


Summary
Visual perception is the ability to interpret the surrounding environment through photopic vision (daytime vision), color vision, scotopic vision (night vision), and mesopic vision (twilight vision), using light in the visible spectrum reflected by objects in the environment. This is different from visual acuity, which refers to how clearly a person sees (for example "20/20 vision"). A person can have problems with visual perceptual processing even if they have 20/20 vision.
The resulting perception is also known as vision, sight, or eyesight (adjectives visual, optical, and ocular, respectively). The various physiological components involved in vision are referred to collectively as the visual system, and are the focus of much research in linguistics, psychology, cognitive science, neuroscience, and molecular biology, collectively referred to as vision science.
Visual system edit
In humans and a number of other mammals, light enters the eye through the cornea and is focused by the lens onto the retina, a light-sensitive membrane at the back of the eye. The retina serves as a transducer for the conversion of light into neuronal signals. This transduction is achieved by specialized photoreceptive cells of the retina, also known as the rods and cones, which detect the photons of light and respond by producing neural impulses. These signals are transmitted by the optic nerve, from the retina upstream to central ganglia in the brain. The lateral geniculate nucleus, which transmits the information to the visual cortex. Signals from the retina also travel directly from the retina to the superior colliculus.[1]
The lateral geniculate nucleus sends signals to primary visual cortex, also called striate cortex. Extrastriate cortex, also called visual association cortex is a set of cortical structures, that receive information from striate cortex, as well as each other.[2] Recent descriptions of visual association cortex describe a division into two functional pathways, a ventral and a dorsal pathway. This conjecture is known as the two streams hypothesis.
The human visual system is generally believed to be sensitive to visible light in the range of wavelengths between 370 and 730 nanometers of the electromagnetic spectrum.[3] However, some research suggests that humans can perceive light in wavelengths down to 340 nanometers (UV-A), especially the young.[4] Under optimal conditions these limits of human perception can extend to 310 nm (UV) to 1100 nm (NIR).[5][6]
Study edit
The major problem in visual perception is that what people see is not simply a translation of retinal stimuli (i.e., the image on the retina), with the brain altering the basic information taken in. Thus people interested in perception have long struggled to explain what visual processing does to create what is actually seen.
Early studies edit

There were two major ancient Greek schools, providing a primitive explanation of how vision works.
The first was the "emission theory" of vision which maintained that vision occurs when rays emanate from the eyes and are intercepted by visual objects. If an object was seen directly it was by 'means of rays' coming out of the eyes and again falling on the object. A refracted image was, however, seen by 'means of rays' as well, which came out of the eyes, traversed through the air, and after refraction, fell on the visible object which was sighted as the result of the movement of the rays from the eye. This theory was championed by scholars who were followers of Euclid's Optics and Ptolemy's Optics.
The second school advocated the so-called 'intromission' approach which sees vision as coming from something entering the eyes representative of the object. With its main propagator Aristotle (De Sensu),[7] and his followers,[7] this theory seems to have some contact with modern theories of what vision really is, but it remained only a speculation lacking any experimental foundation. (In eighteenth-century England, Isaac Newton, John Locke, and others, carried the intromission theory of vision forward by insisting that vision involved a process in which rays—composed of actual corporeal matter—emanated from seen objects and entered the seer's mind/sensorium through the eye's aperture.)[8]
Both schools of thought relied upon the principle that "like is only known by like", and thus upon the notion that the eye was composed of some "internal fire" that interacted with the "external fire" of visible light and made vision possible. Plato makes this assertion in his dialogue Timaeus (45b and 46b), as does Empedocles (as reported by Aristotle in his De Sensu, DK frag. B17).[7]
Alhazen (965 – c. 1040) carried out many investigations and experiments on visual perception, extended the work of Ptolemy on binocular vision, and commented on the anatomical works of Galen.[9][10] He was the first person to explain that vision occurs when light bounces on an object and then is directed to one's eyes.[11]
Leonardo da Vinci (1452–1519) is believed to be the first to recognize the special optical qualities of the eye. He wrote "The function of the human eye ... was described by a large number of authors in a certain way. But I found it to be completely different." His main experimental finding was that there is only a distinct and clear vision at the line of sight—the optical line that ends at the fovea. Although he did not use these words literally he actually is the father of the modern distinction between foveal and peripheral vision.[12]
Isaac Newton (1642–1726/27) was the first to discover through experimentation, by isolating individual colors of the spectrum of light passing through a prism, that the visually perceived color of objects appeared due to the character of light the objects reflected, and that these divided colors could not be changed into any other color, which was contrary to scientific expectation of the day.[3]
Unconscious inference edit
Hermann von Helmholtz is often credited with the first modern study of visual perception. Helmholtz examined the human eye and concluded that it was incapable of producing a high-quality image. Insufficient information seemed to make vision impossible. He, therefore, concluded that vision could only be the result of some form of "unconscious inference", coining that term in 1867. He proposed the brain was making assumptions and conclusions from incomplete data, based on previous experiences.[13]
Inference requires prior experience of the world.
