


Summary
In mathematics, a norm is a function from a real or complex vector space to the non-negative real numbers that behaves in certain ways like the distance from the origin: it commutes with scaling, obeys a form of the triangle inequality, and is zero only at the origin. In particular, the Euclidean distance in a Euclidean space is defined by a norm on the associated Euclidean vector space, called the Euclidean norm, the 2-norm, or, sometimes, the magnitude or length of the vector. This norm can be defined as the square root of the inner product of a vector with itself.
A seminorm satisfies the first two properties of a norm, but may be zero for vectors other than the origin.[1] A vector space with a specified norm is called a normed vector space. In a similar manner, a vector space with a seminorm is called a seminormed vector space.
The term pseudonorm has been used for several related meanings. It may be a synonym of "seminorm".[1] A pseudonorm may satisfy the same axioms as a norm, with the equality replaced by an inequality "" in the homogeneity axiom.[2][dubious – discuss] It can also refer to a norm that can take infinite values,[3] or to certain functions parametrised by a directed set.[4]

Definition
editGiven a vector space over a subfield of the complex numbers a norm on is a real-valued function with the following properties, where denotes the usual absolute value of a scalar :[5]






- Subadditivity/Triangle inequality: for all
- Absolute homogeneity: for all and all scalars
- Positive definiteness/positiveness[6]/Point-separating: for all if then
- Because property (2.) implies some authors replace property (3.) with the equivalent condition: for every if and only if









A seminorm on is a function that has properties (1.) and (2.)[7] so that in particular, every norm is also a seminorm (and thus also a sublinear functional). However, there exist seminorms that are not norms. Properties (1.) and (2.) imply that if is a norm (or more generally, a seminorm) then and that also has the following property:


- Non-negativity:[6] for all


Some authors include non-negativity as part of the definition of "norm", although this is not necessary. Although this article defined "positive" to be a synonym of "positive definite", some authors instead define "positive" to be a synonym of "non-negative";[8] these definitions are not equivalent.
Equivalent norms
editSuppose that and are two norms (or seminorms) on a vector space Then and are called equivalent, if there exist two positive real constants and with such that for every vector The relation " is equivalent to " is reflexive, symmetric ( implies ), and transitive and thus defines an equivalence relation on the set of all norms on The norms and are equivalent if and only if they induce the same topology on [9] Any two norms on a finite-dimensional space are equivalent but this does not extend to infinite-dimensional spaces.[9]








Notation
editIf a norm is given on a vector space then the norm of a vector is usually denoted by enclosing it within double vertical lines: Such notation is also sometimes used if is only a seminorm. For the length of a vector in Euclidean space (which is an example of a norm, as explained below), the notation with single vertical lines is also widespread.




Examples
editEvery (real or complex) vector space admits a norm: If is a Hamel basis for a vector space then the real-valued map that sends (where all but finitely many of the scalars are ) to is a norm on [10] There are also a large number of norms that exhibit additional properties that make them useful for specific problems.





Absolute-value norm
editThe absolute value is a norm on the vector space formed by the real or complex numbers. The complex numbers form a one-dimensional vector space over themselves and a two-dimensional vector space over the reals; the absolute value is a norm for these two structures.
Any norm on a one-dimensional vector space is equivalent (up to scaling) to the absolute value norm, meaning that there is a norm-preserving isomorphism of vector spaces where is either or and norm-preserving means that This isomorphism is given by sending to a vector of norm which exists since such a vector is obtained by multiplying any non-zero vector by the inverse of its norm.






Euclidean norm
editOn the -dimensional Euclidean space the intuitive notion of length of the vector is captured by the formula[11]




This is the Euclidean norm, which gives the ordinary distance from the origin to the point X—a consequence of the Pythagorean theorem. This operation may also be referred to as "SRSS", which is an acronym for the square root of the sum of squares.[12]
The Euclidean norm is by far the most commonly used norm on [11] but there are other norms on this vector space as will be shown below. However, all these norms are equivalent in the sense that they all define the same topology on finite-dimensional spaces.
The inner product of two vectors of a Euclidean vector space is the dot product of their coordinate vectors over an orthonormal basis. Hence, the Euclidean norm can be written in a coordinate-free way as

The Euclidean norm is also called the quadratic norm, norm,[13] norm, 2-norm, or square norm; see space. It defines a distance function called the Euclidean length, distance, or distance.



