


Summary
In scientific visualization and computer graphics, volume rendering is a set of techniques used to display a 2D projection of a 3D discretely sampled data set, typically a 3D scalar field.


A typical 3D data set is a group of 2D slice images acquired by a CT, MRI, or MicroCT scanner. Usually these are acquired in a regular pattern (e.g., one slice for each millimeter of depth) and usually have a regular number of image pixels in a regular pattern. This is an example of a regular volumetric grid, with each volume element, or voxel represented by a single value that is obtained by sampling the immediate area surrounding the voxel.
To render a 2D projection of the 3D data set, one first needs to define a camera in space relative to the volume. Also, one needs to define the opacity and color of every voxel. This is usually defined using an RGBA (for red, green, blue, alpha) transfer function that defines the RGBA value for every possible voxel value.
For example, a volume may be viewed by extracting isosurfaces (surfaces of equal values) from the volume and rendering them as polygonal meshes or by rendering the volume directly as a block of data. The marching cubes algorithm is a common technique for extracting an isosurface from volume data. Direct volume rendering is a computationally intensive task that may be performed in several ways.
Another method of volume rendering is Ray marching.
Scope edit

Volume rendering is distinguished from thin slice tomography presentations, and is also generally distinguished from projections of 3D models, including maximum intensity projection.[1] Still, technically, all volume renderings become projections when viewed on a 2-dimensional display, making the distinction between projections and volume renderings a bit vague. Nevertheless, the epitomes of volume rendering models feature a mix of for example coloring[2] and shading[3] in order to create realistic and/or observable representations.
Direct volume rendering edit
A direct volume renderer[4][5] requires every sample value to be mapped to opacity and a color. This is done with a "transfer function" which can be a simple ramp, a piecewise linear function or an arbitrary table. Once converted to an RGBA color model (for red, green, blue, alpha) value, the composed RGBA result is projected on the corresponding pixel of the frame buffer. The way this is done depends on the rendering technique.
A combination of these techniques is possible. For instance, a shear warp implementation could use texturing hardware to draw the aligned slices in the off-screen buffer.
Volume ray casting edit

The technique of volume ray casting can be derived directly from the rendering equation. It provides results of very high quality, usually considered to provide the best image quality. Volume ray casting is classified as image based volume rendering technique, as the computation emanates from the output image, not the input volume data as is the case with object based techniques. In this technique, a ray is generated for each desired image pixel. Using a simple camera model, the ray starts at the center of projection of the camera (usually the eye point) and passes through the image pixel on the imaginary image plane floating in between the camera and the volume to be rendered. The ray is clipped by the boundaries of the volume in order to save time. Then the ray is sampled at regular or adaptive intervals throughout the volume. The data is interpolated at each sample point, the transfer function applied to form an RGBA sample, the sample is composited onto the accumulated RGBA of the ray, and the process repeated until the ray exits the volume. The RGBA color is converted to an RGB color and deposited in the corresponding image pixel. The process is repeated for every pixel on the screen to form the completed image.
Splatting edit
This is a technique which trades quality for speed. Here, every volume element is splatted, as Lee Westover said, like a snow ball, on to the viewing surface in back to front order. These splats are rendered as disks whose properties (color and transparency) vary diametrically in normal (Gaussian) manner. Flat disks and those with other kinds of property distribution are also used depending on the application.[6][7]
Shear warp edit

