


Summary
Nonlinear mixed-effects models constitute a class of statistical models generalizing linear mixed-effects models. Like linear mixed-effects models, they are particularly useful in settings where there are multiple measurements within the same statistical units or when there are dependencies between measurements on related statistical units. Nonlinear mixed-effects models are applied in many fields including medicine, public health, pharmacology, and ecology.[1][2]
Definition edit
While any statistical model containing both fixed effects and random effects is an example of a nonlinear mixed-effects model, the most commonly used models are members of the class of nonlinear mixed-effects models for repeated measures[1]

where
- is the number of groups/subjects,
- is the number of observations for the th group/subject,
- is a real-valued differentiable function of a group-specific parameter vector and a covariate vector ,
- is modeled as a linear mixed-effects model where is a vector of fixed effects and is a vector of random effects associated with group , and
- is a random variable describing additive noise.










Estimation edit
When the model is only nonlinear in fixed effects and the random effects are Gaussian, maximum-likelihood estimation can be done using nonlinear least squares methods, although asymptotic properties of estimators and test statistics may differ from the conventional general linear model. In the more general setting, there exist several methods for doing maximum-likelihood estimation or maximum a posteriori estimation in certain classes of nonlinear mixed-effects models – typically under the assumption of normally distributed random variables. A popular approach is the Lindstrom-Bates algorithm[3] which relies on iteratively optimizing a nonlinear problem, locally linearizing the model around this optimum and then employing conventional methods from linear mixed-effects models to do maximum likelihood estimation. Stochastic approximation of the expectation-maximization algorithm gives an alternative approach for doing maximum-likelihood estimation.[4]
Applications edit
Example: Disease progression modeling edit
Nonlinear mixed-effects models have been used for modeling progression of disease.[5] In progressive disease, the temporal patterns of progression on outcome variables may follow a nonlinear temporal shape that is similar between patients. However, the stage of disease of an individual may not be known or only partially known from what can be measured. Therefore, a latent time variable that describe individual disease stage (i.e. where the patient is along the nonlinear mean curve) can be included in the model.
Example: Modeling cognitive decline in Alzheimer's disease edit

Alzheimer's disease is characterized by a progressive cognitive deterioration. However, patients may differ widely in cognitive ability and reserve, so cognitive testing at a single time point can often only be used to coarsely group individuals in different stages of disease. Now suppose we have a set of longitudinal cognitive data from individuals that are each categorized as having either normal cognition (CN), mild cognitive impairment (MCI) or dementia (DEM) at the baseline visit (time corresponding to measurement ). These longitudinal trajectories can be modeled using a nonlinear mixed effects model that allows differences in disease state based on baseline categorization:





where
- is a function that models the mean time-profile of cognitive decline whose shape is determined by the parameters ,
- represents observation time (e.g. time since baseline in the study),
- and are dummy variables that are 1 if individual has MCI or dementia at baseline and 0 otherwise,
- and are parameters that model the difference in disease progression of the MCI and dementia groups relative to the cognitively normal,
- is the difference in disease stage of individual relative to his/her baseline category, and
- is a random variable describing additive noise.








An example of such a model with an exponential mean function fitted to longitudinal measurements of the Alzheimer's Disease Assessment Scale-Cognitive Subscale (ADAS-Cog) is shown in the box. As shown, the inclusion of fixed effects of baseline categorization (MCI or dementia relative to normal cognition) and the random effect of individual continuous disease stage aligns the trajectories of cognitive deterioration to reveal a common pattern of cognitive decline.
Example: Growth analysis edit

Growth phenomena often follow nonlinear patters (e.g. logistic growth, exponential growth, and hyperbolic growth). Factors such as nutrient deficiency may both directly affect the measured outcome (e.g. organisms with lack of nutrients end up smaller), but possibly also timing (e.g. organisms with lack of nutrients grow at a slower pace). If a model fails to account for the differences in timing, the estimated population-level curves may smooth out finer details due to lack of synchronization between organisms. Nonlinear mixed-effects models enable simultaneous modeling of individual differences in growth outcomes and timing.
Example: Modeling human height edit
Models for estimating the mean curves of human height and weight as a function of age and the natural variation around the mean are used to create growth charts. The growth of children can however become desynchronized due to both genetic and environmental factors. For example, age at onset of puberty and its associated height spurt can vary several years between adolescents. Therefore, cross-sectional studies may underestimate the magnitude of the pubertal height spurt because age is not synchronized with biological development. The differences in biological development can be modeled using random effects that describe a mapping of observed age to a latent biological age using a so-called warping function . A simple nonlinear mixed-effects model with this structure is given by



