


Summary
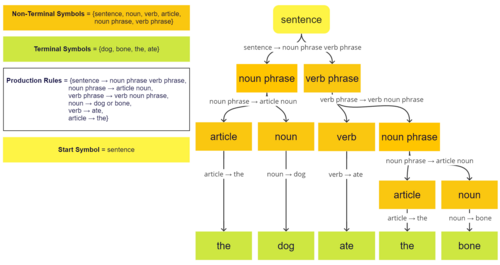
A formal grammar describes which strings from an alphabet of a formal language are valid according to the language's syntax. A grammar does not describe the meaning of the strings or what can be done with them in whatever context—only their form. A formal grammar is defined as a set of production rules for such strings in a formal language.
Formal language theory, the discipline that studies formal grammars and languages, is a branch of applied mathematics. Its applications are found in theoretical computer science, theoretical linguistics, formal semantics, mathematical logic, and other areas.
A formal grammar is a set of rules for rewriting strings, along with a "start symbol" from which rewriting starts. Therefore, a grammar is usually thought of as a language generator. However, it can also sometimes be used as the basis for a "recognizer"—a function in computing that determines whether a given string belongs to the language or is grammatically incorrect. To describe such recognizers, formal language theory uses separate formalisms, known as automata theory. One of the interesting results of automata theory is that it is not possible to design a recognizer for certain formal languages.[1] Parsing is the process of recognizing an utterance (a string in natural languages) by breaking it down to a set of symbols and analyzing each one against the grammar of the language. Most languages have the meanings of their utterances structured according to their syntax—a practice known as compositional semantics. As a result, the first step to describing the meaning of an utterance in language is to break it down part by part and look at its analyzed form (known as its parse tree in computer science, and as its deep structure in generative grammar).
Introductory example edit
A grammar mainly consists of a set of production rules, rewriting rules for transforming strings. Each rule specifies a replacement of a particular string (its left-hand side) with another (its right-hand side). A rule can be applied to each string that contains its left-hand side and produces a string in which an occurrence of that left-hand side has been replaced with its right-hand side.
Unlike a semi-Thue system, which is wholly defined by these rules, a grammar further distinguishes between two kinds of symbols: nonterminal and terminal symbols; each left-hand side must contain at least one nonterminal symbol. It also distinguishes a special nonterminal symbol, called the start symbol.
The language generated by the grammar is defined to be the set of all strings without any nonterminal symbols that can be generated from the string consisting of a single start symbol by (possibly repeated) application of its rules in whatever way possible. If there are essentially different ways of generating the same single string, the grammar is said to be ambiguous.
In the following examples, the terminal symbols are a and b, and the start symbol is S.
Example 1 edit
Suppose we have the following production rules:
- 1.
- 2.


then we start with S, and can choose a rule to apply to it. If we choose rule 1, we obtain the string aSb. If we then choose rule 1 again, we replace S with aSb and obtain the string aaSbb. If we now choose rule 2, we replace S with ba and obtain the string aababb, and are done. We can write this series of choices more briefly, using symbols: .

The language of the grammar is the infinite set , where is repeated times (and in particular represents the number of times production rule 1 has been applied). This grammar is context-free (only single nonterminals appear as left-hand sides) and unambiguous.





Examples 2 and 3 edit
Suppose the rules are these instead:
- 1.
- 2.
- 3.



This grammar is not context-free due to rule 3 and it is ambiguous due to the multiple ways in which rule 2 can be used to generate sequences of s.

However, the language it generates is simply the set of all nonempty strings consisting of s and/or s. This is easy to see: to generate a from an , use rule 2 twice to generate , then rule 1 twice and rule 3 once to produce . This means we can generate arbitrary nonempty sequences of s and then replace each of them with or as we please.


That same language can alternatively be generated by a context-free, nonambiguous grammar; for instance, the regular grammar with rules
- 1.
- 2.
- 3.
- 4.



Formal definition edit
The syntax of grammars edit
In the classic formalization of generative grammars first proposed by Noam Chomsky in the 1950s,[2][3] a grammar G consists of the following components:
- A finite set N of nonterminal symbols, that is disjoint with the strings formed from G.
- A finite set of terminal symbols that is disjoint from N.
- A finite set P of production rules, each rule of the form

- where is the Kleene star operator and denotes set union. That is, each production rule maps from one string of symbols to another, where the first string (the "head") contains an arbitrary number of symbols provided at least one of them is a nonterminal. In the case that the second string (the "body") consists solely of the empty string—i.e., that it contains no symbols at all—it may be denoted with a special notation (often , e or ) in order to avoid confusion.