Examples of well-known assumptions, based on visual experience, are:
- light comes from above;
- objects are normally not viewed from below;
- faces are seen (and recognized) upright;[14]
- closer objects can block the view of more distant objects, but not vice versa; and
- figures (i.e., foreground objects) tend to have convex borders.
The study of visual illusions (cases when the inference process goes wrong) has yielded much insight into what sort of assumptions the visual system makes.
Another type of unconscious inference hypothesis (based on probabilities) has recently been revived in so-called Bayesian studies of visual perception.[15] Proponents of this approach consider that the visual system performs some form of Bayesian inference to derive a perception from sensory data. However, it is not clear how proponents of this view derive, in principle, the relevant probabilities required by the Bayesian equation. Models based on this idea have been used to describe various visual perceptual functions, such as the perception of motion, the perception of depth, and figure-ground perception.[16][17] The "wholly empirical theory of perception" is a related and newer approach that rationalizes visual perception without explicitly invoking Bayesian formalisms.[citation needed]
Gestalt theory edit
Gestalt psychologists working primarily in the 1930s and 1940s raised many of the research questions that are studied by vision scientists today.[18]
The Gestalt Laws of Organization have guided the study of how people perceive visual components as organized patterns or wholes, instead of many different parts. "Gestalt" is a German word that partially translates to "configuration or pattern" along with "whole or emergent structure". According to this theory, there are eight main factors that determine how the visual system automatically groups elements into patterns: Proximity, Similarity, Closure, Symmetry, Common Fate (i.e. common motion), Continuity as well as Good Gestalt (pattern that is regular, simple, and orderly) and Past Experience.[citation needed]
Analysis of eye movement edit
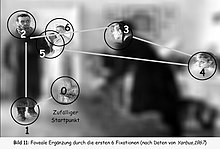
During the 1960s, technical development permitted the continuous registration of eye movement during reading,[19] in picture viewing,[20] and later, in visual problem solving,[21] and when headset-cameras became available, also during driving.[22]
The picture to the right shows what may happen during the first two seconds of visual inspection. While the background is out of focus, representing the peripheral vision, the first eye movement goes to the boots of the man (just because they are very near the starting fixation and have a reasonable contrast). Eye movements serve the function of attentional selection, i.e., to select a fraction of all visual inputs for deeper processing by the brain.[citation needed]
The following fixations jump from face to face. They might even permit comparisons between faces.[citation needed]
It may be concluded that the icon face is a very attractive search icon within the peripheral field of vision. The foveal vision adds detailed information to the peripheral first impression.