where
- is a function that represents the height development of a typical child as a function of age. Its shape is determined by the parameters ,
- is the age of child corresponding to the height measurement ,
- is a warping function that maps age to biological development to synchronize. Its shape is determined by the random effects ,
- is a random variable describing additive variation (e.g. consistent differences in height between children and measurement noise).


There exists several methods and software packages for fitting such models. The so-called SITAR model[7] can fit such models using warping functions that are affine transformations of time (i.e. additive shifts in biological age and differences in rate of maturation), while the so-called pavpop model[6] can fit models with smoothly-varying warping functions. An example of the latter is shown in the box.
Example: Population Pharmacokinetic/pharmacodynamic modeling edit

PK/PD models for describing exposure-response relationships such as the Emax model can be formulated as nonlinear mixed-effects models.[8] The mixed-model approach allows modeling of both population level and individual differences in effects that have a nonlinear effect on the observed outcomes, for example the rate at which a compound is being metabolized or distributed in the body.
Example: COVID-19 epidemiological modeling edit
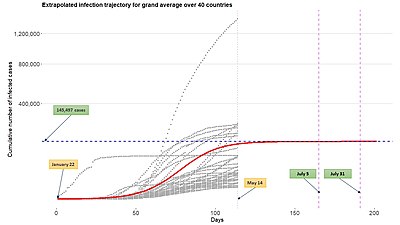
The platform of the nonlinear mixed effect models can be used to describe infection trajectories of subjects and understand some common features shared across the subjects. In epidemiological problems, subjects can be countries, states, or counties, etc. This can be particularly useful in estimating a future trend of the epidemic in an early stage of pendemic where nearly little information is known regarding the disease.[9]
Example: Prediction of oil production curve of shale oil wells at a new location with latent kriging edit

The eventual success of petroleum development projects relies on a large degree of well construction costs. As for unconventional oil and gas reservoirs, because of very low permeability, and a flow mechanism very different from that of conventional reservoirs, estimates for the well construction cost often contain high levels of uncertainty, and oil companies need to make heavy investment in the drilling and completion phase of the wells. The overall recent commercial success rate of horizontal wells in the United States is known to be 65%, which implies that only 2 out of 3 drilled wells will be commercially successful. For this reason, one of the crucial tasks of petroleum engineers is to quantify the uncertainty associated with oil or gas production from shale reservoirs, and further, to predict an approximated production behavior of a new well at a new location given specific completion data before actual drilling takes place to save a large degree of well construction costs.
The platform of the nonlinear mixed effect models can be extended to consider the spatial association by incorporating the geostatistical processes such as Gaussian process on the second stage of the model as follows:[10]





where
- is a function that models the mean time-profile of log-scaled oil production rate whose shape is determined by the parameters . The function is obtained from taking logarithm to the rate decline curve used in decline curve analysis,
- represents covariates obtained from the completion process of the hydraulic fracturing and horizontal directional drilling for the -th well,
- represents the spatial location (longitude, latitude) of the -th well,
- represents the Gaussian white noise with error variance (also called the nugget effect),
- represents the Gaussian process with Gaussian covariance function ,
- represents the horseshoe shrinkage prior.








The Gaussian process regressions used on the latent level (the second stage) eventually produce kriging predictors for the curve parameters that dictate the shape of the mean curve on the date level (the first level). As the kriging techniques have been employed in the latent level, this technique is called latent kriging. The right panels show the prediction results of the latent kriging method applied to the two test wells in the Eagle Ford Shale Reservoir of South Texas.

Bayesian nonlinear mixed-effects model edit

The framework of Bayesian hierarchical modeling is frequently used in diverse applications. Particularly, Bayesian nonlinear mixed-effects models have recently received significant attention. A basic version of the Bayesian nonlinear mixed-effects models is represented as the following three-stage:
Stage 1: Individual-Level Model

Stage 2: Population Model

Stage 3: Prior

Here, denotes the continuous response of the -th subject at the time point , and is the -th covariate of the -th subject. Parameters involved in the model are written in Greek letters. is a known function parameterized by the -dimensional vector . Typically, is a `nonlinear' function and describes the temporal trajectory of individuals. In the model, and describe within-individual variability and between-individual variability, respectively. If Stage 3: Prior is not considered, then the model reduces to a frequentist nonlinear mixed-effect model.