The shear warp approach to volume rendering was developed by Cameron and Undrill, popularized by Philippe Lacroute and Marc Levoy.[8] In this technique, the viewing transformation is transformed such that the nearest face of the volume becomes axis aligned with an off-screen image data buffer with a fixed scale of voxels to pixels. The volume is then rendered into this buffer using the far more favorable memory alignment and fixed scaling and blending factors. Once all slices of the volume have been rendered, the buffer is then warped into the desired orientation and scaled in the displayed image.
This technique is relatively fast in software at the cost of less accurate sampling and potentially worse image quality compared to ray casting. There is memory overhead for storing multiple copies of the volume, for the ability to have near axis aligned volumes. This overhead can be mitigated using run length encoding.
Texture-based volume rendering edit
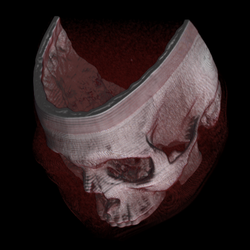
Many 3D graphics systems use texture mapping to apply images, or textures, to geometric objects. Commodity PC graphics cards are fast at texturing and can efficiently render slices of a 3D volume, with real time interaction capabilities. Workstation GPUs are even faster, and are the basis for much of the production volume visualization used in medical imaging, oil and gas, and other markets (2007). In earlier years, dedicated 3D texture mapping systems were used on graphics systems such as Silicon Graphics InfiniteReality, HP Visualize FX graphics accelerator, and others. This technique was first described by Bill Hibbard and Dave Santek.[9]
These slices can either be aligned with the volume and rendered at an angle to the viewer, or aligned with the viewing plane and sampled from unaligned slices through the volume. Graphics hardware support for 3D textures is needed for the second technique.
Volume aligned texturing produces images of reasonable quality, though there is often a noticeable transition when the volume is rotated.
Hardware-accelerated volume rendering edit
Due to the extremely parallel nature of direct volume rendering, special purpose volume rendering hardware was a rich research topic before GPU volume rendering became fast enough. The most widely cited technology was the VolumePro real-time ray-casting system, developed by Hanspeter Pfister and scientists at Mitsubishi Electric Research Laboratories,[10] which used high memory bandwidth and brute force to render using the ray casting algorithm. The technology was transferred to TeraRecon, Inc. and two generations of ASICs were produced and sold. The VP1000[11] was released in 2002 and the VP2000[12] in 2007.
A recently exploited technique to accelerate traditional volume rendering algorithms such as ray-casting is the use of modern graphics cards. Starting with the programmable pixel shaders, people recognized the power of parallel operations on multiple pixels and began to perform general-purpose computing on (the) graphics processing units (GPGPU). The pixel shaders are able to read and write randomly from video memory and perform some basic mathematical and logical calculations. These SIMD processors were used to perform general calculations such as rendering polygons and signal processing. In recent GPU generations, the pixel shaders now are able to function as MIMD processors (now able to independently branch) utilizing up to 1 GB of texture memory with floating point formats. With such power, virtually any algorithm with steps that can be performed in parallel, such as volume ray casting or tomographic reconstruction, can be performed with tremendous acceleration. The programmable pixel shaders can be used to simulate variations in the characteristics of lighting, shadow, reflection, emissive color and so forth. Such simulations can be written using high level shading languages.
Optimization techniques edit
The primary goal of optimization is to skip as much of the volume as possible. A typical medical data set can be 1 GB in size. To render that at 30 frame/s requires an extremely fast memory bus. Skipping voxels means less information needs to be processed.
Empty space skipping edit
Often, a volume rendering system will have a system for identifying regions of the volume containing no visible material. This information can be used to avoid rendering these transparent regions.[13]
Early ray termination edit
This is a technique used when the volume is rendered in front to back order. For a ray through a pixel, once sufficient dense material has been encountered, further samples will make no significant contribution to the pixel and so may be neglected.
Octree and BSP space subdivision edit
The use of hierarchical structures such as octree and BSP-tree could be very helpful for both compression of volume data and speed optimization of volumetric ray casting process.
Volume segmentation edit


