


Summary
In numerical analysis, polynomial interpolation is the interpolation of a given bivariate data set by the polynomial of lowest possible degree that passes through the points of the dataset.[1]
Given a set of n + 1 data points , with no two the same, a polynomial function is said to interpolate the data if for each .





There is always a unique such polynomial, commonly given by two explicit formulas, the Lagrange polynomials and Newton polynomials.
Applications
editThe original use of interpolation polynomials was to approximate values of important transcendental functions such as natural logarithm and trigonometric functions. Starting with a few accurately computed data points, the corresponding interpolation polynomial will approximate the function at an arbitrary nearby point. Polynomial interpolation also forms the basis for algorithms in numerical quadrature (Simpson's rule) and numerical ordinary differential equations (multigrid methods).
In computer graphics, polynomials can be used to approximate complicated plane curves given a few specified points, for example the shapes of letters in typography. This is usually done with Bézier curves, which are a simple generalization of interpolation polynomials (having specified tangents as well as specified points).
In numerical analysis, polynomial interpolation is essential to perform sub-quadratic multiplication and squaring, such as Karatsuba multiplication and Toom–Cook multiplication, where interpolation through points on a product polynomial yields the specific product required. For example, given a = f(x) = a0x0 + a1x1 + ··· and b = g(x) = b0x0 + b1x1 + ···, the product ab is a specific value of W(x) = f(x)g(x). One may easily find points along W(x) at small values of x, and interpolation based on those points will yield the terms of W(x) and the specific product ab. As fomulated in Karatsuba multiplication, this technique is substantially faster than quadratic multiplication, even for modest-sized inputs, especially on parallel hardware.
In computer science, polynomial interpolation also leads to algorithms for secure multi party computation and secret sharing.
Interpolation theorem
editFor any bivariate data points , where no two are the same, there exists a unique polynomial of degree at most that interpolates these points, i.e. .[2]





Equivalently, for a fixed choice of interpolation nodes , polynomial interpolation defines a linear bijection between the (n+1)-tuples of real-number values and the vector space of real polynomials of degree at most n:




This is a type of unisolvence theorem. The theorem is also valid over any infinite field in place of the real numbers , for example the rational or complex numbers.

First proof
editConsider the Lagrange basis functions given by:


Notice that is a polynomial of degree , and we have for each , while . It follows that the linear combination: has , so is an interpolating polynomial of degree .






To prove uniqueness, assume that there exists another interpolating polynomial of degree at most , so that for all . Then is a polynomial of degree at most which has distinct zeros (the ). But a non-zero polynomial of degree at most can have at most zeros,[a] so must be the zero polynomial, i.e. .[3]






Second proof
editWrite out the interpolation polynomial in the form
| (1) |

Substituting this into the interpolation equations , we get a system of linear equations in the coefficients , which reads in matrix-vector form as the following multiplication:


An interpolant corresponds to a solution of the above matrix equation . The matrix X on the left is a Vandermonde matrix, whose determinant is known to be which is non-zero since the nodes are all distinct. This ensures that the matrix is invertible and the equation has the unique solution ; that is, exists and is unique.




Corollary
editIf is a polynomial of degree at most , then the interpolating polynomial of at distinct points is itself.

Constructing the interpolation polynomial
edit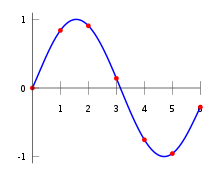
Lagrange Interpolation
editWe may write down the polynomial immediately in terms of Lagrange polynomials as: For matrix arguments, this formula is called Sylvester's formula and the matrix-valued Lagrange polynomials are the Frobenius covariants.
![{\displaystyle {\begin{aligned}p(x)&={\frac {(x-x_{1})(x-x_{2})\cdots (x-x_{n})}{(x_{0}-x_{1})(x_{0}-x_{2})\cdots (x_{0}-x_{n})}}y_{0}\\[4pt]&+{\frac {(x-x_{0})(x-x_{2})\cdots (x-x_{n})}{(x_{1}-x_{0})(x_{1}-x_{2})\cdots (x_{1}-x_{n})}}y_{1}\\[4pt]&+\cdots \\[4pt]&+{\frac {(x-x_{0})(x-x_{1})\cdots (x-x_{n-1})}{(x_{n}-x_{0})(x_{n}-x_{1})\cdots (x_{n}-x_{n-1})}}y_{n}\\[7pt]&=\sum _{i=0}^{n}{\Biggl (}\prod _{\stackrel {\!0\,\leq \,j\,\leq \,n}{j\,\neq \,i}}{\frac {x-x_{j}}{x_{i}-x_{j}}}{\Biggr )}y_{i}=\sum _{i=0}^{n}{\frac {p(x)}{p'(x_{i})(x-x_{i})}}\,y_{i}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/be0f2572bc5be17ca8fd929b1007302527f48dda)
Newton Interpolation
editTheorem
editFor a polynomial of degree less than or equal to n, that interpolates at the nodes where . Let be the polynomial of degree less than or equal to n+1 that interpolates at the nodes where . Then is given by: where also known as Newton basis and .