A central task in the application of the Bayesian nonlinear mixed-effect models is to evaluate the posterior density:



The panel on the right displays Bayesian research cycle using Bayesian nonlinear mixed-effects model.[12] A research cycle using the Bayesian nonlinear mixed-effects model comprises two steps: (a) standard research cycle and (b) Bayesian-specific workflow. Standard research cycle involves literature review, defining a problem and specifying the research question and hypothesis. Bayesian-specific workflow comprises three sub-steps: (b)–(i) formalizing prior distributions based on background knowledge and prior elicitation; (b)–(ii) determining the likelihood function based on a nonlinear function ; and (b)–(iii) making a posterior inference. The resulting posterior inference can be used to start a new research cycle.
See also edit
- Mixed model
- Fixed effects model
- Generalized linear mixed model
- Linear regression
- Mixed-design analysis of variance
- Multilevel model
- Random effects model
- Repeated measures design
References edit
- ^ a b Pinheiro, J; Bates, DM (2006). Mixed-effects models in S and S-PLUS. Statistics and Computing. New York: Springer Science & Business Media. doi:10.1007/b98882. ISBN 0-387-98957-9.
- ^ Bolker, BM (2008). Ecological models and data in R. Princeton University Press.
{{cite book}}:|website=ignored (help) - ^ Lindstrom, MJ; Bates, DM (1990). "Nonlinear mixed effects models for repeated measures data". Biometrics. 46 (3): 673–687. doi:10.2307/2532087. JSTOR 2532087. PMID 2242409.
- ^ Kuhn, E; Lavielle, M (2005). "Maximum likelihood estimation in nonlinear mixed effects models". Computational Statistics & Data Analysis. 49 (4): 1020–1038. doi:10.1016/j.csda.2004.07.002.
- ^ a b Raket, LL (2020). "Statistical disease progression modeling in Alzheimer's disease". Frontiers in Big Data. 3: 24. doi:10.3389/fdata.2020.00024. PMC 7931952. PMID 33693397. S2CID 221105601.
- ^ a b Raket LL, Sommer S, Markussen B (2014). "A nonlinear mixed-effects model for simultaneous smoothing and registration of functional data". Pattern Recognition Letters. 38: 1–7. doi:10.1016/j.patrec.2013.10.018.
- ^ Cole TJ, Donaldson MD, Ben-Shlomo Y (2010). "SITAR—a useful instrument for growth curve analysis". International Journal of Epidemiology. 39 (6): 1558–66. doi:10.1093/ije/dyq115. PMC 2992626. PMID 20647267. S2CID 17816715.
- ^ Jonsson, EN; Karlsson, MO; Wade, JR (2000). "Nonlinearity detection: advantages of nonlinear mixed-effects modeling". AAPS PharmSci. 2 (3): E32. doi:10.1208/ps020332. PMC 2761142. PMID 11741248.
- ^ Lee, Se Yoon; Lei, Bowen; Mallick, Bani (2020). "Estimation of COVID-19 spread curves integrating global data and borrowing information". PLOS ONE. 15 (7): e0236860. arXiv:2005.00662. doi:10.1371/journal.pone.0236860. PMC 7390340. PMID 32726361.
- ^ Lee, Se Yoon; Mallick, Bani (2021). "Bayesian Hierarchical Modeling: Application Towards Production Results in the Eagle Ford Shale of South Texas". Sankhya B. 84: 1–43. doi:10.1007/s13571-020-00245-8.
- ^ Lee, Se Yoon (2022). "Bayesian Nonlinear Models for Repeated Measurement Data: An Overview, Implementation, and Applications". Mathematics. 10 (6): 898. arXiv:2201.12430. doi:10.3390/math10060898.
- ^ Lee, Se Yoon (2022). "Bayesian Nonlinear Models for Repeated Measurement Data: An Overview, Implementation, and Applications". Mathematics. 10 (6): 898. arXiv:2201.12430. doi:10.3390/math10060898.