It can also be noted that there are different types of eye movements: fixational eye movements (microsaccades, ocular drift, and tremor), vergence movements, saccadic movements and pursuit movements. Fixations are comparably static points where the eye rests. However, the eye is never completely still, and gaze position will drift. These drifts are in turn corrected by microsaccades, very small fixational eye movements. Vergence movements involve the cooperation of both eyes to allow for an image to fall on the same area of both retinas. This results in a single focused image. Saccadic movements is the type of eye movement that makes jumps from one position to another position and is used to rapidly scan a particular scene/image. Lastly, pursuit movement is smooth eye movement and is used to follow objects in motion.[23]
Face and object recognition edit
There is considerable evidence that face and object recognition are accomplished by distinct systems. For example, prosopagnosic patients show deficits in face, but not object processing, while object agnosic patients (most notably, patient C.K.) show deficits in object processing with spared face processing.[24] Behaviorally, it has been shown that faces, but not objects, are subject to inversion effects, leading to the claim that faces are "special".[24][25] Further, face and object processing recruit distinct neural systems.[26] Notably, some have argued that the apparent specialization of the human brain for face processing does not reflect true domain specificity, but rather a more general process of expert-level discrimination within a given class of stimulus,[27] though this latter claim is the subject of substantial debate. Using fMRI and electrophysiology Doris Tsao and colleagues described brain regions and a mechanism for face recognition in macaque monkeys.[28]
The inferotemporal cortex has a key role in the task of recognition and differentiation of different objects. A study by MIT shows that subset regions of the IT cortex are in charge of different objects.[29] By selectively shutting off neural activity of many small areas of the cortex, the animal gets alternately unable to distinguish between certain particular pairments of objects. This shows that the IT cortex is divided into regions that respond to different and particular visual features. In a similar way, certain particular patches and regions of the cortex are more involved in face recognition than other object recognition.
Some studies tend to show that rather than the uniform global image, some particular features and regions of interest of the objects are key elements when the brain needs to recognise an object in an image.[30][31] In this way, the human vision is vulnerable to small particular changes to the image, such as disrupting the edges of the object, modifying texture or any small change in a crucial region of the image.[32]
Studies of people whose sight has been restored after a long blindness reveal that they cannot necessarily recognize objects and faces (as opposed to color, motion, and simple geometric shapes). Some hypothesize that being blind during childhood prevents some part of the visual system necessary for these higher-level tasks from developing properly.[33] The general belief that a critical period lasts until age 5 or 6 was challenged by a 2007 study that found that older patients could improve these abilities with years of exposure.[34]
Cognitive and computational approaches edit
In the 1970s, David Marr developed a multi-level theory of vision, which analyzed the process of vision at different levels of abstraction. In order to focus on the understanding of specific problems in vision, he identified three levels of analysis: the computational, algorithmic and implementational levels. Many vision scientists, including Tomaso Poggio, have embraced these levels of analysis and employed them to further characterize vision from a computational perspective.[35]
The computational level addresses, at a high level of abstraction, the problems that the visual system must overcome. The algorithmic level attempts to identify the strategy that may be used to solve these problems. Finally, the implementational level attempts to explain how solutions to these problems are realized in neural circuitry.
Marr suggested that it is possible to investigate vision at any of these levels independently. Marr described vision as proceeding from a two-dimensional visual array (on the retina) to a three-dimensional description of the world as output. His stages of vision include:
- A 2D or primal sketch of the scene, based on feature extraction of fundamental components of the scene, including edges, regions, etc. Note the similarity in concept to a pencil sketch drawn quickly by an artist as an impression.
- A 21⁄2 D sketch of the scene, where textures are acknowledged, etc. Note the similarity in concept to the stage in drawing where an artist highlights or shades areas of a scene, to provide depth.