- blue: pulmonary arteries
- red: pulmonary veins (and also the abdominal wall)
- yellow: the mediastinum
- violet: the diaphragm
Image segmentation is a manual or automatic procedure that can be used to section out large portions of the volume that one considers uninteresting before rendering, the amount of calculations that have to be made by ray casting or texture blending can be significantly reduced. This reduction can be as much as from O(n) to O(log n) for n sequentially indexed voxels. Volume segmentation also has significant performance benefits for other ray tracing algorithms. Volume segmentation can subsequently be used to highlight structures of interest.
Multiple and adaptive resolution representation edit
By representing less interesting regions of the volume in a coarser resolution, the data input overhead can be reduced. On closer observation, the data in these regions can be populated either by reading from memory or disk, or by interpolation. The coarser resolution volume is resampled to a smaller size in the same way as a 2D mipmap image is created from the original. These smaller volume are also used by themselves while rotating the volume to a new orientation.
Pre-integrated volume rendering edit
Pre-integrated volume rendering[14] is a method that can reduce sampling artifacts by pre-computing much of the required data. It is especially useful in hardware-accelerated applications[15][16] because it improves quality without a large performance impact. Unlike most other optimizations, this does not skip voxels. Rather it reduces the number of samples needed to accurately display a region of voxels. The idea is to render the intervals between the samples instead of the samples themselves. This technique captures rapidly changing material, for example the transition from muscle to bone with much less computation.
Image-based meshing edit
Image-based meshing is the automated process of creating computer models from 3D image data (such as MRI, CT, Industrial CT or microtomography) for computational analysis and design, e.g. CAD, CFD, and FEA.
Temporal reuse of voxels edit
For a complete display view, only one voxel per pixel (the front one) is required to be shown (although more can be used for smoothing the image), if animation is needed, the front voxels to be shown can be cached and their location relative to the camera can be recalculated as it moves. Where display voxels become too far apart to cover all the pixels, new front voxels can be found by ray casting or similar, and where two voxels are in one pixel, the front one can be kept.
edit
- Open source
- 3D Slicer – a software package for scientific visualization and image analysis
- ClearVolume – a GPU ray-casting based, live 3D visualization library designed for high-end volumetric light sheet microscopes.
- ParaView – a cross-platform, large data analysis and visualization application. ParaView users can quickly build visualizations to analyze their data using qualitative and quantitative techniques. ParaView is built on VTK (below).
- Studierfenster (StudierFenster) – a free, non-commercial Open Science client/server-based Medical Imaging Processing (MIP) online framework.
- Vaa3D – a 3D, 4D and 5D volume rendering and image analysis platform for gigabytes and terabytes of large images (based on OpenGL) especially in the microscopy image field. Also cross-platform with Mac, Windows, and Linux versions. Include a comprehensive plugin interface and 100 plugins for image analysis. Also render multiple types of surface objects.
- VisIt – a cross-platform interactive parallel visualization and graphical analysis tool for viewing scientific data.
- Volume cartography – an open source software used in recovering the En-Gedi Scroll.
- Voreen – a cross-platform rapid application development framework for the interactive visualization and analysis of multi-modal volumetric data sets. It provides GPU-based volume rendering and data analysis techniques
- VTK – a general-purpose C++ toolkit for data processing, visualization, 3D interaction, computational geometry, with Python and Java bindings. Also, VTK.js provides a JavaScript implementation.
- Commercial
- Ambivu 3D Workstation – a medical imaging workstation that offers a range of volume rendering modes (based on OpenGL)
- Amira – a 3D visualization and analysis software for scientists and researchers (in life sciences and biomedical)
- Imaris – a scientific software module that delivers all the necessary functionality for data management, visualization, analysis, segmentation and interpretation of 3D and 4D microscopy datasets
- MeVisLab – cross-platform software for medical image processing and visualization (based on OpenGL and Open Inventor)
- Open Inventor – a high-level 3D API for 3D graphics software development (C++, .NET, Java)
- ScanIP – an image processing and image-based meshing platform that can render scan data (MRI, CT, Micro-CT...) in 3D directly after import.