Proof:
This can be shown for the case where : and when : By the uniqueness of interpolated polynomials of degree less than , is the required polynomial interpolation. The function can thus be expressed as:





Polynomial coefficients
editTo find , we have to solve the lower triangular matrix formed by arranging from above equation in matrix form:



The coefficients are derived as
![{\displaystyle a_{j}:=[y_{0},\ldots ,y_{j}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f40744c93b8380df3b93026cedb3e03e51e3dd2e)
where
![{\displaystyle [y_{0},\ldots ,y_{j}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e845258d4c5470e5c7fdfdaab88ea5e9734aaf16)
is the notation for divided differences. Thus, Newton polynomials are used to provide a polynomial interpolation formula of n points.[3]
| Proof |
|---|
|
The first few coefficients can be calculated using the system of equations. The form of n-th coefficient is assumed for proof by mathematical induction.
Let Q be polynomial interpolation of points . Adding to the polynomial Q:
where . By uniqueness of the interpolating polynomial of the points , equating the coefficients of we get, . Hence the polynomial can be expressed as: Adding to the polynomial Q, it has to satisfiy: where the formula for and interpolating polynomial are used. The term for the polynomial can be found by calculating: which implies that . Hence it is proved by principle of mathematical induction. |
![{\displaystyle {\begin{aligned}a_{0}&=y_{0}=[y_{0}]\\a_{1}&={y_{1}-y_{0} \over x_{1}-x_{0}}=[y_{0},y_{1}]\\\vdots \\a_{n}&=[y_{0},\cdots ,y_{n}]\quad {\text{(let)}}\\\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/96894dfb37aecf78420fe33069ea351bb3706d19)





![{\textstyle a'_{n}=[y_{0},\ldots ,y_{n}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9d4a02adbe8ed05bfdae8874dd7f857e2fab3fba)
\cdot \ldots \cdot (x-x_{n}).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/10101a2d7cdcee1d8fd748aeb5afc7d8818c7fb7)

\cdot \ldots \cdot (x_{n+1}-x_{n})=y_{n+1}-Q(x_{n+1})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/996f7d7047b7a1a5f6bc06b2514c761fceb5f4c6)



\cdot \ldots \cdot (x_{n+1}-x_{n})\\&={\frac {[y_{1},\ldots ,y_{n+1}]-[y_{0},\ldots ,y_{n}]}{x_{n+1}-x_{0}}}(x_{n+1}-x_{0})\cdot \ldots \cdot (x_{n+1}-x_{n})\\&=\left([y_{1},\ldots ,y_{n+1}]-[y_{0},\ldots ,y_{n}]\right)(x_{n+1}-x_{1})\cdot \ldots \cdot (x_{n+1}-x_{n})\\&=[y_{1},\ldots ,y_{n+1}](x_{n+1}-x_{1})\cdot \ldots \cdot (x_{n+1}-x_{n})-[y_{0},\ldots ,y_{n}](x_{n+1}-x_{1})\cdot \ldots \cdot (x_{n+1}-x_{n})\\&=(y_{n+1}-Q(x_{n+1}))-[y_{0},\ldots ,y_{n}](x_{n+1}-x_{1})\cdot \ldots \cdot (x_{n+1}-x_{n})\\&=y_{n+1}-(Q(x_{n+1})+[y_{0},\ldots ,y_{n}](x_{n+1}-x_{1})\cdot \ldots \cdot (x_{n+1}-x_{n}))\\&=y_{n+1}-P(x_{n+1}).\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ea80ccc10f4a7ca7ab94079d042cd31c9944f03c)
![{\displaystyle a_{n+1}={y_{n+1}-P_{n}(x_{n+1}) \over w_{n}(x_{n+1})}=[y_{0},\ldots ,y_{n+1}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fd7959b7e8bd0f08b2dc422c41efc6da4065717f)
Newton forward formula
editThe Newton polynomial can be expressed in a simplified form when are arranged consecutively with equal spacing.

