matrices shown as color-mapped images may also be called "correlograms" or "corrgrams".[1][2][3]
Applications edit
The correlogram can help provide answers to the following questions:[4]
- Are the data random?
- Is an observation related to an adjacent observation?
- Is an observation related to an observation twice-removed? (etc.)
- Is the observed time series white noise?
- Is the observed time series sinusoidal?
- Is the observed time series autoregressive?
- What is an appropriate model for the observed time series?
- Is the model
- valid and sufficient?

- Is the formula valid?

Importance edit
Randomness (along with fixed model, fixed variation, and fixed distribution) is one of the four assumptions that typically underlie all measurement processes. The randomness assumption is critically important for the following three reasons:
- Most standard statistical tests depend on randomness. The validity of the test conclusions is directly linked to the validity of the randomness assumption.
- Many commonly used statistical formulae depend on the randomness assumption, the most common formula being the formula for determining the standard error of the sample mean:
where s is the standard deviation of the data. Although heavily used, the results from using this formula are of no value unless the randomness assumption holds.
- For univariate data, the default model is
If the data are not random, this model is incorrect and invalid, and the estimates for the parameters (such as the constant) become nonsensical and invalid.
Estimation of autocorrelations edit
The autocorrelation coefficient at lag h is given by

where ch is the autocovariance function

and c0 is the variance function

The resulting value of rh will range between −1 and +1.
Alternate estimate edit
Some sources may use the following formula for the autocovariance function:

Although this definition has less bias, the (1/N) formulation has some desirable statistical properties and is the form most commonly used in the statistics literature. See pages 20 and 49–50 in Chatfield for details.
In contrast to the definition above, this definition allows us to compute in a slightly more intuitive way. Consider the sample , where for . Then, let





We then compute the Gram matrix . Finally, is computed as the sample mean of the th diagonal of . For example, the th diagonal (the main diagonal) of has elements, and its sample mean corresponds to . The st diagonal (to the right of the main diagonal) of has elements, and its sample mean corresponds to , and so on.









Statistical inference with correlograms edit
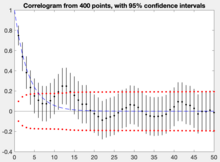
In the same graph one can draw upper and lower bounds for autocorrelation with significance level :

- with as the estimated autocorrelation at lag .

If the autocorrelation is higher (lower) than this upper (lower) bound, the null hypothesis that there is no autocorrelation at and beyond a given lag is rejected at a significance level of . This test is an approximate one and assumes that the time-series is Gaussian.
In the above, z1−α/2 is the quantile of the normal distribution; SE is the standard error, which can be computed by Bartlett's formula for MA(ℓ) processes:
- for



In the example plotted, we can reject the null hypothesis that there is no autocorrelation between time-points which are separated by lags up to 4. For most longer periods one cannot reject the null hypothesis of no autocorrelation.
Note that there are two distinct formulas for generating the confidence bands:
1. If the correlogram is being used to test for randomness (i.e., there is no time dependence in the data), the following formula is recommended:

where N is the sample size, z is the quantile function of the standard normal distribution and α is the significance level. In this case, the confidence bands have fixed width that depends on the sample size.
2. Correlograms are also used in the model identification stage for fitting ARIMA models. In this case, a moving average model is assumed for the data and the following confidence bands should be generated:

where k is the lag. In this case, the confidence bands increase as the lag increases.
Software edit
Correlograms are available in most general purpose statistical libraries.
Correlograms:
Corrgrams:
Related techniques edit
References edit
- ^ Friendly, Michael (19 August 2002). "Corrgrams: Exploratory displays for correlation matrices" (PDF). The American Statistician. 56 (4). Taylor & Francis: 316–324. doi:10.1198/000313002533. Retrieved 19 January 2014.
- ^ a b "CRAN – Package corrgram". cran.r-project.org. 29 August 2013. Retrieved 19 January 2014.
- ^ a b "Quick-R: Correlograms". statmethods.net. Retrieved 19 January 2014.
- ^ "1.3.3.1. Autocorrelation Plot". www.itl.nist.gov. Retrieved 20 August 2018.
- ^ "Visualization § Autocorrelation plot".
Further reading edit
- Hanke, John E.; Reitsch, Arthur G.; Wichern, Dean W. Business forecasting (7th ed.). Upper Saddle River, NJ: Prentice Hall.
- Box, G. E. P.; Jenkins, G. (1976). Time Series Analysis: Forecasting and Control. Holden-Day.
- Chatfield, C. (1989). The Analysis of Time Series: An Introduction (Fourth ed.). New York, NY: Chapman & Hall.
External links edit
- Autocorrelation Plot
![]() This article incorporates public domain material from the National Institute of Standards and Technology
This article incorporates public domain material from the National Institute of Standards and Technology