


Summary
A mean is a numeric quantity representing the center of a collection of numbers and is intermediate to the extreme values of a set of numbers.[1] There are several kinds of means (or "measures of central tendency") in mathematics, especially in statistics. Each attempts to summarize or typify a given group of data, illustrating the magnitude and sign of the data set. Which of these measures is most illuminating depends on what is being measured, and on context and purpose.
The arithmetic mean, also known as "arithmetic average", is the sum of the values divided by the number of values. The arithmetic mean of a set of numbers x1, x2, ..., xn is typically denoted using an overhead bar, .[note 1] If the numbers are from observing a sample of a larger group, the arithmetic mean is termed the sample mean () to distinguish it from the group mean (or expected value) of the underlying distribution, denoted or .[note 2][2]



Outside probability and statistics, a wide range of other notions of mean are often used in geometry and mathematical analysis; examples are given below.
Types of means edit
Pythagorean means edit
Arithmetic mean (AM) edit
The arithmetic mean (or simply mean or average) of a list of numbers, is the sum of all of the numbers divided by the number of numbers. Similarly, the mean of a sample , usually denoted by , is the sum of the sampled values divided by the number of items in the sample.


For example, the arithmetic mean of five values: 4, 36, 45, 50, 75 is:

Geometric mean (GM) edit
The geometric mean is an average that is useful for sets of positive numbers, that are interpreted according to their product (as is the case with rates of growth) and not their sum (as is the case with the arithmetic mean):

For example, the geometric mean of five values: 4, 36, 45, 50, 75 is:
![{\displaystyle (4\times 36\times 45\times 50\times 75)^{\frac {1}{5}}={\sqrt[{5}]{24\;300\;000}}=30.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3b516046ef2a7b8b23301b7ab228cec73f38e062)
Harmonic mean (HM) edit
The harmonic mean is an average which is useful for sets of numbers which are defined in relation to some unit, as in the case of speed (i.e., distance per unit of time):

For example, the harmonic mean of the five values: 4, 36, 45, 50, 75 is

If we have five pumps that can empty a tank of a certain size in respectively 4, 36, 45, 50, and 75 minutes, then the harmonic mean of tells us that these five different pumps working together will pump at the same rate as much as five pumps that can each empty the tank in minutes.

Relationship between AM, GM, and HM edit
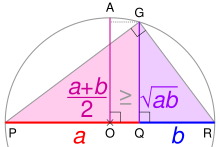
PR is the diameter of a circle centered on O; its radius AO is the arithmetic mean of a and b. Using the geometric mean theorem, triangle PGR's altitude GQ is the geometric mean. For any ratio a:b, AO ≥ GQ.
AM, GM, and HM satisfy these inequalities:

Equality holds if all the elements of the given sample are equal.
Statistical location edit
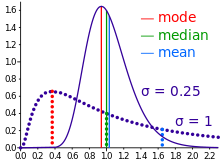
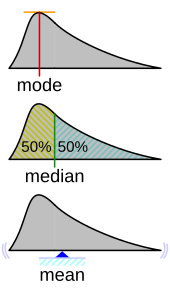
In descriptive statistics, the mean may be confused with the median, mode or mid-range, as any of these may incorrectly be called an "average" (more formally, a measure of central tendency). The mean of a set of observations is the arithmetic average of the values; however, for skewed distributions, the mean is not necessarily the same as the middle value (median), or the most likely value (mode). For example, mean income is typically skewed upwards by a small number of people with very large incomes, so that the majority have an income lower than the mean. By contrast, the median income is the level at which half the population is below and half is above. The mode income is the most likely income and favors the larger number of people with lower incomes. While the median and mode are often more intuitive measures for such skewed data, many skewed distributions are in fact best described by their mean, including the exponential and Poisson distributions.
Mean of a probability distribution edit
The mean of a probability distribution is the long-run arithmetic average value of a random variable having that distribution. If the random variable is denoted by , then the mean is also known as the expected value of (denoted ). For a discrete probability distribution, the mean is given by , where the sum is taken over all possible values of the random variable and is the probability mass function. For a continuous distribution, the mean is , where is the probability density function.[5] In all cases, including those in which the distribution is neither discrete nor continuous, the mean is the Lebesgue integral of the random variable with respect to its probability measure. The mean need not exist or be finite; for some probability distributions the mean is infinite (+∞ or −∞), while for others the mean is undefined.






