


Summary
Project Gutenberg (PG) is a volunteer effort to digitize and archive cultural works, as well as to "encourage the creation and distribution of eBooks."[2] It was founded in 1971 by American writer Michael S. Hart and is the oldest digital library.[3] Most of the items in its collection are the full texts of books or individual stories in the public domain. All files can be accessed for free under an open format layout, available on almost any computer. As of 13 February 2024[update], Project Gutenberg had reached 70,000 items in its collection of free eBooks.[4]
| Project Gutenberg | |
|---|---|
| Established | December 1971 (first document posted)[1] |
| Collection | |
| Size | Over 72,500 documents |
| Other information | |
| Website | gutenberg |
The releases are available in plain text as well as other formats, such as HTML, PDF, EPUB, MOBI, and Plucker wherever possible. Most releases are in the English language, but many non-English works are also available. There are multiple affiliated projects that provide additional content, including region- and language-specific works. Project Gutenberg is closely affiliated with Distributed Proofreaders, an Internet-based community for proofreading scanned texts.
Project Gutenberg is named after the inventor Johannes Gutenberg, whose works in developing printing technology led to an increase in the mass availability of books and other text.
History
edit
Michael S. Hart began Project Gutenberg in 1971 with the digitization of the United States Declaration of Independence.[5] Hart, a student at the University of Illinois, obtained access to a Xerox Sigma V mainframe computer in the university's Materials Research Lab. Through friendly operators, he received an account with a virtually unlimited amount of computer time; its value at that time has since been variously estimated at $100,000 or $100,000,000.[6] Hart explained he wanted to "give back" this gift by doing something one could consider to be of great value. His initial goal was to make the 10,000 most consulted books available to the public at little or no charge by the end of the 20th century.[7]
On July 4, 1971, after being inspired by a free printed copy of the U.S. Declaration of Independence, he decided to type the text into a computer, and to transmit it to other users on the computer network.
- — Gregory B. Newby[8]
This particular computer was one of the 15 nodes on ARPANET, the computer network that would become the Internet. Hart believed one day the general public would be able to access computers and decided to make works of literature available in electronic form for free. He used a copy of the United States Declaration of Independence in his backpack, and this became the first Project Gutenberg e-text. He named the project for Johannes Gutenberg, the fifteenth century German printer who propelled the movable type printing press revolution.
By the mid-1990s, Hart was running Project Gutenberg from Illinois Benedictine College. More volunteers had joined the effort. He manually entered all of the text until 1989 when image scanners and optical character recognition software improved and became more available, making book scanning more feasible.[9] Hart later came to an arrangement with Carnegie Mellon University, which agreed to administer Project Gutenberg's finances. As the volume of e-texts increased, volunteers began to take over the project's day-to-day operations that Hart had run.
Italian volunteer Pietro Di Miceli developed and administered the first Project Gutenberg website and started the development of the Project online Catalog. In his ten years in this role (1994–2004), the Project web pages won a number of awards, often being featured in "best of the Web" listings, contributing to the project's popularity.[10]
Starting in 2004, an improved online catalog made Project Gutenberg content easier to browse, access and hyperlink. Project Gutenberg is now hosted by ibiblio at the University of North Carolina at Chapel Hill.
Hart died on 6 September 2011 at his home in Urbana, Illinois, at the age of 64.[11]
CD and DVD project
editIn August 2003, Project Gutenberg created a CD containing approximately 600 of the "best" e-books from the collection. The CD is available for download as an ISO image. When users are unable to download the CD, they can request to have a copy sent to them, free of charge.
In December 2003, a DVD was created containing nearly 10,000 items. At the time, this represented almost the entire collection. In early 2004, the DVD also became available by mail.
In July 2007, a new edition of the DVD was released containing over 17,000 books, and in April 2010, a dual-layer DVD was released, containing nearly 30,000 items.