- A 3 D model, where the scene is visualized in a continuous, 3-dimensional map.[36]
Marr's 21⁄2D sketch assumes that a depth map is constructed, and that this map is the basis of 3D shape perception. However, both stereoscopic and pictorial perception, as well as monocular viewing, make clear that the perception of 3D shape precedes, and does not rely on, the perception of the depth of points. It is not clear how a preliminary depth map could, in principle, be constructed, nor how this would address the question of figure-ground organization, or grouping. The role of perceptual organizing constraints, overlooked by Marr, in the production of 3D shape percepts from binocularly-viewed 3D objects has been demonstrated empirically for the case of 3D wire objects, e.g.[37][38] For a more detailed discussion, see Pizlo (2008).[39]
A more recent, alternative framework proposes that vision is composed instead of the following three stages: encoding, selection, and decoding.[40] Encoding is to sample and represent visual inputs (e.g., to represent visual inputs as neural activities in the retina). Selection, or attentional selection, is to select a tiny fraction of input information for further processing, e.g., by shifting gaze to an object or visual location to better process the visual signals at that location. Decoding is to infer or recognize the selected input signals, e.g., to recognize the object at the center of gaze as somebody's face. In this framework,[41] attentional selection starts at the primary visual cortex along the visual pathway, and the attentional constraints impose a dichotomy between the central and peripheral visual fields for visual recognition or decoding.
Transduction edit
Transduction is the process through which energy from environmental stimuli is converted to neural activity. The retina contains three different cell layers: photoreceptor layer, bipolar cell layer and ganglion cell layer. The photoreceptor layer where transduction occurs is farthest from the lens. It contains photoreceptors with different sensitivities called rods and cones. The cones are responsible for color perception and are of three distinct types labelled red, green and blue. Rods are responsible for the perception of objects in low light.[42] Photoreceptors contain within them a special chemical called a photopigment, which is embedded in the membrane of the lamellae; a single human rod contains approximately 10 million of them. The photopigment molecules consist of two parts: an opsin (a protein) and retinal (a lipid).[43] There are 3 specific photopigments (each with their own wavelength sensitivity) that respond across the spectrum of visible light. When the appropriate wavelengths (those that the specific photopigment is sensitive to) hit the photoreceptor, the photopigment splits into two, which sends a signal to the bipolar cell layer, which in turn sends a signal to the ganglion cells, the axons of which form the optic nerve and transmit the information to the brain. If a particular cone type is missing or abnormal, due to a genetic anomaly, a color vision deficiency, sometimes called color blindness will occur.[44]
Opponent process edit
Transduction involves chemical messages sent from the photoreceptors to the bipolar cells to the ganglion cells. Several photoreceptors may send their information to one ganglion cell. There are two types of ganglion cells: red/green and yellow/blue. These neurons constantly fire—even when not stimulated. The brain interprets different colors (and with a lot of information, an image) when the rate of firing of these neurons alters. Red light stimulates the red cone, which in turn stimulates the red/green ganglion cell. Likewise, green light stimulates the green cone, which stimulates the green/red ganglion cell and blue light stimulates the blue cone which stimulates the blue/yellow ganglion cell. The rate of firing of the ganglion cells is increased when it is signaled by one cone and decreased (inhibited) when it is signaled by the other cone. The first color in the name of the ganglion cell is the color that excites it and the second is the color that inhibits it. i.e.: A red cone would excite the red/green ganglion cell and the green cone would inhibit the red/green ganglion cell. This is an opponent process. If the rate of firing of a red/green ganglion cell is increased, the brain would know that the light was red, if the rate was decreased, the brain would know that the color of the light was green.[44]
Artificial visual perception edit
Theories and observations of visual perception have been the main source of inspiration for computer vision (also called machine vision, or computational vision). Special hardware structures and software algorithms provide machines with the capability to interpret the images coming from a camera or a sensor.
For instance, the 2022 Toyota 86 uses the Subaru EyeSight system for driver-assist technology.[45]
See also edit
- Color vision
- Computer vision
- Depth perception
- Entoptic phenomenon
- Gestalt psychology
- Lateral masking
- Looming
- Naked eye
- Machine vision
- McGill Picture Anomaly Test
- Motion perception
- Multisensory integration
- Interpretation (philosophy)
- Spatial frequency
- Visual illusion
- Visual processing
- Visual system
- Sensations
Vision deficiencies or disorders edit
Related disciplines edit
References edit
- ^ Sadun, Alfredo A.; Johnson, Betty M.; Smith, Lois E. H. (1986). "Neuroanatomy of the human visual system: Part II Retinal projections to the superior colliculus and pulvinar". Neuro-Ophthalmology. 6 (6): 363–370. doi:10.3109/01658108609016476. ISSN 0165-8107.