The set of vectors in whose Euclidean norm is a given positive constant forms an -sphere.

Euclidean norm of complex numbers
editThe Euclidean norm of a complex number is the absolute value (also called the modulus) of it, if the complex plane is identified with the Euclidean plane This identification of the complex number as a vector in the Euclidean plane, makes the quantity (as first suggested by Euler) the Euclidean norm associated with the complex number. For , the norm can also be written as where is the complex conjugate of







Quaternions and octonions
editThere are exactly four Euclidean Hurwitz algebras over the real numbers. These are the real numbers the complex numbers the quaternions and lastly the octonions where the dimensions of these spaces over the real numbers are respectively. The canonical norms on and are their absolute value functions, as discussed previously.





The canonical norm on of quaternions is defined by for every quaternion in This is the same as the Euclidean norm on considered as the vector space Similarly, the canonical norm on the octonions is just the Euclidean norm on






Finite-dimensional complex normed spaces
editOn an -dimensional complex space the most common norm is


In this case, the norm can be expressed as the square root of the inner product of the vector and itself: where is represented as a column vector and denotes its conjugate transpose.




This formula is valid for any inner product space, including Euclidean and complex spaces. For complex spaces, the inner product is equivalent to the complex dot product. Hence the formula in this case can also be written using the following notation:
Taxicab norm or Manhattan norm
editThe name relates to the distance a taxi has to drive in a rectangular street grid (like that of the New York borough of Manhattan) to get from the origin to the point


The set of vectors whose 1-norm is a given constant forms the surface of a cross polytope, which has dimension equal to the dimension of the vector space minus 1. The Taxicab norm is also called the norm. The distance derived from this norm is called the Manhattan distance or distance.

The 1-norm is simply the sum of the absolute values of the columns.
In contrast, is not a norm because it may yield negative results.

p-norm
editLet be a real number. The -norm (also called -norm) of vector is[11] For we get the taxicab norm, for we get the Euclidean norm, and as approaches the -norm approaches the infinity norm or maximum norm: The -norm is related to the generalized mean or power mean.








For the -norm is even induced by a canonical inner product meaning that for all vectors This inner product can be expressed in terms of the norm by using the polarization identity. On this inner product is the Euclidean inner product defined by while for the space associated with a measure space which consists of all square-integrable functions, this inner product is










This definition is still of some interest for but the resulting function does not define a norm,[14] because it violates the triangle inequality. What is true for this case of even in the measurable analog, is that the corresponding class is a vector space, and it is also true that the function (without th root) defines a distance that makes into a complete metric topological vector space. These spaces are of great interest in functional analysis, probability theory and harmonic analysis. However, aside from trivial cases, this topological vector space is not locally convex, and has no continuous non-zero linear forms. Thus the topological dual space contains only the zero functional.



The partial derivative of the -norm is given by

The derivative with respect to therefore, is where denotes Hadamard product and is used for absolute value of each component of the vector.




For the special case of this becomes or


Maximum norm (special case of: infinity norm, uniform norm, or supremum norm)
edit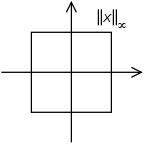

If is some vector such that then:



The set of vectors whose infinity norm is a given constant, forms the surface of a hypercube with edge length


Zero norm
editIn probability and functional analysis, the zero norm induces a complete metric topology for the space of measurable functions and for the F-space of sequences with F–norm [15] Here we mean by F-norm some real-valued function on an F-space with distance such that The F-norm described above is not a norm in the usual sense because it lacks the required homogeneity property.




