


Summary
In probability theory and statistics, the cumulative distribution function (CDF) of a real-valued random variable , or just distribution function of , evaluated at , is the probability that will take a value less than or equal to .[1]


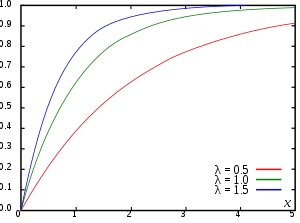
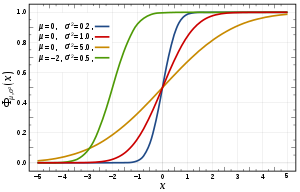
Every probability distribution supported on the real numbers, discrete or "mixed" as well as continuous, is uniquely identified by a right-continuous monotone increasing function (a càdlàg function) satisfying and .
![{\displaystyle F\colon \mathbb {R} \rightarrow [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4c45b6faf38bb3fb300ab4678d3675afd172f56)


In the case of a scalar continuous distribution, it gives the area under the probability density function from negative infinity to . Cumulative distribution functions are also used to specify the distribution of multivariate random variables.
Definition edit
The cumulative distribution function of a real-valued random variable is the function given by[2]: p. 77
|
(Eq.1) |

where the right-hand side represents the probability that the random variable takes on a value less than or equal to .
The probability that lies in the semi-closed interval , where , is therefore[2]: p. 84
![{\displaystyle (a,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6a6969e731af335df071e247ee7fb331cd1a57ae)

|
(Eq.2) |

In the definition above, the "less than or equal to" sign, "≤", is a convention, not a universally used one (e.g. Hungarian literature uses "<"), but the distinction is important for discrete distributions. The proper use of tables of the binomial and Poisson distributions depends upon this convention. Moreover, important formulas like Paul Lévy's inversion formula for the characteristic function also rely on the "less than or equal" formulation.
If treating several random variables etc. the corresponding letters are used as subscripts while, if treating only one, the subscript is usually omitted. It is conventional to use a capital for a cumulative distribution function, in contrast to the lower-case used for probability density functions and probability mass functions. This applies when discussing general distributions: some specific distributions have their own conventional notation, for example the normal distribution uses and instead of and , respectively.





The probability density function of a continuous random variable can be determined from the cumulative distribution function by differentiating[3] using the Fundamental Theorem of Calculus; i.e. given ,


The CDF of a continuous random variable can be expressed as the integral of its probability density function as follows:[2]: p. 86


In the case of a random variable which has distribution having a discrete component at a value ,


If is continuous at , this equals zero and there is no discrete component at .

Properties edit
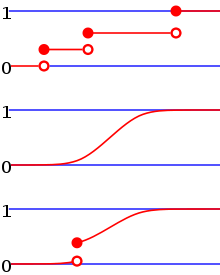

Every cumulative distribution function is non-decreasing[2]: p. 78 and right-continuous,[2]: p. 79 which makes it a càdlàg function. Furthermore,

Every function with these four properties is a CDF, i.e., for every such function, a random variable can be defined such that the function is the cumulative distribution function of that random variable.
If is a purely discrete random variable, then it attains values with probability , and the CDF of will be discontinuous at the points :




If the CDF of a real valued random variable is continuous, then is a continuous random variable; if furthermore is absolutely continuous, then there exists a Lebesgue-integrable function such that



If has finite L1-norm, that is, the expectation of is finite, then the expectation is given by the Riemann–Stieltjes integral

![{\displaystyle \mathbb {E} [X]=\int _{-\infty }^{\infty }tdF_{X}(t)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7b8b269c99751edd630ab22c36aac1ffde3a4110)





In particular, we have

Examples edit
As an example, suppose is uniformly distributed on the unit interval .
![{\displaystyle [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)
Then the CDF of is given by

Suppose instead that takes only the discrete values 0 and 1, with equal probability.
Then the CDF of is given by

Suppose is exponential distributed. Then the CDF of is given by

Here λ > 0 is the parameter of the distribution, often called the rate parameter.
Suppose is normal distributed. Then the CDF of is given by

Here the parameter is the mean or expectation of the distribution; and is its standard deviation.


A table of the CDF of the standard normal distribution is often used in statistical applications, where it is named the standard normal table, the unit normal table, or the Z table.
Suppose is binomial distributed. Then the CDF of is given by

Here is the probability of success and the function denotes the discrete probability distribution of the number of successes in a sequence of independent experiments, and is the "floor" under , i.e. the greatest integer less than or equal to .