- ^ Carlson, Neil R. (2013). "6". Physiology of Behaviour (11th ed.). Upper Saddle River, New Jersey, US: Pearson Education Inc. pp. 187–189. ISBN 978-0-205-23939-9.
- ^ a b Margaret, Livingstone (2008). Vision and art : the biology of seeing. Hubel, David H. New York: Abrams. ISBN 978-0-8109-9554-3. OCLC 192082768.
- ^ Brainard, George C.; Beacham, Sabrina; Sanford, Britt E.; Hanifin, John P.; Streletz, Leopold; Sliney, David (March 1, 1999). "Near ultraviolet radiation elicits visual evoked potentials in children". Clinical Neurophysiology. 110 (3): 379–383. doi:10.1016/S1388-2457(98)00022-4. ISSN 1388-2457. PMID 10363758. S2CID 8509975.
- ^ D. H. Sliney (February 2016). "What is light? The visible spectrum and beyond". Eye. 30 (2): 222–229. doi:10.1038/eye.2015.252. ISSN 1476-5454. PMC 4763133. PMID 26768917.
- ^ W. C. Livingston (2001). Color and light in nature (2nd ed.). Cambridge, UK: Cambridge University Press. ISBN 0-521-77284-2.
- ^ a b c Finger, Stanley (1994). Origins of neuroscience: a history of explorations into brain function. Oxford [Oxfordshire]: Oxford University Press. pp. 67–69. ISBN 978-0-19-506503-9. OCLC 27151391.
- ^ Swenson Rivka (2010). "Optics, Gender, and the Eighteenth-Century Gaze: Looking at Eliza Haywood's Anti-Pamela". The Eighteenth Century: Theory and Interpretation. 51 (1–2): 27–43. doi:10.1353/ecy.2010.0006. S2CID 145149737.
- ^ Howard, I (1996). "Alhazen's neglected discoveries of visual phenomena". Perception. 25 (10): 1203–1217. doi:10.1068/p251203. PMID 9027923. S2CID 20880413.
- ^ Khaleefa, Omar (1999). "Who Is the Founder of Psychophysics and Experimental Psychology?". American Journal of Islamic Social Sciences. 16 (2): 1–26. doi:10.35632/ajis.v16i2.2126.
- ^ Adamson, Peter (July 7, 2016). Philosophy in the Islamic World: A History of Philosophy Without Any Gaps. Oxford University Press. p. 77. ISBN 978-0-19-957749-1.
- ^ Keele, Kd (1955). "Leonardo da Vinci on vision". Proceedings of the Royal Society of Medicine. 48 (5): 384–390. doi:10.1177/003591575504800512. ISSN 0035-9157. PMC 1918888. PMID 14395232.
- ^ von Helmholtz, Hermann (1925). Handbuch der physiologischen Optik. Vol. 3. Leipzig: Voss. Archived from the original on September 27, 2018. Retrieved December 14, 2016.
- ^ Hunziker, Hans-Werner (2006). Im Auge des Lesers: foveale und periphere Wahrnehmung – vom Buchstabieren zur Lesefreude [In the eye of the reader: foveal and peripheral perception – from letter recognition to the joy of reading]. Zürich: Transmedia Stäubli Verlag. ISBN 978-3-7266-0068-6.[page needed]
- ^ Stone, JV (2011). "Footprints sticking out of the sand. Part 2: children's Bayesian priors for shape and lighting direction" (PDF). Perception. 40 (2): 175–90. doi:10.1068/p6776. PMID 21650091. S2CID 32868278.