See also edit
- Isosurface, a surface that represents points of a constant value (e.g. pressure, temperature, velocity, density) within a volume of space
- Flow visualization, a technique for the visualization of vector fields
- Volume mesh, a polygonal representation of the interior volume of an object
References edit
- ^ Fishman, Elliot K.; Ney, Derek R.; Heath, David G.; Corl, Frank M.; Horton, Karen M.; Johnson, Pamela T. (2006). "Volume Rendering versus Maximum Intensity Projection in CT Angiography: What Works Best, When, and Why". RadioGraphics. 26 (3): 905–922. doi:10.1148/rg.263055186. ISSN 0271-5333. PMID 16702462.
- ^ Silverstein, Jonathan C.; Parsad, Nigel M.; Tsirline, Victor (2008). "Automatic perceptual color map generation for realistic volume visualization". Journal of Biomedical Informatics. 41 (6): 927–935. doi:10.1016/j.jbi.2008.02.008. ISSN 1532-0464. PMC 2651027. PMID 18430609.
- ^ Page 185 in Leif Kobbelt (2006). Vision, Modeling, and Visualization 2006: Proceedings, November 22-24. IOS Press. ISBN 9783898380812.
- ^ Marc Levoy, "Display of Surfaces from Volume Data", IEEE CG&A, May 1988. Archive of Paper
- ^ Drebin, Robert A.; Carpenter, Loren; Hanrahan, Pat (1988). "Volume rendering". ACM SIGGRAPH Computer Graphics. 22 (4): 65. doi:10.1145/378456.378484. Drebin, Robert A.; Carpenter, Loren; Hanrahan, Pat (1988). Proceedings of the 15th annual conference on Computer graphics and interactive techniques - SIGGRAPH '88. p. 65. doi:10.1145/54852.378484. ISBN 978-0897912754. S2CID 17982419.
- ^ Westover, Lee Alan (July 1991). "SPLATTING: A Parallel, Feed-Forward Volume Rendering Algorithm" (PDF). Retrieved 28 June 2012.[dead link]
- ^ Huang, Jian (Spring 2002). "Splatting" (PPT). Retrieved 5 August 2011.
- ^ Lacroute, Philippe; Levoy, Marc (1994-01-01). "Fast volume rendering using a shear-warp factorization of the viewing transformation". Proceedings of the 21st annual conference on Computer graphics and interactive techniques - SIGGRAPH '94. SIGGRAPH '94. New York, NY, USA: ACM. pp. 451–458. CiteSeerX 10.1.1.75.7117. doi:10.1145/192161.192283. ISBN 978-0897916677. S2CID 1266012.
- ^ Hibbard W., Santek D., "Interactivity is the key", Chapel Hill Workshop on Volume Visualization, University of North Carolina, Chapel Hill, 1989, pp. 39–43.
- ^ Pfister, Hanspeter; Hardenbergh, Jan; Knittel, Jim; Lauer, Hugh; Seiler, Larry (1999). "The VolumePro real-time ray-casting system". Proceedings of the 26th annual conference on Computer graphics and interactive techniques - SIGGRAPH '99. pp. 251–260. CiteSeerX 10.1.1.471.9205. doi:10.1145/311535.311563. ISBN 978-0201485608. S2CID 7673547.
{{cite book}}: CS1 maint: date and year (link) - ^ Wu, Yin; Bhatia, Vishal; Lauer, Hugh; Seiler, Larry (2003). "Shear-image order ray casting volume rendering". Proceedings of the 2003 symposium on Interactive 3D graphics. p. 152. doi:10.1145/641480.641510. ISBN 978-1581136456. S2CID 14641432.
- ^ TeraRecon. "Product Announcement". healthimaging.com. Retrieved 27 August 2018.
- ^ Sherbondy A., Houston M., Napel S.: Fast volume segmentation with simultaneous visualization using programmable graphics hardware. In Proceedings of IEEE Visualization (2003), pp. 171–176.
- ^ Max N., Hanrahan P., Crawfis R.: Area and volume coherence for efficient visualization of 3D scalar functions. In Computer Graphics (San Diego Workshop on Volume Visualization, 1990) vol. 24, pp. 27–33.
- ^ Engel, Klaus; Kraus, Martin; Ertl, Thomas (2001). "High-quality pre-integrated volume rendering using hardware-accelerated pixel shading". Proceedings of the ACM SIGGRAPH/EUROGRAPHICS workshop on Graphics hardware. pp. 9–16. CiteSeerX 10.1.1.458.1814. doi:10.1145/383507.383515. ISBN 978-1581134070. S2CID 14409951.
{{cite book}}: CS1 maint: date and year (link) - ^ Lum E., Wilson B., Ma K.: High-Quality Lighting and Efficient Pre-Integration for Volume Rendering. In Eurographics/IEEE Symposium on Visualization 2004.
Further reading edit
- M. Ikits, J. Kniss, A. Lefohn and C. Hansen: Volume Rendering Techniques. In: GPU Gems, Chapter 39 (online-version in the developer zone of Nvidia).
- Volume Rendering, Volume Rendering Basics Tutorial by Ph.D. Ömer Cengiz ÇELEBİ
- Barthold Lichtenbelt, Randy Crane, Shaz Naqvi, Introduction to Volume Rendering (Hewlett-Packard Professional Books), Hewlett-Packard Company 1998.
- Peng H., Ruan, Z, Long, F, Simpson, JH, Myers, EW: V3D enables real-time 3D visualization and quantitative analysis of large-scale biological image data sets. Nature Biotechnology, 2010 doi:10.1038/nbt.1612 Volume Rendering of large high-dimensional image data.
- Daniel Weiskopf (2006). GPU-Based Interactive Visualization Techniques. Springer Science & Business Media. ISBN 978-3-540-33263-3.