The majority of the DVDs, and all of the CDs mailed by the project, were recorded on recordable media by volunteers. However, the new dual layer DVDs were manufactured, as it proved more economical than having volunteers burn them. As of October 2010[update], the project has mailed approximately 40,000 discs. As of 2017, the delivery of free CDs has been discontinued, though the ISO image is still available for download.[12]
Scope of collection
edit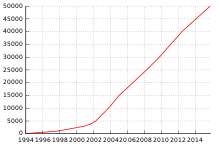
As of August 2015[update], Project Gutenberg claimed over 72,500 items in its collection, with an average of over 50 new e-books being added each week.[13] These are primarily works of literature from the Western cultural tradition. In addition to literature such as novels, poetry, short stories and drama, Project Gutenberg also has cookbooks, reference works and issues of periodicals.[14] The Project Gutenberg collection also has a few non-text items such as audio files and music-notation files.[15]
Most releases are in English, but there are also significant numbers in many other languages. As of April 2016[update], the non-English languages most represented are: French, German, Finnish, Dutch, Italian, and Portuguese.[3]
Whenever possible, Gutenberg releases are available in plain text, mainly using US-ASCII character encoding but frequently extended to ISO-8859-1 (needed to represent accented characters in French and Scharfes s in German, for example). Besides being copyright-free, the requirement for a Latin (character set) text version of the release had been a criterion of Michael Hart's since the founding of Project Gutenberg, as he believed it was the format most likely to be readable in the extended future.[16] Out of necessity, this criterion has had to be extended further for the sizable collection of texts in East Asian languages such as Chinese and Japanese now in the collection, where UTF-8 is used instead.
Other formats may be released as well when submitted by volunteers. The most common non-ASCII format is HTML, which allows markup and illustrations to be included. Some project members and users have requested more advanced formats, believing them to be easier to read. But some formats that are not easily editable, such as PDF, are generally not considered to fit with the goals of Project Gutenberg. Also Project Gutenberg has two options for master formats that can be submitted (from which all other files are generated): customized versions of the Text Encoding Initiative standard (since 2005)[17] and reStructuredText (since 2011).[18]
Beginning in 2009, the Project Gutenberg catalog began offering auto-generated alternate file formats, including HTML (when not already provided), EPUB and plucker.[19]
Ideals
editMichael Hart said in 2004, "The mission of Project Gutenberg is simple: 'To encourage the creation and distribution of ebooks'".[2] His goal was "to provide as many e-books in as many formats as possible for the entire world to read in as many languages as possible".[3] Likewise, a project slogan is to "break down the bars of ignorance and illiteracy",[20] because its volunteers aim to continue spreading public literacy and appreciation for the literary heritage just as public libraries began to do in the late 19th century.[21][22]
Project Gutenberg is intentionally decentralized; there is no selection policy dictating what texts to add. Instead, individual volunteers work on what they are interested in, or have available. The Project Gutenberg collection is intended to preserve items for the long term, so they cannot be lost by any one localized accident. In an effort to ensure this, the entire collection is backed-up regularly and mirrored on servers in many different locations.[23]
Copyright
editProject Gutenberg is careful to verify the status of its ebooks according to United States copyright law. Material is added to the Project Gutenberg archive only after it has received a copyright clearance, and records of these clearances are saved for future reference. Project Gutenberg does not claim new copyright on titles it publishes. Instead, it encourages their free reproduction and distribution.[3]
Most books in the Project Gutenberg collection are distributed as public domain under United States copyright law. There are also a few copyrighted texts, such as those of science fiction author Cory Doctorow, that Project Gutenberg distributes with permission. These are subject to further restrictions as specified by the copyright holder, although they generally tend to be licensed under Creative Commons.
