


Summary
In statistical signal processing, the goal of spectral density estimation (SDE) or simply spectral estimation is to estimate the spectral density (also known as the power spectral density) of a signal from a sequence of time samples of the signal.[1] Intuitively speaking, the spectral density characterizes the frequency content of the signal. One purpose of estimating the spectral density is to detect any periodicities in the data, by observing peaks at the frequencies corresponding to these periodicities.
Some SDE techniques assume that a signal is composed of a limited (usually small) number of generating frequencies plus noise and seek to find the location and intensity of the generated frequencies. Others make no assumption on the number of components and seek to estimate the whole generating spectrum.
Overview edit

Spectrum analysis, also referred to as frequency domain analysis or spectral density estimation, is the technical process of decomposing a complex signal into simpler parts. As described above, many physical processes are best described as a sum of many individual frequency components. Any process that quantifies the various amounts (e.g. amplitudes, powers, intensities) versus frequency (or phase) can be called spectrum analysis.
Spectrum analysis can be performed on the entire signal. Alternatively, a signal can be broken into short segments (sometimes called frames), and spectrum analysis may be applied to these individual segments. Periodic functions (such as ) are particularly well-suited for this sub-division. General mathematical techniques for analyzing non-periodic functions fall into the category of Fourier analysis.

The Fourier transform of a function produces a frequency spectrum which contains all of the information about the original signal, but in a different form. This means that the original function can be completely reconstructed (synthesized) by an inverse Fourier transform. For perfect reconstruction, the spectrum analyzer must preserve both the amplitude and phase of each frequency component. These two pieces of information can be represented as a 2-dimensional vector, as a complex number, or as magnitude (amplitude) and phase in polar coordinates (i.e., as a phasor). A common technique in signal processing is to consider the squared amplitude, or power; in this case the resulting plot is referred to as a power spectrum.
Because of reversibility, the Fourier transform is called a representation of the function, in terms of frequency instead of time; thus, it is a frequency domain representation. Linear operations that could be performed in the time domain have counterparts that can often be performed more easily in the frequency domain. Frequency analysis also simplifies the understanding and interpretation of the effects of various time-domain operations, both linear and non-linear. For instance, only non-linear or time-variant operations can create new frequencies in the frequency spectrum.
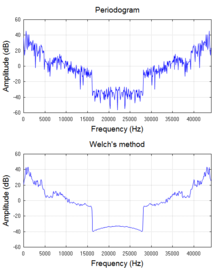
In practice, nearly all software and electronic devices that generate frequency spectra utilize a discrete Fourier transform (DFT), which operates on samples of the signal, and which provides a mathematical approximation to the full integral solution. The DFT is almost invariably implemented by an efficient algorithm called fast Fourier transform (FFT). The array of squared-magnitude components of a DFT is a type of power spectrum called periodogram, which is widely used for examining the frequency characteristics of noise-free functions such as filter impulse responses and window functions. But the periodogram does not provide processing-gain when applied to noiselike signals or even sinusoids at low signal-to-noise ratios. In other words, the variance of its spectral estimate at a given frequency does not decrease as the number of samples used in the computation increases. This can be mitigated by averaging over time (Welch's method[2]) or over frequency (smoothing). Welch's method is widely used for spectral density estimation (SDE). However, periodogram-based techniques introduce small biases that are unacceptable in some applications. So other alternatives are presented in the next section.
Techniques edit
Many other techniques for spectral estimation have been developed to mitigate the disadvantages of the basic periodogram. These techniques can generally be divided into non-parametric, parametric, and more recently semi-parametric (also called sparse) methods.[3] The non-parametric approaches explicitly estimate the covariance or the spectrum of the process without assuming that the process has any particular structure. Some of the most common estimators in use for basic applications (e.g. Welch's method) are non-parametric estimators closely related to the periodogram. By contrast, the parametric approaches assume that the underlying stationary stochastic process has a certain structure that can be described using a small number of parameters (for example, using an auto-regressive or moving-average model). In these approaches, the task is to estimate the parameters of the model that describes the stochastic process. When using the semi-parametric methods, the underlying process is modeled using a non-parametric framework, with the additional assumption that the number of non-zero components of the model is small (i.e., the model is sparse). Similar approaches may also be used for missing data recovery[4] as well as signal reconstruction.
Following is a partial list of spectral density estimation techniques:
- Non-parametric methods for which the signal samples can be unevenly spaced in time (records can be incomplete)
- Least-squares spectral analysis, based on least squares fitting to known frequencies
- Lomb–Scargle periodogram, an approximation of the Least-squares spectral analysis
- Non-uniform discrete Fourier transform
- Non-parametric methods for which the signal samples must be evenly spaced in time (records must be complete):
- Periodogram, the modulus squared of the discrete Fourier transform
- Bartlett's method is the average of the periodograms taken of multiple segments of the signal to reduce variance of the spectral density estimate
- Welch's method a windowed version of Bartlett's method that uses overlapping segments
- Multitaper is a periodogram-based method that uses multiple tapers, or windows, to form independent estimates of the spectral density to reduce variance of the spectral density estimate
- Singular spectrum analysis is a nonparametric method that uses a singular value decomposition of the covariance matrix to estimate the spectral density
- Short-time Fourier transform
- Critical filter is a nonparametric method based on information field theory that can deal with noise, incomplete data, and instrumental response functions
- Parametric techniques (an incomplete list):
- Autoregressive model (AR) estimation, which assumes that the nth sample is correlated with the previous p samples.
- Moving-average model (MA) estimation, which assumes that the nth sample is correlated with noise terms in the previous p samples.
- Autoregressive moving-average (ARMA) estimation, which generalizes the AR and MA models.
- MUltiple SIgnal Classification (MUSIC) is a popular superresolution method.
- Maximum entropy spectral estimation is an all-poles method useful for SDE when singular spectral features, such as sharp peaks, are expected.
- Semi-parametric techniques (an incomplete list):