- ^ Mamassian, Pascal; Landy, Michael; Maloney, Laurence T. (2002). "Bayesian Modelling of Visual Perception". In Rao, Rajesh P. N.; Olshausen, Bruno A.; Lewicki, Michael S. (eds.). Probabilistic Models of the Brain: Perception and Neural Function. Neural Information Processing. MIT Press. pp. 13–36. ISBN 978-0-262-26432-7.
- ^ "A Primer on Probabilistic Approaches to Visual Perception". Archived from the original on July 10, 2006. Retrieved October 14, 2010.
- ^ Wagemans, Johan (November 2012). "A Century of Gestalt Psychology in Visual Perception". Psychological Bulletin. 138 (6): 1172–1217. CiteSeerX 10.1.1.452.8394. doi:10.1037/a0029333. PMC 3482144. PMID 22845751.
- ^ Taylor, Stanford E. (November 1965). "Eye Movements in Reading: Facts and Fallacies". American Educational Research Journal. 2 (4): 187–202. doi:10.2307/1161646. JSTOR 1161646.
- ^ Yarbus, A. L. (1967). Eye movements and vision, Plenum Press, New York[page needed]
- ^ Hunziker, H. W. (1970). "Visuelle Informationsaufnahme und Intelligenz: Eine Untersuchung über die Augenfixationen beim Problemlösen" [Visual information acquisition and intelligence: A study of the eye fixations in problem solving]. Schweizerische Zeitschrift für Psychologie und Ihre Anwendungen (in German). 29 (1/2).[page needed]
- ^ Cohen, A. S. (1983). "Informationsaufnahme beim Befahren von Kurven, Psychologie für die Praxis 2/83" [Information recording when driving on curves, psychology in practice 2/83]. Bulletin der Schweizerischen Stiftung für Angewandte Psychologie.[page needed]
- ^ Carlson, Neil R.; Heth, C. Donald; Miller, Harold; Donahoe, John W.; Buskist, William; Martin, G. Neil; Schmaltz, Rodney M. (2009). Psychology the Science of Behaviour. Toronto Ontario: Pearson Canada. pp. 140–1. ISBN 978-0-205-70286-2.
- ^ a b Moscovitch, Morris; Winocur, Gordon; Behrmann, Marlene (1997). "What Is Special about Face Recognition? Nineteen Experiments on a Person with Visual Object Agnosia and Dyslexia but Normal Face Recognition". Journal of Cognitive Neuroscience. 9 (5): 555–604. doi:10.1162/jocn.1997.9.5.555. PMID 23965118. S2CID 207550378.
- ^ Yin, Robert K. (1969). "Looking at upside-down faces". Journal of Experimental Psychology. 81 (1): 141–5. doi:10.1037/h0027474.
- ^ Kanwisher, Nancy; McDermott, Josh; Chun, Marvin M. (June 1997). "The fusiform face area: a module in human extrastriate cortex specialized for face perception". The Journal of Neuroscience. 17 (11): 4302–11. doi:10.1523/JNEUROSCI.17-11-04302.1997. PMC 6573547. PMID 9151747.
- ^ Gauthier, Isabel; Skudlarski, Pawel; Gore, John C.; Anderson, Adam W. (February 2000). "Expertise for cars and birds recruits brain areas involved in face recognition". Nature Neuroscience. 3 (2): 191–7. doi:10.1038/72140. PMID 10649576. S2CID 15752722.
- ^ Chang, Le; Tsao, Doris Y. (June 1, 2017). "The Code for Facial Identity in the Primate Brain". Cell. 169 (6): 1013–1028.e14. doi:10.1016/j.cell.2017.05.011. ISSN 0092-8674. PMC 8088389. PMID 28575666.
- ^ "How the brain distinguishes between objects". MIT News. March 13, 2019. Retrieved October 10, 2019.
- ^ Srivastava, Sanjana; Ben-Yosef, Guy; Boix, Xavier (February 8, 2019). Minimal Images in Deep Neural Networks: Fragile Object Recognition in Natural Images. arXiv:1902.03227. OCLC 1106329907.