Generalized means edit
Power mean edit
The generalized mean, also known as the power mean or Hölder mean, is an abstraction of the quadratic, arithmetic, geometric, and harmonic means. It is defined for a set of n positive numbers xi by

By choosing different values for the parameter m, the following types of means are obtained:







f-mean edit
This can be generalized further as the generalized f-mean

and again a suitable choice of an invertible f will give




Weighted arithmetic mean edit
The weighted arithmetic mean (or weighted average) is used if one wants to combine average values from different sized samples of the same population:

Where and are the mean and size of sample respectively. In other applications, they represent a measure for the reliability of the influence upon the mean by the respective values.



Truncated mean edit
Sometimes, a set of numbers might contain outliers (i.e., data values which are much lower or much higher than the others). Often, outliers are erroneous data caused by artifacts. In this case, one can use a truncated mean. It involves discarding given parts of the data at the top or the bottom end, typically an equal amount at each end and then taking the arithmetic mean of the remaining data. The number of values removed is indicated as a percentage of the total number of values.
Interquartile mean edit
The interquartile mean is a specific example of a truncated mean. It is simply the arithmetic mean after removing the lowest and the highest quarter of values.

assuming the values have been ordered, so is simply a specific example of a weighted mean for a specific set of weights.
Mean of a function edit
In some circumstances, mathematicians may calculate a mean of an infinite (or even an uncountable) set of values. This can happen when calculating the mean value of a function . Intuitively, a mean of a function can be thought of as calculating the area under a section of a curve, and then dividing by the length of that section. This can be done crudely by counting squares on graph paper, or more precisely by integration. The integration formula is written as:


In this case, care must be taken to make sure that the integral converges. But the mean may be finite even if the function itself tends to infinity at some points.
Mean of angles and cyclical quantities edit
Angles, times of day, and other cyclical quantities require modular arithmetic to add and otherwise combine numbers. In all these situations, there will not be a unique mean. For example, the times an hour before and after midnight are equidistant to both midnight and noon. It is also possible that no mean exists. Consider a color wheel—there is no mean to the set of all colors. In these situations, you must decide which mean is most useful. You can do this by adjusting the values before averaging, or by using a specialized approach for the mean of circular quantities.
Fréchet mean edit
The Fréchet mean gives a manner for determining the "center" of a mass distribution on a surface or, more generally, Riemannian manifold. Unlike many other means, the Fréchet mean is defined on a space whose elements cannot necessarily be added together or multiplied by scalars. It is sometimes also known as the Karcher mean (named after Hermann Karcher).
Triangular sets edit
In geometry, there are thousands of different definitions for the center of a triangle that can all be interpreted as the mean of a triangular set of points in the plane.[citation needed]
Swanson's rule edit
This is an approximation to the mean for a moderately skewed distribution.[6] It is used in hydrocarbon exploration and is defined as:

where , and are the 10th, 50th and 90th percentiles of the distribution, respctively.



Other means edit
- Arithmetic-geometric mean
- Arithmetic-harmonic mean
- Cesàro mean
- Chisini mean
- Contraharmonic mean
- Elementary symmetric mean
- Geometric-harmonic mean
- Grand mean
- Heinz mean
- Heronian mean
- Identric mean
- Lehmer mean
- Logarithmic mean
- Moving average
- Neuman–Sándor mean
- Quasi-arithmetic mean
- Root mean square (quadratic mean)
- Rényi's entropy (a generalized f-mean)
- Spherical mean
- Stolarsky mean
- Weighted geometric mean
- Weighted harmonic mean
See also edit
Notes edit
References edit
- ^ "Mean | Definition, Formula, & Facts | Britannica". www.britannica.com. 2023-09-22. Retrieved 2023-10-27.
- ^ Underhill, L.G.; Bradfield d. (1998) Introstat, Juta and Company Ltd. ISBN 0-7021-3838-X p. 181
- ^ a b c "Mean | mathematics". Encyclopedia Britannica. Retrieved 2020-08-21.
- ^ "AP Statistics Review - Density Curves and the Normal Distributions". Archived from the original on 2 April 2015. Retrieved 16 March 2015.
- ^ Weisstein, Eric W. "Population Mean". mathworld.wolfram.com. Retrieved 2020-08-21.
- ^ Hurst A, Brown GC, Swanson RI (2000) Swanson's 30-40-30 Rule. American Association of Petroleum Geologists Bulletin 84(12) 1883-1891