Derived functions edit
Complementary cumulative distribution function (tail distribution) edit
Sometimes, it is useful to study the opposite question and ask how often the random variable is above a particular level. This is called the complementary cumulative distribution function (ccdf) or simply the tail distribution or exceedance, and is defined as

This has applications in statistical hypothesis testing, for example, because the one-sided p-value is the probability of observing a test statistic at least as extreme as the one observed. Thus, provided that the test statistic, T, has a continuous distribution, the one-sided p-value is simply given by the ccdf: for an observed value of the test statistic


In survival analysis, is called the survival function and denoted , while the term reliability function is common in engineering.


- Properties
- For a non-negative continuous random variable having an expectation, Markov's inequality states that[4]
- As , and in fact provided that is finite.
Proof:[citation needed]
Assuming has a density function , for anyThen, on recognizingand rearranging terms,as claimed. - For a random variable having an expectation, and for a non-negative random variable the second term is 0.
If the random variable can only take non-negative integer values, this is equivalent to










Folded cumulative distribution edit
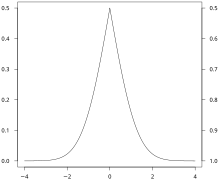
While the plot of a cumulative distribution often has an S-like shape, an alternative illustration is the folded cumulative distribution or mountain plot, which folds the top half of the graph over,[5][6] that is

where denotes the indicator function and the second summand is the survivor function, thus using two scales, one for the upslope and another for the downslope. This form of illustration emphasises the median, dispersion (specifically, the mean absolute deviation from the median[7]) and skewness of the distribution or of the empirical results.

Inverse distribution function (quantile function) edit
If the CDF F is strictly increasing and continuous then is the unique real number such that . This defines the inverse distribution function or quantile function.
![{\displaystyle F^{-1}(p),p\in [0,1],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b89fe1b58ff06ad5647ba178886bb6704d8da846)

Some distributions do not have a unique inverse (for example if for all , causing to be constant). In this case, one may use the generalized inverse distribution function, which is defined as


![{\displaystyle F^{-1}(p)=\inf\{x\in \mathbb {R} :F(x)\geq p\},\quad \forall p\in [0,1].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d7f8d361fa630d92216975a16f12756a137f3d84)
- Example 1: The median is .
- Example 2: Put . Then we call the 95th percentile.



Some useful properties of the inverse cdf (which are also preserved in the definition of the generalized inverse distribution function) are:
- is nondecreasing[8]
- if and only if
- If has a distribution then is distributed as . This is used in random number generation using the inverse transform sampling-method.
- If is a collection of independent -distributed random variables defined on the same sample space, then there exist random variables such that is distributed as and with probability 1 for all .[citation needed]






![{\displaystyle U[0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ef4a82b2a883d751cf53e5ac11ea12b9e36298f0)





The inverse of the cdf can be used to translate results obtained for the uniform distribution to other distributions.
Empirical distribution function edit
The empirical distribution function is an estimate of the cumulative distribution function that generated the points in the sample. It converges with probability 1 to that underlying distribution. A number of results exist to quantify the rate of convergence of the empirical distribution function to the underlying cumulative distribution function.[9]
Multivariate case edit
Definition for two random variables edit
When dealing simultaneously with more than one random variable the joint cumulative distribution function can also be defined. For example, for a pair of random variables , the joint CDF is given by[2]: p. 89


|
(Eq.3) |

where the right-hand side represents the probability that the random variable takes on a value less than or equal to and that takes on a value less than or equal to .

Example of joint cumulative distribution function:
For two continuous variables X and Y:

For two discrete random variables, it is beneficial to generate a table of probabilities and address the cumulative probability for each potential range of X and Y, and here is the example:[10]
given the joint probability mass function in tabular form, determine the joint cumulative distribution function.
| Y = 2 | Y = 4 | Y = 6 | Y = 8 | |
| X = 1 | 0 | 0.1 | 0 | 0.1 |
| X = 3 | 0 | 0 | 0.2 | 0 |
| X = 5 | 0.3 | 0 | 0 | 0.15 |
| X = 7 | 0 | 0 | 0.15 | 0 |
Solution: using the given table of probabilities for each potential range of X and Y, the joint cumulative distribution function may be constructed in tabular form:
| Y < 2 | Y ≤ 2 | Y ≤ 4 | Y ≤ 6 | Y ≤ 8 | |
| X < 1 | 0 | 0 | 0 | 0 | 0 |
| X ≤ 1 | 0 | 0 | 0.1 | 0.1 | 0.2 |
| X ≤ 3 | 0 | 0 | 0.1 | 0.3 | 0.4 |
| X ≤ 5 | 0 | 0.3 | 0.4 | 0.6 | 0.85 |
| X ≤ 7 | 0 | 0.3 | 0.4 | 0.75 | 1 |
Definition for more than two random variables edit
For random variables , the joint CDF is given by



|
(Eq.4) |

Interpreting the random variables as a random vector yields a shorter notation:


Properties edit
Every multivariate CDF is:
- Monotonically non-decreasing for each of its variables,
- Right-continuous in each of its variables,


Not every function satisfying the above four properties is a multivariate CDF, unlike in the single dimension case. For example, let for or or and let otherwise. It is easy to see that the above conditions are met, and yet is not a CDF since if it was, then as explained below.