- A distinguished symbol that is the start symbol, also called the sentence symbol.

A grammar is formally defined as the tuple . Such a formal grammar is often called a rewriting system or a phrase structure grammar in the literature.[4][5]

Some mathematical constructs regarding formal grammars edit
The operation of a grammar can be defined in terms of relations on strings:
- Given a grammar , the binary relation (pronounced as "G derives in one step") on strings in is defined by:
- the relation (pronounced as G derives in zero or more steps) is defined as the reflexive transitive closure of
- a sentential form is a member of that can be derived in a finite number of steps from the start symbol ; that is, a sentential form is a member of . A sentential form that contains no nonterminal symbols (i.e. is a member of ) is called a sentence.[6]
- the language of , denoted as , is defined as the set of sentences built by .









The grammar is effectively the semi-Thue system , rewriting strings in exactly the same way; the only difference is in that we distinguish specific nonterminal symbols, which must be rewritten in rewrite rules, and are only interested in rewritings from the designated start symbol to strings without nonterminal symbols.

Example edit
For these examples, formal languages are specified using set-builder notation.
Consider the grammar where , , is the start symbol, and consists of the following production rules:



- 1.
- 2.
- 3.
- 4.




This grammar defines the language where denotes a string of n consecutive 's. Thus, the language is the set of strings that consist of 1 or more 's, followed by the same number of 's, followed by the same number of 's.



Some examples of the derivation of strings in are:




- (On notation: reads "String P generates string Q by means of production i", and the generated part is each time indicated in bold type.)

The Chomsky hierarchy edit
When Noam Chomsky first formalized generative grammars in 1956,[2] he classified them into types now known as the Chomsky hierarchy. The difference between these types is that they have increasingly strict production rules and can therefore express fewer formal languages. Two important types are context-free grammars (Type 2) and regular grammars (Type 3). The languages that can be described with such a grammar are called context-free languages and regular languages, respectively. Although much less powerful than unrestricted grammars (Type 0), which can in fact express any language that can be accepted by a Turing machine, these two restricted types of grammars are most often used because parsers for them can be efficiently implemented.[7] For example, all regular languages can be recognized by a finite-state machine, and for useful subsets of context-free grammars there are well-known algorithms to generate efficient LL parsers and LR parsers to recognize the corresponding languages those grammars generate.
Context-free grammars edit
A context-free grammar is a grammar in which the left-hand side of each production rule consists of only a single nonterminal symbol. This restriction is non-trivial; not all languages can be generated by context-free grammars. Those that can are called context-free languages.
The language defined above is not a context-free language, and this can be strictly proven using the pumping lemma for context-free languages, but for example the language (at least 1 followed by the same number of 's) is context-free, as it can be defined by the grammar with , , the start symbol, and the following production rules:




- 1.
- 2.

A context-free language can be recognized in time (see Big O notation) by an algorithm such as Earley's recogniser. That is, for every context-free language, a machine can be built that takes a string as input and determines in time whether the string is a member of the language, where is the length of the string.[8] Deterministic context-free languages is a subset of context-free languages that can be recognized in linear time.[9] There exist various algorithms that target either this set of languages or some subset of it.

Regular grammars edit
In regular grammars, the left hand side is again only a single nonterminal symbol, but now the right-hand side is also restricted. The right side may be the empty string, or a single terminal symbol, or a single terminal symbol followed by a nonterminal symbol, but nothing else. (Sometimes a broader definition is used: one can allow longer strings of terminals or single nonterminals without anything else, making languages easier to denote while still defining the same class of languages.)
The language defined above is not regular, but the language (at least 1 followed by at least 1 , where the numbers may be different) is, as it can be defined by the grammar with , , the start symbol, and the following production rules:








All languages generated by a regular grammar can be recognized in time by a finite-state machine. Although in practice, regular grammars are commonly expressed using regular expressions, some forms of regular expression used in practice do not strictly generate the regular languages and do not show linear recognitional performance due to those deviations.