"Project Gutenberg" is a trademark of the organization, and the mark cannot be used in commercial or modified redistributions of public domain texts from the project. There is no legal impediment to the reselling of works in the public domain if all references to Project Gutenberg are removed, but Gutenberg contributors have questioned the appropriateness of directly and commercially reusing content that has been formatted by volunteers. There have been instances of books being stripped of attribution to the project and sold for profit in the Kindle Store and other booksellers, one being the 1906 book Fox Trapping.[24]
From 2018 to 2021, the Project Gutenberg website was not accessible within Germany, as a result of a court order from S. Fischer Verlag regarding the works of Heinrich Mann, Thomas Mann and Alfred Döblin. Although they were in the public domain in the United States, the German court (Frankfurt am Main Regional Court) recognized the infringement of copyrights still active in Germany, and asserted that the Project Gutenberg website was under German jurisdiction because it hosts content in the German language and is accessible in Germany.[25] This judgment was confirmed by the Frankfurt Court of Appeal on 30 April 2019 (11 U 27/18[26]). The Frankfurt Court of Appeal has not given permission for a further appeal to the Federal Court of Justice (Bundesgerichtshof), however, an application for permission to appeal has been filed with the Federal Court of Justice. As of 4 October 2020 that application was still pending (Federal Court of Justice I ZR 97/19). According to Project Gutenberg Literary Archive Foundation,[27] "In October 2021, the parties reached a settlement agreement. Under the terms of the agreement, Project Gutenberg eBooks by the three authors will be blocked from Germany until their German copyright expires. Under the terms of the settlement, the all-Germany block is no longer in place. Other terms of the settlement are confidential."
The Project Gutenberg website has been blocked in Italy since May 2020, as part of a larger effort to block websites that publish newspapers and journals that are protected by copyright in Italy.[28]
Criticism
editThe text files use the format of plain text encoded in UTF-8 and are typically wrapped at 65–70 characters, with paragraphs separated by a double line break. In recent decades, the resulting appearance and the lack of a markup possibility have often been perceived as bland and as a drawback of this format.[29] Project Gutenberg attempts to address this by making many texts available in HTML, ePub, and PDF versions as well. HTML versions of older texts are autogenerated versions. Another not-for-profit project, Standard Ebooks, aims to address these issues with its collection of public domain titles that are formatted and styled. It corrects issues related to design and typography.[30]
In December 1994, Project Gutenberg was criticized by the Text Encoding Initiative for failing to include documentation or discussion of the decisions unavoidable in preparing a text, or in some cases, not documenting which of several (conflicting) versions of a text has been the one digitized.[31]
The selection of works (and editions) available has been determined by popularity, ease of scanning, being out of copyright, and other factors; this would be difficult to avoid in any crowd-sourced project.[32]
In March 2004, an initiative was begun by Michael Hart and John S. Guagliardo[33] to provide low-cost intellectual properties. The initial name for this project was Project Gutenberg 2 (PG II), which created controversy among PG volunteers because of the re-use of the project's trademarked name for a commercial venture.[34]
Project Gutenberg Literary Archive Foundation
editIn 2000, a non-profit corporation, the Project Gutenberg Literary Archive Foundation, Inc.[35][36] 501(c)(3) EIN: 64-6221541[37] was chartered in Mississippi,[38] United States, to handle the project's legal[39] needs. Donations to it are tax-deductible.[40]
Gregory B. Newby,[41][42][43][44][45][46] while Assistant Professor at UNC School of Information and Library Science, and a long-time Project Gutenberg volunteer,[47] in 2001, became the foundation's first CEO,[34][48] later Arctic Region Supercomputing Center Director, later Compute Canada's Chief Technology Officer.[49][50][51][52][53]
Partners
edit- Project Gutenberg Consortia Center specializes in collections of collections. These do not have the editorial oversight or consistent formatting of the main Project Gutenberg. Thematic collections, as well as numerous languages, are featured.[54] This is sponsored by worldlibrary.net, which hosts self.gutenberg.org, a self-publishing portal.[55]
- ibiblio, at the University of North Carolina at Chapel Hill, now hosts Project Gutenberg[55]
- Distributed Proofreaders: In 2000, Charles Franks founded Distributed Proofreaders (DP), which allowed the proofreading of scanned texts to be distributed among many volunteers over the Internet. This effort increased the number and variety of texts being added to Project Gutenberg, as well as making it easier for new volunteers to start contributing. DP became officially affiliated with Project Gutenberg in 2002.[56] As of 2018[update], the 36,000+ DP-contributed books comprised almost two-thirds of the nearly 72,500 books in Project Gutenberg.[55]
Sister projects
editAll sister projects[55] are independent organizations that share the same ideals and have been given permission to use the Project Gutenberg trademark. They often have a particular national or linguistic focus.[57]
List of sister projects
edit- Project Gutenberg Australia hosts many texts that are public domain according to copyright law of Australia, but still under copyright (or of uncertain status) in the United States, with a focus on Australian writers and books about Australia.[58][55]
- Project Gutenberg Canada.[59][55] digital library for Canadian public domain texts.