- ^ Ben-Yosef, Guy; Assif, Liav; Ullman, Shimon (February 2018). "Full interpretation of minimal images". Cognition. 171: 65–84. doi:10.1016/j.cognition.2017.10.006. hdl:1721.1/106887. ISSN 0010-0277. PMID 29107889. S2CID 3372558.
- ^ Elsayed, Gamaleldin F.; Shankar, Shreya; Cheung, Brian; Papernot, Nicolas; Kurakin, Alex; Goodfellow, Ian; Sohl-Dickstein, Jascha (February 22, 2018). "Adversarial Examples that Fool both Computer Vision and Time-Limited Humans" (PDF). Advances in Neural Information Processing Systems 31 (NeurIPS 2018). arXiv:1802.08195. OCLC 1106289156.
- ^ Man with restored sight provides new insight into how vision develops
- ^ Out Of Darkness, Sight: Rare Cases Of Restored Vision Reveal How The Brain Learns To See
- ^ Poggio, Tomaso (1981). "Marr's Computational Approach to Vision". Trends in Neurosciences. 4: 258–262. doi:10.1016/0166-2236(81)90081-3. S2CID 53163190.
- ^ Marr, D (1982). Vision: A Computational Investigation into the Human Representation and Processing of Visual Information. MIT Press.[page needed]
- ^ Rock, Irvin; DiVita, Joseph (1987). "A case of viewer-centered object perception". Cognitive Psychology. 19 (2): 280–293. doi:10.1016/0010-0285(87)90013-2. PMID 3581759. S2CID 40154873.
- ^ Pizlo, Zygmunt; Stevenson, Adam K. (1999). "Shape constancy from novel views". Perception & Psychophysics. 61 (7): 1299–1307. doi:10.3758/BF03206181. ISSN 0031-5117. PMID 10572459. S2CID 8041318.
- ^ 3D Shape, Z. Pizlo (2008) MIT Press
- ^ Zhaoping, Li (2014). Understanding vision: theory, models, and data. United Kingdom: Oxford University Press. ISBN 978-0199564668.
- ^ Zhaoping, L (2019). "A new framework for understanding vision from the perspective of the primary visual cortex". Current Opinion in Neurobiology. 58: 1–10. doi:10.1016/j.conb.2019.06.001. PMID 31271931. S2CID 195806018.
- ^ Hecht, Selig (April 1, 1937). "Rods, Cones, and the Chemical Basis of Vision". Physiological Reviews. 17 (2): 239–290. doi:10.1152/physrev.1937.17.2.239. ISSN 0031-9333.
- ^ Carlson, Neil R. (2013). "6". Physiology of Behaviour (11th ed.). Upper Saddle River, New Jersey, US: Pearson Education Inc. p. 170. ISBN 978-0-205-23939-9.
- ^ a b Carlson, Neil R.; Heth, C. Donald (2010). "5". Psychology the science of behaviour (2nd ed.). Upper Saddle River, New Jersey, US: Pearson Education Inc. pp. 138–145. ISBN 978-0-205-64524-4.
- ^ "2022 Toyota GR 86 embraces sports car evolution with fresh looks, more power".
Further reading edit
- Von Helmholtz, Hermann (1867). Handbuch der physiologischen Optik. Vol. 3. Leipzig: Voss. Quotations are from the English translation produced by the Optical Society of America (1924–25): Treatise on Physiological Optics Archived September 27, 2018, at the Wayback Machine.
External links edit
- The Organization of the Retina and Visual System
- Effect of Detail on Visual Perception by Jon McLoone, the Wolfram Demonstrations Project
- The Joy of Visual Perception, resource on the eye's perception abilities.
- VisionScience. Resource for Research in Human and Animal Vision A collection of resources in vision science and perception
- Vision and Psychophysics
- Vision, Scholarpedia Expert articles about Vision
- What are the limits of human vision?