Parametric estimation edit
In parametric spectral estimation, one assumes that the signal is modeled by a stationary process which has a spectral density function (SDF) that is a function of the frequency and parameters .[8] The estimation problem then becomes one of estimating these parameters.




The most common form of parametric SDF estimate uses as a model an autoregressive model of order .[8]: 392 A signal sequence obeying a zero mean process satisfies the equation



where the are fixed coefficients and is a white noise process with zero mean and innovation variance . The SDF for this process is




with the sampling time interval and the Nyquist frequency.


There are a number of approaches to estimating the parameters of the process and thus the spectral density:[8]: 452-453

- The Yule–Walker estimators are found by recursively solving the Yule–Walker equations for an process
- The Burg estimators are found by treating the Yule–Walker equations as a form of ordinary least squares problem. The Burg estimators are generally considered superior to the Yule–Walker estimators.[8]: 452 Burg associated these with maximum entropy spectral estimation.[9]
- The forward-backward least-squares estimators treat the process as a regression problem and solves that problem using forward-backward method. They are competitive with the Burg estimators.
- The maximum likelihood estimators estimate the parameters using a maximum likelihood approach. This involves a nonlinear optimization and is more complex than the first three.
Alternative parametric methods include fitting to a moving-average model (MA) and to a full autoregressive moving-average model (ARMA).
Frequency estimation edit
Frequency estimation is the process of estimating the frequency, amplitude, and phase-shift of a signal in the presence of noise given assumptions about the number of the components.[10] This contrasts with the general methods above, which do not make prior assumptions about the components.
Single tone edit
If one only wants to estimate the frequency of the single loudest pure-tone signal, one can use a pitch detection algorithm.
If the dominant frequency changes over time, then the problem becomes the estimation of the instantaneous frequency as defined in the time–frequency representation. Methods for instantaneous frequency estimation include those based on the Wigner–Ville distribution and higher order ambiguity functions.[11]
If one wants to know all the (possibly complex) frequency components of a received signal (including transmitted signal and noise), one uses a multiple-tone approach.
Multiple tones edit
A typical model for a signal consists of a sum of complex exponentials in the presence of white noise,


- .

The power spectral density of is composed of impulse functions in addition to the spectral density function due to noise.
The most common methods for frequency estimation involve identifying the noise subspace to extract these components. These methods are based on eigen decomposition of the autocorrelation matrix into a signal subspace and a noise subspace. After these subspaces are identified, a frequency estimation function is used to find the component frequencies from the noise subspace. The most popular methods of noise subspace based frequency estimation are Pisarenko's method, the multiple signal classification (MUSIC) method, the eigenvector method, and the minimum norm method.
- Pisarenko's method
- MUSIC
- ,
- Eigenvector method
- Minimum norm method




Example calculation edit
Suppose , from to is a time series (discrete time) with zero mean. Suppose that it is a sum of a finite number of periodic components (all frequencies are positive):




The variance of is, for a zero-mean function as above, given by

If these data were samples taken from an electrical signal, this would be its average power (power is energy per unit time, so it is analogous to variance if energy is analogous to the amplitude squared).
Now, for simplicity, suppose the signal extends infinitely in time, so we pass to the limit as If the average power is bounded, which is almost always the case in reality, then the following limit exists and is the variance of the data.