If are consecutively arranged and equally spaced with for i = 0, 1, ..., k and some variable x is expressed as , then the difference can be written as . So the Newton polynomial becomes




![{\displaystyle {\begin{aligned}N(x)&=[y_{0}]+[y_{0},y_{1}]sh+\cdots +[y_{0},\ldots ,y_{k}]s(s-1)\cdots (s-k+1){h}^{k}\\&=\sum _{i=0}^{k}s(s-1)\cdots (s-i+1){h}^{i}[y_{0},\ldots ,y_{i}]\\&=\sum _{i=0}^{k}{s \choose i}i!{h}^{i}[y_{0},\ldots ,y_{i}].\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/acde564918807b08c1c38188d11e9047abee1176)
Since the relationship between divided differences and forward differences is given as:[4] Taking , if the representation of x in the previous sections was instead taken to be , the Newton forward interpolation formula is expressed as: which is the interpolation of all points after . It is expanded as:
![{\displaystyle [y_{j},y_{j+1},\ldots ,y_{j+n}]={\frac {1}{n!h^{n}}}\Delta ^{(n)}y_{j},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ee85989d232921008c4803b4d1784ccbedeebb1a)




Newton backward formula
editIf the nodes are reordered as , the Newton polynomial becomes

![{\displaystyle N(x)=[y_{k}]+[{y}_{k},{y}_{k-1}](x-{x}_{k})+\cdots +[{y}_{k},\ldots ,{y}_{0}](x-{x}_{k})(x-{x}_{k-1})\cdots (x-{x}_{1}).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0f765e4be03523cff51f10707516961d29d30116)
If are equally spaced with for i = 0, 1, ..., k and , then,



![{\displaystyle {\begin{aligned}N(x)&=[{y}_{k}]+[{y}_{k},{y}_{k-1}]sh+\cdots +[{y}_{k},\ldots ,{y}_{0}]s(s+1)\cdots (s+k-1){h}^{k}\\&=\sum _{i=0}^{k}{(-1)}^{i}{-s \choose i}i!{h}^{i}[{y}_{k},\ldots ,{y}_{k-i}].\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/833c298afa842a34145ce3631ae774b5712e2675)
Since the relationship between divided differences and backward differences is given as:[citation needed] taking , if the representation of x in the previous sections was instead taken to be , the Newton backward interpolation formula is expressed as: which is the interpolation of all points before . It is expanded as:
![{\displaystyle [{y}_{j},y_{j-1},\ldots ,{y}_{j-n}]={\frac {1}{n!h^{n}}}\nabla ^{(n)}y_{j},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/87599e592c9523e601c830c9f73cb21263beb083)


Lozenge Diagram
editA Lozenge diagram is a diagram that is used to describe different interpolation formulas that can be constructed for a given data set. A line starting on the left edge and tracing across the diagram to the right can be used to represent an interpolation formula if the following rules are followed:[5]

- Left to right steps indicate addition whereas right to left steps indicate subtraction
- If the slope of a step is positive, the term to be used is the product of the difference and the factor immediately below it. If the slope of a step is negative, the term to be used is the product of the difference and the factor immediately above it.
- If a step is horizontal and passes through a factor, use the product of the factor and the average of the two terms immediately above and below it. If a step is horizontal and passes through a difference, use the product of the difference and the average of the two terms immediately above and below it.
The factors are expressed using the formula:

Proof of equivalence
editIf a path goes from to , it can connect through three intermediate steps, (a) through , (b) through or (c) through . Proving the equivalence of these three two-step paths should prove that all (n-step) paths can be morphed with the same starting and ending, all of which represents the same formula.