- Projekt Gutenberg-DE claims copyright for its product and limits access to browsable web-versions of its texts.[60][55]
- Project Gutenberg Europe is run by Project Rastko in Serbia. It aims at being a Project Gutenberg for all of Europe, and began posting projects in 2005. It uses the Distributed Proofreaders software to quickly produce etexts.[61]
- Project Gutenberg Luxembourg publishes mostly, but not exclusively, books that are written in Luxembourgish.[62]
- Projekti Lönnrot, started by Finnish Project Gutenberg volunteers, derives its name from the Finnish philologist Elias Lönnrot (1802–1884)[63]
- Project Gutenberg of the Philippines aims to "make as many books available to as many people as possible, with a special focus on the Philippines and Philippine languages".[64]
- Project Gutenberg Russia (Rutenberg) aims to collect public domain books in Slavic languages, particularly in Russian. The discussion of the project and its legal side began in April 2012. The word Rutenberg is a combination of words "Russia" and "Gutenberg".[65]
- Project Gutenberg Self Publishing Portal also known as Project Gutenberg Self-Publishing Press, by the Project Gutenberg Consortia Center[55][66] Unlike the Gutenberg Project itself, Project Gutenberg Self-Publishing allows submission of texts never published before, including self-published ebooks.[67] Launched in 2012,[66][68] also owns the "gutenberg.us" domain.[69]
- Project Gutenberg of Taiwan seeks to archive copyright free books with a special focus on Taiwan in English, Mandarin and Taiwan-based languages. It is a special project of Forumosa.com[70]
- Projekt Runeberg, Nordic literature[55]
- ReadingRoo.ms, the home of the Project Gutenberg PrePrints[55]
- Distributed Proofreaders Canada, a separate entity, launched in December 2007, by David Jones and Michael Shepard.
- Faded Page Distributed Proofreaders Canada public domain book archive
Affiliates
edit- The Internet Archive, previous long-time backup distribution site, and previous main host site.[55]
- Librivox.org, new audioBooks main partner[55]
See also
edit- Aozora Bunko
- Miguel de Cervantes Virtual Library
- Chinese Text Project
- Google Books
- HathiTrust
- Internet Archive
- LibriVox—free online audiobook library, with many texts used from Project Gutenberg
- List of digital library projects
- On-line Guitar Archive
- Open Content Alliance
- Project Runeberg, for books significant to the culture and history of the Nordic countries.
- Runivers, for Russian historical documents
- Sefaria, for Jewish texts
- Standard Ebooks
- Virtual volunteering
- Wikisource
References
edit- ^
Hart, Michael S. United States Declaration of Independence by United States. Project Gutenberg. Archived from the original on 26 January 2007. Retrieved 17 February 2007.
"The Declaration of Independence of the United States of America by Thomas Jefferson" is the bold heading of the linked webpage twelve years later (6 June 2019). No author but Jefferson is identified, nor is Hart otherwise named. Officially this is Project Gutenberg Ebook #1 (assigned December 1993?), or the current index to multiple formats of the same.
What Ebook #1 actually contains is heavily annotated re-release of the first two e-texts that were released in December 1971 (as by Michael S. Hart?). For more information, open the HTML format, for instance, and search for "December" or "Michael". - ^ a b Hart, Michael S. (23 October 2004). "Gutenberg Mission Statement by Michael Hart". Project Gutenberg. Archived from the original on 14 July 2007. Retrieved 15 August 2007.
- ^ a b c d Thomas, Jeffrey (20 July 2007). "Project Gutenberg Digital Library Seeks To Spur Literacy". US Department of State, Bureau of International Information Programs. Archived from the original on 14 March 2008. Retrieved 20 August 2007.
- ^ Preston, Sherry (9 October 2023). "Cover to Cover: Access thousands of books on Project Gutenberg". Star-Herald. Retrieved 24 February 2024.
- ^ "Hobbes' Internet Timeline". Archived from the original on 5 May 2009. Retrieved 17 February 2009.