Other forms of generative grammars edit
Many extensions and variations on Chomsky's original hierarchy of formal grammars have been developed, both by linguists and by computer scientists, usually either in order to increase their expressive power or in order to make them easier to analyze or parse. Some forms of grammars developed include:
- Tree-adjoining grammars increase the expressiveness of conventional generative grammars by allowing rewrite rules to operate on parse trees instead of just strings.[10]
- Affix grammars[11] and attribute grammars[12][13] allow rewrite rules to be augmented with semantic attributes and operations, useful both for increasing grammar expressiveness and for constructing practical language translation tools.
Recursive grammars edit
A recursive grammar is a grammar that contains production rules that are recursive. For example, a grammar for a context-free language is left-recursive if there exists a non-terminal symbol A that can be put through the production rules to produce a string with A as the leftmost symbol.[14] An example of recursive grammar is a clause within a sentence separated by two commas.[15] All types of grammars in the Chomsky hierarchy can be recursive.
Analytic grammars edit
Though there is a tremendous body of literature on parsing algorithms, most of these algorithms assume that the language to be parsed is initially described by means of a generative formal grammar, and that the goal is to transform this generative grammar into a working parser. Strictly speaking, a generative grammar does not in any way correspond to the algorithm used to parse a language, and various algorithms have different restrictions on the form of production rules that are considered well-formed.
An alternative approach is to formalize the language in terms of an analytic grammar in the first place, which more directly corresponds to the structure and semantics of a parser for the language. Examples of analytic grammar formalisms include the following:
- Top-down parsing language (TDPL): a highly minimalist analytic grammar formalism developed in the early 1970s to study the behavior of top-down parsers.[16]
- Link grammars: a form of analytic grammar designed for linguistics, which derives syntactic structure by examining the positional relationships between pairs of words.[17][18]
- Parsing expression grammars (PEGs): a more recent generalization of TDPL designed around the practical expressiveness needs of programming language and compiler writers.[19]
See also edit
References edit
- ^ Meduna, Alexander (2014), Formal Languages and Computation: Models and Their Applications, CRC Press, p. 233, ISBN 9781466513457. For more on this subject, see undecidable problem.
- ^ a b Chomsky, Noam (Sep 1956). "Three models for the description of language". IRE Transactions on Information Theory. 2 (3): 113–124. doi:10.1109/TIT.1956.1056813. S2CID 19519474.
- ^ Chomsky, Noam (1957). Syntactic Structures. The Hague: Mouton.
- ^ Ginsburg, Seymour (1975). Algebraic and automata theoretic properties of formal languages. North-Holland. pp. 8–9. ISBN 978-0-7204-2506-2.
- ^ Harrison, Michael A. (1978). Introduction to Formal Language Theory. Reading, Mass.: Addison-Wesley Publishing Company. p. 13. ISBN 978-0-201-02955-0.
- ^ Sentential Forms Archived 2019-11-13 at the Wayback Machine, Context-Free Grammars, David Matuszek
- ^ Grune, Dick & Jacobs, Ceriel H., Parsing Techniques – A Practical Guide, Ellis Horwood, England, 1990.
- ^ Earley, Jay, "An Efficient Context-Free Parsing Algorithm Archived 2020-05-19 at the Wayback Machine," Communications of the ACM, Vol. 13 No. 2, pp. 94-102, February 1970.
- ^ Knuth, D. E. (July 1965). "On the translation of languages from left to right". Information and Control. 8 (6): 607–639. doi:10.1016/S0019-9958(65)90426-2.
- ^ Joshi, Aravind K., et al., "Tree Adjunct Grammars," Journal of Computer Systems Science, Vol. 10 No. 1, pp. 136-163, 1975.
- ^ Koster , Cornelis H. A., "Affix Grammars," in ALGOL 68 Implementation, North Holland Publishing Company, Amsterdam, p. 95-109, 1971.
- ^ Knuth, Donald E., "Semantics of Context-Free Languages," Mathematical Systems Theory, Vol. 2 No. 2, pp. 127-145, 1968.
- ^ Knuth, Donald E., "Semantics of Context-Free Languages (correction)," Mathematical Systems Theory, Vol. 5 No. 1, pp 95-96, 1971.
- ^ Notes on Formal Language Theory and Parsing Archived 2017-08-28 at the Wayback Machine, James Power, Department of Computer Science National University of Ireland, Maynooth Maynooth, Co. Kildare, Ireland.JPR02
- ^ Borenstein, Seth (April 27, 2006). "Songbirds grasp grammar, too". Northwest Herald. p. 2 – via Newspapers.com.
- ^ Birman, Alexander, The TMG Recognition Schema, Doctoral thesis, Princeton University, Dept. of Electrical Engineering, February 1970.
- ^ Sleator, Daniel D. & Temperly, Davy, "Parsing English with a Link Grammar," Technical Report CMU-CS-91-196, Carnegie Mellon University Computer Science, 1991.
- ^ Sleator, Daniel D. & Temperly, Davy, "Parsing English with a Link Grammar," Third International Workshop on Parsing Technologies, 1993. (Revised version of above report.)
- ^ Ford, Bryan, Packrat Parsing: a Practical Linear-Time Algorithm with Backtracking, Master’s thesis, Massachusetts Institute of Technology, Sept. 2002.