Path (a):

Path (b):

Path (c):

Subtracting contributions from path a and b:

Thus, the contribution of either path (a) or path (b) is the same. Since path (c) is the average of path (a) and (b), it also contributes identical function to the polynomial. Hence the equivalence of paths with same starting and ending points is shown. To check if the paths can be shifted to different values in the leftmost corner, taking only two step paths is sufficient: (a) to through or (b) factor between and , to through or (c) starting from .



Path (a)

Path (b)

Path (c)
Since , substituting in the above equations shows that all the above terms reduce to and are hence equivalent. Hence these paths can be morphed to start from the leftmost corner and end in a common point.[5]

Newton formula
editTaking negative slope transversal from to gives the interpolation formula of all the consecutively arranged points, equivalent to Newton's forward interpolation formula:



whereas, taking positive slope transversal from to , gives the interpolation formula of all the consecutively arranged points, equivalent to Newton's backward interpolation formula:



where is the number corresponding to that introduced in Newton interpolation.

Gauss formula
editTaking a zigzag line towards the right starting from with negative slope, we get Gauss forward formula:

whereas starting from with positive slope, we get Gauss backward formula:

Stirling formula
editBy taking a horizontal path towards the right starting from , we get Stirling formula:

Stirling formula is the average of Gauss forward and Gauss backward formulas.
Bessel formula
editBy taking a horizontal path towards the right starting from factor between and , we get Stirling formula:


Vandermonde Algorithms
editThe Vandermonde matrix in the second proof above may have large condition number,[6] causing large errors when computing the coefficients ai if the system of equations is solved using Gaussian elimination.
Several authors have therefore proposed algorithms which exploit the structure of the Vandermonde matrix to compute numerically stable solutions in O(n2) operations instead of the O(n3) required by Gaussian elimination.[7][8][9] These methods rely on constructing first a Newton interpolation of the polynomial and then converting it to a monomial form.
Non-Vandermonde algorithms
editTo find the interpolation polynomial p(x) in the vector space P(n) of polynomials of degree n, we may use the usual monomial basis for P(n) and invert the Vandermonde matrix by Gaussian elimination, giving a computational cost of O(n3) operations. To improve this algorithm, a more convenient basis for P(n) can simplify the calculation of the coefficients, which must then be translated back in terms of the monomial basis.
One method is to write the interpolation polynomial in the Newton form (i.e. using Newton basis) and use the method of divided differences to construct the coefficients, e.g. Neville's algorithm. The cost is O(n2) operations. Furthermore, you only need to do O(n) extra work if an extra point is added to the data set, while for the other methods, you have to redo the whole computation.
Another method is preferred when the aim is not to compute the coefficients of p(x), but only a single value p(a) at a point x = a not in the original data set. The Lagrange form computes the value p(a) with complexity O(n2).[10]
The Bernstein form was used in a constructive proof of the Weierstrass approximation theorem by Bernstein and has gained great importance in computer graphics in the form of Bézier curves.
Interpolations as linear combinations of values
editGiven a set of (position, value) data points where no two positions are the same, the interpolating polynomial may be considered as a linear combination of the values , using coefficients which are polynomials in depending on the . For example, the interpolation polynomial in the Lagrange form is the linear combination with each coefficient given by the corresponding Lagrange basis polynomial on the given positions :







Since the coefficients depend only on the positions , not the values , we can use the same coefficients to find the interpolating polynomial for a second set of data points at the same positions:


Furthermore, the coefficients only depend on the relative spaces between the positions. Thus, given a third set of data whose points are given by the new variable (an affine transformation of , inverted by ):




we can use a transformed version of the previous coefficient polynomials:

and write the interpolation polynomial as:

Data points often have equally spaced positions, which may be normalized by an affine transformation to . For example, consider the data points


.

The interpolation polynomial in the Lagrange form is the linear combination

For example, and .