Hamming distance of a vector from zero
editIn metric geometry, the discrete metric takes the value one for distinct points and zero otherwise. When applied coordinate-wise to the elements of a vector space, the discrete distance defines the Hamming distance, which is important in coding and information theory. In the field of real or complex numbers, the distance of the discrete metric from zero is not homogeneous in the non-zero point; indeed, the distance from zero remains one as its non-zero argument approaches zero. However, the discrete distance of a number from zero does satisfy the other properties of a norm, namely the triangle inequality and positive definiteness. When applied component-wise to vectors, the discrete distance from zero behaves like a non-homogeneous "norm", which counts the number of non-zero components in its vector argument; again, this non-homogeneous "norm" is discontinuous.
In signal processing and statistics, David Donoho referred to the zero "norm" with quotation marks. Following Donoho's notation, the zero "norm" of is simply the number of non-zero coordinates of or the Hamming distance of the vector from zero. When this "norm" is localized to a bounded set, it is the limit of -norms as approaches 0. Of course, the zero "norm" is not truly a norm, because it is not positive homogeneous. Indeed, it is not even an F-norm in the sense described above, since it is discontinuous, jointly and severally, with respect to the scalar argument in scalar–vector multiplication and with respect to its vector argument. Abusing terminology, some engineers[who?] omit Donoho's quotation marks and inappropriately call the number-of-non-zeros function the norm, echoing the notation for the Lebesgue space of measurable functions.


Infinite dimensions
editThe generalization of the above norms to an infinite number of components leads to and spaces for with norms


for complex-valued sequences and functions on respectively, which can be further generalized (see Haar measure). These norms are also valid in the limit as , giving a supremum norm, and are called and




Any inner product induces in a natural way the norm

Other examples of infinite-dimensional normed vector spaces can be found in the Banach space article.
Generally, these norms do not give the same topologies. For example, an infinite-dimensional space gives a strictly finer topology than an infinite-dimensional space when


Composite norms
editOther norms on can be constructed by combining the above; for example is a norm on


For any norm and any injective linear transformation we can define a new norm of equal to In 2D, with a rotation by 45° and a suitable scaling, this changes the taxicab norm into the maximum norm. Each applied to the taxicab norm, up to inversion and interchanging of axes, gives a different unit ball: a parallelogram of a particular shape, size, and orientation.


In 3D, this is similar but different for the 1-norm (octahedrons) and the maximum norm (prisms with parallelogram base).
There are examples of norms that are not defined by "entrywise" formulas. For instance, the Minkowski functional of a centrally-symmetric convex body in (centered at zero) defines a norm on (see § Classification of seminorms: absolutely convex absorbing sets below).
All the above formulas also yield norms on without modification.

There are also norms on spaces of matrices (with real or complex entries), the so-called matrix norms.
In abstract algebra
editLet be a finite extension of a field of inseparable degree and let have algebraic closure If the distinct embeddings of are then the Galois-theoretic norm of an element is the value As that function is homogeneous of degree , the Galois-theoretic norm is not a norm in the sense of this article. However, the -th root of the norm (assuming that concept makes sense) is a norm.[16]







![{\displaystyle [E:k]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/310a9eea16514b602e0ded65d3ae4ad3dd341938)
Composition algebras
editThe concept of norm in composition algebras does not share the usual properties of a norm since null vectors are allowed. A composition algebra consists of an algebra over a field an involution and a quadratic form called the "norm".





The characteristic feature of composition algebras is the homomorphism property of : for the product of two elements and of the composition algebra, its norm satisfies In the case of division algebras and the composition algebra norm is the square of the norm discussed above. In those cases the norm is a definite quadratic form. In the split algebras the norm is an isotropic quadratic form.