Again, for simplicity, we will pass to continuous time, and assume that the signal extends infinitely in time in both directions. Then these two formulas become

and

The root mean square of is , so the variance of is Hence, the contribution to the average power of coming from the component with frequency is All these contributions add up to the average power of







Then the power as a function of frequency is and its statistical cumulative distribution function will be



is a step function, monotonically non-decreasing. Its jumps occur at the frequencies of the periodic components of , and the value of each jump is the power or variance of that component.


The variance is the covariance of the data with itself. If we now consider the same data but with a lag of , we can take the covariance of with , and define this to be the autocorrelation function of the signal (or data) :




If it exists, it is an even function of If the average power is bounded, then exists everywhere, is finite, and is bounded by which is the average power or variance of the data.


It can be shown that can be decomposed into periodic components with the same periods as :

This is in fact the spectral decomposition of over the different frequencies, and is related to the distribution of power of over the frequencies: the amplitude of a frequency component of is its contribution to the average power of the signal.
The power spectrum of this example is not continuous, and therefore does not have a derivative, and therefore this signal does not have a power spectral density function. In general, the power spectrum will usually be the sum of two parts: a line spectrum such as in this example, which is not continuous and does not have a density function, and a residue, which is absolutely continuous and does have a density function.
See also edit
References edit
- ^ P Stoica and R Moses, Spectral Analysis of Signals, Prentice Hall, 2005.
- ^ Welch, P. D. (1967), "The use of Fast Fourier Transform for the estimation of power spectra: A method based on time averaging over short, modified periodograms", IEEE Transactions on Audio and Electroacoustics, AU-15 (2): 70–73, Bibcode:1967ITAE...15...70W, doi:10.1109/TAU.1967.1161901, S2CID 13900622
- ^ a b Stoica, Petre; Babu, Prabhu; Li, Jian (January 2011). "New Method of Sparse Parameter Estimation in Separable Models and Its Use for Spectral Analysis of Irregularly Sampled Data". IEEE Transactions on Signal Processing. 59 (1): 35–47. Bibcode:2011ITSP...59...35S. doi:10.1109/TSP.2010.2086452. ISSN 1053-587X. S2CID 15936187.
- ^ Stoica, Petre; Li, Jian; Ling, Jun; Cheng, Yubo (April 2009). "Missing data recovery via a nonparametric iterative adaptive approach". 2009 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE. pp. 3369–3372. doi:10.1109/icassp.2009.4960347. ISBN 978-1-4244-2353-8.
- ^ Sward, Johan; Adalbjornsson, Stefan Ingi; Jakobsson, Andreas (March 2017). "A generalization of the sparse iterative covariance-based estimator". 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE. pp. 3954–3958. doi:10.1109/icassp.2017.7952898. ISBN 978-1-5090-4117-6. S2CID 5640068.
- ^ Yardibi, Tarik; Li, Jian; Stoica, Petre; Xue, Ming; Baggeroer, Arthur B. (January 2010). "Source Localization and Sensing: A Nonparametric Iterative Adaptive Approach Based on Weighted Least Squares". IEEE Transactions on Aerospace and Electronic Systems. 46 (1): 425–443. Bibcode:2010ITAES..46..425Y. doi:10.1109/TAES.2010.5417172. hdl:1721.1/59588. ISSN 0018-9251. S2CID 18834345.
- ^ Panahi, Ashkan; Viberg, Mats (February 2011). "On the resolution of the LASSO-based DOA estimation method". 2011 International ITG Workshop on Smart Antennas. IEEE. pp. 1–5. doi:10.1109/wsa.2011.5741938. ISBN 978-1-61284-075-8. S2CID 7013162.
- ^ a b c d Percival, Donald B.; Walden, Andrew T. (1992). Spectral Analysis for Physical Applications. Cambridge University Press. ISBN 9780521435413.
- ^ Burg, J.P. (1967) "Maximum Entropy Spectral Analysis", Proceedings of the 37th Meeting of the Society of Exploration Geophysicists, Oklahoma City, Oklahoma.
- ^ Hayes, Monson H., Statistical Digital Signal Processing and Modeling, John Wiley & Sons, Inc., 1996. ISBN 0-471-59431-8.
- ^ Lerga, Jonatan. "Overview of Signal Instantaneous Frequency Estimation Methods" (PDF). University of Rijeka. Retrieved 22 March 2014.
Further reading edit
- Porat, B. (1994). Digital Processing of Random Signals: Theory & Methods. Prentice Hall. ISBN 978-0-13-063751-2.
- Priestley, M.B. (1991). Spectral Analysis and Time Series. Academic Press. ISBN 978-0-12-564922-3.
- Stoica, P.; Moses, R. (2005). Spectral Analysis of Signals. Prentice Hall. ISBN 978-0-13-113956-5.