The case of equally spaced points can also be treated by the method of finite differences. The first difference of a sequence of values is the sequence defined by . Iterating this operation gives the nth difference operation , defined explicitly by: where the coefficients form a signed version of Pascal's triangle, the triangle of binomial transform coefficients:





| 1 | Row n = 0 | ||||||||||||||||
| 1 | −1 | Row n = 1 or d = 0 | |||||||||||||||
| 1 | −2 | 1 | Row n = 2 or d = 1 | ||||||||||||||
| 1 | −3 | 3 | −1 | Row n = 3 or d = 2 | |||||||||||||
| 1 | −4 | 6 | −4 | 1 | Row n = 4 or d = 3 | ||||||||||||
| 1 | −5 | 10 | −10 | 5 | −1 | Row n = 5 or d = 4 | |||||||||||
| 1 | −6 | 15 | −20 | 15 | −6 | 1 | Row n = 6 or d = 5 | ||||||||||
| 1 | −7 | 21 | −35 | 35 | −21 | 7 | −1 | Row n = 7 or d = 6 | |||||||||
A polynomial of degree d defines a sequence of values at positive integer points, , and the difference of this sequence is identically zero:


.

Thus, given values at equally spaced points, where , we have: For example, 4 equally spaced data points of a quadratic obey , and solving for gives the same interpolation equation obtained above using the Lagrange method.






Interpolation error: Lagrange remainder formula
editWhen interpolating a given function f by a polynomial of degree n at the nodes x0,..., xn we get the error
![{\displaystyle f(x)-p_{n}(x)=f[x_{0},\ldots ,x_{n},x]\prod _{i=0}^{n}(x-x_{i})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/20e8c5d91ab5d500891ea9c0b0b528881dde5b08)
where is the (n+1)st divided difference of the data points
![{\textstyle f[x_{0},\ldots ,x_{n},x]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e9429273fee3907bbb1b06a1953a8784f3b63cd7)
.

Furthermore, there is a Lagrange remainder form of the error, for a function f which is n + 1 times continuously differentiable on a closed interval , and a polynomial of degree at most n that interpolates f at n + 1 distinct points . For each there exists such that






This error bound suggests choosing the interpolation points xi to minimize the product , which is achieved by the Chebyshev nodes.

Proof of Lagrange remainder
editSet the error term as , and define an auxiliary function: Thus:



But since is a polynomial of degree at most n, we have , and:


Now, since xi are roots of and , we have , which means Y has at least n + 2 roots. From Rolle's theorem, has at least n + 1 roots, and iteratively has at least one root ξ in the interval I. Thus:






and:

This parallels the reasoning behind the Lagrange remainder term in the Taylor theorem; in fact, the Taylor remainder is a special case of interpolation error when all interpolation nodes xi are identical.[11] Note that the error will be zero when for any i. Thus, the maximum error will occur at some point in the interval between two successive nodes.

Equally spaced intervals
editIn the case of equally spaced interpolation nodes where , for and where the product term in the interpolation error formula can be bound as[12]




Thus the error bound can be given as
![{\displaystyle \left|R_{n}(x)\right|\leq {\frac {h^{n+1}}{4(n+1)}}\max _{\xi \in [a,b]}\left|f^{(n+1)}(\xi )\right|}](https://wikimedia.org/api/rest_v1/media/math/render/svg/34dc247e57d4dcc78f9484b320ed389b1ddb375c)
However, this assumes that is dominated by , i.e. . In several cases, this is not true and the error actually increases as n → ∞ (see Runge's phenomenon). That question is treated in the section Convergence properties.



Lebesgue constants
editWe fix the interpolation nodes x0, ..., xn and an interval [a, b] containing all the interpolation nodes. The process of interpolation maps the function f to a polynomial p. This defines a mapping X from the space C([a, b]) of all continuous functions on [a, b] to itself. The map X is linear and it is a projection on the subspace of polynomials of degree n or less.
The Lebesgue constant L is defined as the operator norm of X. One has (a special case of Lebesgue's lemma):

In other words, the interpolation polynomial is at most a factor (L + 1) worse than the best possible approximation. This suggests that we look for a set of interpolation nodes that makes L small. In particular, we have for Chebyshev nodes:

We conclude again that Chebyshev nodes are a very good choice for polynomial interpolation, as the growth in n is exponential for equidistant nodes. However, those nodes are not optimal.
Convergence properties
editIt is natural to ask, for which classes of functions and for which interpolation nodes the sequence of interpolating polynomials converges to the interpolated function as n → ∞? Convergence may be understood in different ways, e.g. pointwise, uniform or in some integral norm.
The situation is rather bad for equidistant nodes, in that uniform convergence is not even guaranteed for infinitely differentiable functions. One classical example, due to Carl Runge, is the function f(x) = 1 / (1 + x2) on the interval [−5, 5]. The interpolation error || f − pn||∞ grows without bound as n → ∞. Another example is the function f(x) = |x| on the interval [−1, 1], for which the interpolating polynomials do not even converge pointwise except at the three points x = ±1, 0.[13]
One might think that better convergence properties may be obtained by choosing different interpolation nodes. The following result seems to give a rather encouraging answer:
Theorem — For any function f(x) continuous on an interval [a,b] there exists a table of nodes for which the sequence of interpolating polynomials converges to f(x) uniformly on [a,b].
It is clear that the sequence of polynomials of best approximation converges to f(x) uniformly (due to the Weierstrass approximation theorem). Now we have only to show that each may be obtained by means of interpolation on certain nodes. But this is true due to a special property of polynomials of best approximation known from the equioscillation theorem. Specifically, we know that such polynomials should intersect f(x) at least n + 1 times. Choosing the points of intersection as interpolation nodes we obtain the interpolating polynomial coinciding with the best approximation polynomial.

The defect of this method, however, is that interpolation nodes should be calculated anew for each new function f(x), but the algorithm is hard to be implemented numerically. Does there exist a single table of nodes for which the sequence of interpolating polynomials converge to any continuous function f(x)? The answer is unfortunately negative:
Theorem — For any table of nodes there is a continuous function f(x) on an interval [a, b] for which the sequence of interpolating polynomials diverges on [a,b].[14]
The proof essentially uses the lower bound estimation of the Lebesgue constant, which we defined above to be the operator norm of Xn (where Xn is the projection operator on Πn). Now we seek a table of nodes for which
![{\displaystyle \lim _{n\to \infty }X_{n}f=f,{\text{ for every }}f\in C([a,b]).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dee3b117b4b32fbb477a4ffb88e213b0177e9b25)
Due to the Banach–Steinhaus theorem, this is only possible when norms of Xn are uniformly bounded, which cannot be true since we know that