Properties
editFor any norm on a vector space the reverse triangle inequality holds: If is a continuous linear map between normed spaces, then the norm of and the norm of the transpose of are equal.[17]



For the norms, we have Hölder's inequality[18] A special case of this is the Cauchy–Schwarz inequality:[18]



Every norm is a seminorm and thus satisfies all properties of the latter. In turn, every seminorm is a sublinear function and thus satisfies all properties of the latter. In particular, every norm is a convex function.
Equivalence
editThe concept of unit circle (the set of all vectors of norm 1) is different in different norms: for the 1-norm, the unit circle is a square oriented as a diamond; for the 2-norm (Euclidean norm), it is the well-known unit circle; while for the infinity norm, it is an axis-aligned square. For any -norm, it is a superellipse with congruent axes (see the accompanying illustration). Due to the definition of the norm, the unit circle must be convex and centrally symmetric (therefore, for example, the unit ball may be a rectangle but cannot be a triangle, and for a -norm).
In terms of the vector space, the seminorm defines a topology on the space, and this is a Hausdorff topology precisely when the seminorm can distinguish between distinct vectors, which is again equivalent to the seminorm being a norm. The topology thus defined (by either a norm or a seminorm) can be understood either in terms of sequences or open sets. A sequence of vectors is said to converge in norm to if as Equivalently, the topology consists of all sets that can be represented as a union of open balls. If is a normed space then[19]





![{\displaystyle \|x-y\|=\|x-z\|+\|z-y\|{\text{ for all }}x,y\in X{\text{ and }}z\in [x,y].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/260066e13f1afcce833e2deda11b06fce7662378)
Two norms and on a vector space are called equivalent if they induce the same topology,[9] which happens if and only if there exist positive real numbers and such that for all For instance, if on then[20]






In particular, That is, If the vector space is a finite-dimensional real or complex one, all norms are equivalent. On the other hand, in the case of infinite-dimensional vector spaces, not all norms are equivalent.




Equivalent norms define the same notions of continuity and convergence and for many purposes do not need to be distinguished. To be more precise the uniform structure defined by equivalent norms on the vector space is uniformly isomorphic.
Classification of seminorms: absolutely convex absorbing sets
editAll seminorms on a vector space can be classified in terms of absolutely convex absorbing subsets of To each such subset corresponds a seminorm called the gauge of defined as where is the infimum, with the property that Conversely:




Any locally convex topological vector space has a local basis consisting of absolutely convex sets. A common method to construct such a basis is to use a family of seminorms that separates points: the collection of all finite intersections of sets turns the space into a locally convex topological vector space so that every p is continuous.


Such a method is used to design weak and weak* topologies.
norm case:
- Suppose now that contains a single since is separating, is a norm, and is its open unit ball. Then is an absolutely convex bounded neighbourhood of 0, and is continuous.



- The converse is due to Andrey Kolmogorov: any locally convex and locally bounded topological vector space is normable. Precisely:
- If is an absolutely convex bounded neighbourhood of 0, the gauge (so that is a norm.