The probability that a point belongs to a hyperrectangle is analogous to the 1-dimensional case:[11]

Complex case edit
Complex random variable edit
The generalization of the cumulative distribution function from real to complex random variables is not obvious because expressions of the form make no sense. However expressions of the form make sense. Therefore, we define the cumulative distribution of a complex random variables via the joint distribution of their real and imaginary parts:



Complex random vector edit
Generalization of Eq.4 yields


Use in statistical analysis edit
The concept of the cumulative distribution function makes an explicit appearance in statistical analysis in two (similar) ways. Cumulative frequency analysis is the analysis of the frequency of occurrence of values of a phenomenon less than a reference value. The empirical distribution function is a formal direct estimate of the cumulative distribution function for which simple statistical properties can be derived and which can form the basis of various statistical hypothesis tests. Such tests can assess whether there is evidence against a sample of data having arisen from a given distribution, or evidence against two samples of data having arisen from the same (unknown) population distribution.
Kolmogorov–Smirnov and Kuiper's tests edit
The Kolmogorov–Smirnov test is based on cumulative distribution functions and can be used to test to see whether two empirical distributions are different or whether an empirical distribution is different from an ideal distribution. The closely related Kuiper's test is useful if the domain of the distribution is cyclic as in day of the week. For instance Kuiper's test might be used to see if the number of tornadoes varies during the year or if sales of a product vary by day of the week or day of the month.
See also edit
- Descriptive statistics
- Distribution fitting
- Ogive (statistics)
- Modified half-normal distribution[12] with the pdf on is given as , where denotes the Fox–Wright Psi function.



References edit
- ^ Deisenroth, Marc Peter; Faisal, A. Aldo; Ong, Cheng Soon (2020). Mathematics for Machine Learning. Cambridge University Press. p. 181. ISBN 9781108455145.
- ^ a b c d e f Park, Kun Il (2018). Fundamentals of Probability and Stochastic Processes with Applications to Communications. Springer. ISBN 978-3-319-68074-3.
- ^ Montgomery, Douglas C.; Runger, George C. (2003). Applied Statistics and Probability for Engineers (PDF). John Wiley & Sons, Inc. p. 104. ISBN 0-471-20454-4. Archived (PDF) from the original on 2012-07-30.
- ^ Zwillinger, Daniel; Kokoska, Stephen (2010). CRC Standard Probability and Statistics Tables and Formulae. CRC Press. p. 49. ISBN 978-1-58488-059-2.
- ^ Gentle, J.E. (2009). Computational Statistics. Springer. ISBN 978-0-387-98145-1. Retrieved 2010-08-06.[page needed]
- ^ Monti, K. L. (1995). "Folded Empirical Distribution Function Curves (Mountain Plots)". The American Statistician. 49 (4): 342–345. doi:10.2307/2684570. JSTOR 2684570.
- ^ Xue, J. H.; Titterington, D. M. (2011). "The p-folded cumulative distribution function and the mean absolute deviation from the p-quantile" (PDF). Statistics & Probability Letters. 81 (8): 1179–1182. doi:10.1016/j.spl.2011.03.014.
- ^ Chan, Stanley H. (2021). Introduction to Probability for Data Science. Michigan Publishing. p. 18. ISBN 978-1-60785-746-4.
- ^ Hesse, C. (1990). "Rates of convergence for the empirical distribution function and the empirical characteristic function of a broad class of linear processes". Journal of Multivariate Analysis. 35 (2): 186–202. doi:10.1016/0047-259X(90)90024-C.
- ^ "Joint Cumulative Distribution Function (CDF)". math.info. Retrieved 2019-12-11.
- ^ "Archived copy" (PDF). www.math.wustl.edu. Archived from the original (PDF) on 22 February 2016. Retrieved 13 January 2022.
{{cite web}}: CS1 maint: archived copy as title (link) - ^ Sun, Jingchao; Kong, Maiying; Pal, Subhadip (22 June 2021). "The Modified-Half-Normal distribution: Properties and an efficient sampling scheme". Communications in Statistics - Theory and Methods. 52 (5): 1591–1613. doi:10.1080/03610926.2021.1934700. ISSN 0361-0926. S2CID 237919587.
External links edit
 Media related to Cumulative distribution functions at Wikimedia Commons
Media related to Cumulative distribution functions at Wikimedia Commons