For example, if equidistant points are chosen as interpolation nodes, the function from Runge's phenomenon demonstrates divergence of such interpolation. Note that this function is not only continuous but even infinitely differentiable on [−1, 1]. For better Chebyshev nodes, however, such an example is much harder to find due to the following result:
Theorem — For every absolutely continuous function on [−1, 1] the sequence of interpolating polynomials constructed on Chebyshev nodes converges to f(x) uniformly.[15]
Related concepts
editRunge's phenomenon shows that for high values of n, the interpolation polynomial may oscillate wildly between the data points. This problem is commonly resolved by the use of spline interpolation. Here, the interpolant is not a polynomial but a spline: a chain of several polynomials of a lower degree.
Interpolation of periodic functions by harmonic functions is accomplished by Fourier transform. This can be seen as a form of polynomial interpolation with harmonic base functions, see trigonometric interpolation and trigonometric polynomial.
Hermite interpolation problems are those where not only the values of the polynomial p at the nodes are given, but also all derivatives up to a given order. This turns out to be equivalent to a system of simultaneous polynomial congruences, and may be solved by means of the Chinese remainder theorem for polynomials. Birkhoff interpolation is a further generalization where only derivatives of some orders are prescribed, not necessarily all orders from 0 to a k.
Collocation methods for the solution of differential and integral equations are based on polynomial interpolation.
The technique of rational function modeling is a generalization that considers ratios of polynomial functions.
At last, multivariate interpolation for higher dimensions.
See also
editNotes
edit- ^ This follows from the Factor theorem for polynomial division.
Citations
edit- ^ Tiemann, Jerome J. (May–June 1981). "Polynomial Interpolation". I/O News. 1 (5): 16. ISSN 0274-9998. Retrieved 3 November 2017.
- ^ Humpherys, Jeffrey; Jarvis, Tyler J. (2020). "9.2 - Interpolation". Foundations of Applied Mathematics Volume 2: Algorithms, Approximation, Optimization. Society for Industrial and Applied Mathematics. p. 418. ISBN 978-1-611976-05-2.
- ^ a b Epperson, James F. (2013). An introduction to numerical methods and analysis (2nd ed.). Hoboken, NJ: Wiley. ISBN 978-1-118-36759-9.
- ^ Burden, Richard L.; Faires, J. Douglas (2011). Numerical Analysis (9th ed.). p. 129. ISBN 9780538733519.
- ^ a b Hamming, Richard W. (1986). Numerical methods for scientists and engineers (Unabridged republ. of the 2. ed. (1973) ed.). New York: Dover. ISBN 978-0-486-65241-2.
- ^ Gautschi, Walter (1975). "Norm Estimates for Inverses of Vandermonde Matrices". Numerische Mathematik. 23 (4): 337–347. doi:10.1007/BF01438260. S2CID 122300795.
- ^ Higham, N. J. (1988). "Fast Solution of Vandermonde-Like Systems Involving Orthogonal Polynomials". IMA Journal of Numerical Analysis. 8 (4): 473–486. doi:10.1093/imanum/8.4.473.
- ^ Björck, Å; V. Pereyra (1970). "Solution of Vandermonde Systems of Equations". Mathematics of Computation. 24 (112). American Mathematical Society: 893–903. doi:10.2307/2004623. JSTOR 2004623.
- ^ Calvetti, D.; Reichel, L. (1993). "Fast Inversion of Vandermonde-Like Matrices Involving Orthogonal Polynomials". BIT. 33 (3): 473–484. doi:10.1007/BF01990529. S2CID 119360991.
- ^ R.Bevilaqua, D. Bini, M.Capovani and O. Menchi (2003). Appunti di Calcolo Numerico. Chapter 5, p. 89. Servizio Editoriale Universitario Pisa - Azienda Regionale Diritto allo Studio Universitario.
- ^ "Errors in Polynomial Interpolation" (PDF).
- ^ "Notes on Polynomial Interpolation" (PDF).
- ^ Watson (1980, p. 21) attributes the last example to Bernstein (1912).
- ^ Watson (1980, p. 21) attributes this theorem to Faber (1914).
- ^ Krylov, V. I. (1956). "Сходимость алгебраического интерполирования покорням многочленов Чебышева для абсолютно непрерывных функций и функций с ограниченным изменением" [Convergence of algebraic interpolation with respect to the roots of Chebyshev's polynomial for absolutely continuous functions and functions of bounded variation]. Doklady Akademii Nauk SSSR. New Series (in Russian). 107: 362–365. MR 18-32.
References
edit- Bernstein, Sergei N. (1912). "Sur l'ordre de la meilleure approximation des fonctions continues par les polynômes de degré donné" [On the order of the best approximation of continuous functions by polynomials of a given degree]. Mem. Acad. Roy. Belg. (in French). 4: 1–104.
- Faber, Georg (1914). "Über die interpolatorische Darstellung stetiger Funktionen" [On the Interpolation of Continuous Functions]. Deutsche Math. Jahr. (in German). 23: 192–210.
- Watson, G. Alistair (1980). Approximation Theory and Numerical Methods. John Wiley. ISBN 0-471-27706-1.
Further reading
edit- Atkinson, Kendell A. (1988). "Chapter 3.". An Introduction to Numerical Analysis (2nd ed.). John Wiley and Sons. ISBN 0-471-50023-2.
- Brutman, L. (1997). "Lebesgue functions for polynomial interpolation — a survey". Ann. Numer. Math. 4: 111–127.
- Powell, M. J. D. (1981). "Chapter 4". Approximation Theory and Methods. Cambridge University Press. ISBN 0-521-29514-9.
- Schatzman, Michelle (2002). "Chapter 4". Numerical Analysis: A Mathematical Introduction. Oxford: Clarendon Press. ISBN 0-19-850279-6.
- Süli, Endre; Mayers, David (2003). "Chapter 6". An Introduction to Numerical Analysis. Cambridge University Press. ISBN 0-521-00794-1.
External links
edit- "Interpolation process", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- ALGLIB has an implementations in C++ / C#.
- GSL has a polynomial interpolation code in C
- Polynomial Interpolation demonstration.