See also
edit- Asymmetric norm – Generalization of the concept of a norm
- F-seminorm – A topological vector space whose topology can be defined by a metric
- Gowers norm
- Kadec norm – All infinite-dimensional, separable Banach spaces are homeomorphic
- Least-squares spectral analysis – Periodicity computation method
- Mahalanobis distance – Statistical distance measure
- Magnitude (mathematics) – Property determining comparison and ordering
- Matrix norm – Norm on a vector space of matrices
- Minkowski distance – Mathematical metric in normed vector space
- Minkowski functional – Function made from a set
- Operator norm – Measure of the "size" of linear operators
- Paranorm – A topological vector space whose topology can be defined by a metric
- Relation of norms and metrics – Mathematical space with a notion of distance
- Seminorm – nonnegative-real-valued function on a real or complex vector space that satisfies the triangle inequality and is absolutely homogenous
- Sublinear function – Type of function in linear algebra
References
edit- ^ a b Knapp, A.W. (2005). Basic Real Analysis. Birkhäuser. p. [1]. ISBN 978-0-817-63250-2.
- ^ "Pseudo-norm - Encyclopedia of Mathematics". encyclopediaofmath.org. Retrieved 2022-05-12.
- ^ "Pseudonorm". www.spektrum.de (in German). Retrieved 2022-05-12.
- ^ Hyers, D. H. (1939-09-01). "Pseudo-normed linear spaces and Abelian groups". Duke Mathematical Journal. 5 (3). doi:10.1215/s0012-7094-39-00551-x. ISSN 0012-7094.
- ^ Pugh, C.C. (2015). Real Mathematical Analysis. Springer. p. page 28. ISBN 978-3-319-17770-0. Prugovečki, E. (1981). Quantum Mechanics in Hilbert Space. p. page 20.
- ^ a b Kubrusly 2011, p. 200.
- ^ Rudin, W. (1991). Functional Analysis. p. 25.
- ^ Narici & Beckenstein 2011, pp. 120–121.
- ^ a b c Conrad, Keith. "Equivalence of norms" (PDF). kconrad.math.uconn.edu. Retrieved September 7, 2020.
- ^ Wilansky 2013, pp. 20–21.
- ^ a b c Weisstein, Eric W. "Vector Norm". mathworld.wolfram.com. Retrieved 2020-08-24.
- ^ Chopra, Anil (2012). Dynamics of Structures, 4th Ed. Prentice-Hall. ISBN 978-0-13-285803-8.
- ^ Weisstein, Eric W. "Norm". mathworld.wolfram.com. Retrieved 2020-08-24.
- ^ Except in where it coincides with the Euclidean norm, and where it is trivial.
- ^ Rolewicz, Stefan (1987), Functional analysis and control theory: Linear systems, Mathematics and its Applications (East European Series), vol. 29 (Translated from the Polish by Ewa Bednarczuk ed.), Dordrecht; Warsaw: D. Reidel Publishing Co.; PWN—Polish Scientific Publishers, pp. xvi, 524, doi:10.1007/978-94-015-7758-8, ISBN 90-277-2186-6, MR 0920371, OCLC 13064804
- ^ Lang, Serge (2002) [1993]. Algebra (Revised 3rd ed.). New York: Springer Verlag. p. 284. ISBN 0-387-95385-X.
- ^ Trèves 2006, pp. 242–243.
- ^ a b Golub, Gene; Van Loan, Charles F. (1996). Matrix Computations (Third ed.). Baltimore: The Johns Hopkins University Press. p. 53. ISBN 0-8018-5413-X.
- ^ Narici & Beckenstein 2011, pp. 107–113.
- ^ "Relation between p-norms". Mathematics Stack Exchange.


Bibliography
edit- Bourbaki, Nicolas (1987) [1981]. Topological Vector Spaces: Chapters 1–5. Éléments de mathématique. Translated by Eggleston, H.G.; Madan, S. Berlin New York: Springer-Verlag. ISBN 3-540-13627-4. OCLC 17499190.
- Khaleelulla, S. M. (1982). Counterexamples in Topological Vector Spaces. Lecture Notes in Mathematics. Vol. 936. Berlin, Heidelberg, New York: Springer-Verlag. ISBN 978-3-540-11565-6. OCLC 8588370.
- Kubrusly, Carlos S. (2011). The Elements of Operator Theory (Second ed.). Boston: Birkhäuser. ISBN 978-0-8176-4998-2. OCLC 710154895.
- Narici, Lawrence; Beckenstein, Edward (2011). Topological Vector Spaces. Pure and applied mathematics (Second ed.). Boca Raton, FL: CRC Press. ISBN 978-1584888666. OCLC 144216834.
- Schaefer, Helmut H.; Wolff, Manfred P. (1999). Topological Vector Spaces. GTM. Vol. 8 (Second ed.). New York, NY: Springer New York Imprint Springer. ISBN 978-1-4612-7155-0. OCLC 840278135.
- Trèves, François (2006) [1967]. Topological Vector Spaces, Distributions and Kernels. Mineola, N.Y.: Dover Publications. ISBN 978-0-486-45352-1. OCLC 853623322.
- Wilansky, Albert (2013). Modern Methods in Topological Vector Spaces. Mineola, New York: Dover Publications, Inc. ISBN 978-0-486-49353-4. OCLC 849801114.