- ^ Hart, Michael S. (August 1992). "Gutenberg:The History and Philosophy of Project Gutenberg". Archived from the original on 29 November 2006. Retrieved 5 December 2006.
- ^ Day, B. H.; Wortman, W. A. (2000). Literature in English: A Guide for Librarians in the Digital Age. Chicago: Association of College and Research Libraries. p. 170. ISBN 0-8389-8081-3.
- ^ "Obituary for Michael Stern Hart".
- ^ Vara, Vauhini (5 December 2005). "Project Gutenberg Fears No Google". The Wall Street Journal. Archived from the original on 9 August 2017. Retrieved 15 August 2007.
- ^ "Gutenberg:Credits". Project Gutenberg. 8 June 2006. Archived from the original on 11 July 2007. Retrieved 15 August 2007.
- ^ "Michael_S._Hart". Project Gutenberg. 6 September 2011. Archived from the original on 17 September 2011. Retrieved 25 September 2011.
- ^ "The CD and DVD Project". Gutenberg. 24 July 2012. Archived from the original on 5 October 2012. Retrieved 7 October 2012.
- ^ According to gutindex-2006 Archived 13 November 2012 at the Wayback Machine, there were 1,653 new Project Gutenberg items posted in the first 33 weeks of 2006. This averages out to 50.09 per week. This does not include additions to affiliated projects.
- ^ For a listing of the categorized books, see: "Category:Bookshelf". Project Gutenberg. 28 April 2007. Archived from the original on 11 July 2007. Retrieved 18 August 2007.
- ^ "Project Gutenberg Sheet Music | Manchester-by-the-Sea Public Library". Manchesterpl.org. Archived from the original on 14 July 2014. Retrieved 14 July 2014.
- ^ Various Project Gutenberg FAQs allude to this. See, for example: "File Formats FAQ". Archived from the original on 2 November 2012. Retrieved 2 November 2012.
You can view or edit ASCII text using just about every text editor or viewer in the world. [...] Unicode is steadily gaining ground, with at least some support in every major operating system, but we're nowhere near the point where everyone can just open a text based on Unicode and read and edit it.
- ^ "The Guide to PGTEI". Project Gutenberg. 12 April 2005. Archived from the original on 18 May 2013. Retrieved 7 February 2013.
- ^ The Project Gutenberg RST Manual. Project Gutenberg. 25 November 2010. Archived from the original on 26 January 2013. Retrieved 8 February 2013.
- ^ "Help on Bibliographic Record". Project Gutenberg. 4 April 2010. Archived from the original on 17 September 2011. Retrieved 3 September 2011.
- ^ "The Project Gutenberg Weekly Newsletter". Project Gutenberg. 10 December 2003. Archived from the original on 11 May 2011. Retrieved 8 June 2008.
- ^ Perry, Ruth (2007). "Postscript about the Public Libraries". Modern Language Association. Archived from the original on 9 August 2007. Retrieved 20 August 2007.
- ^ Lorenzen, Michael (2002). "Deconstructing the Philanthropic Library: The Sociological Reasons Behind Andrew Carnegie's Millions to Libraries". Modern Language Association. Archived from the original on 13 August 2007. Retrieved 20 August 2007.
- ^ Walker, Joseph (30 November 2013). Information Technology and Collection Management for Library User Environments. IGI Global. ISBN 9781466647404.
- ^ Pegoraro, Rob (30 November 2010). "Amazon charges Kindle users for free Project Gutenberg e-books". The Washington Post. Archived from the original on 5 May 2017. Retrieved 3 March 2018.
- ^ "Court Order to Block Access in Germany". Project Gutenberg Library Archive Foundation. Archived from the original on 4 March 2018. Retrieved 4 March 2018.
- ^ "OLG Frankfurt judgment of 30 April 2019".
- ^ "Lawsuit is Settled". Project Gutenberg Literary Archive Foundation. Retrieved 6 December 2021.
- ^ Caranti, Niccolò. "Project Gutenberg blocked in Italy: many doubts, few certainties". OBC Transeuropa. Retrieved 10 January 2022.
- ^ Boumphrey, Frank (July 2000). "European Literature and Project Gutenberg". Cultivate Interactive. Archived from the original on 14 July 2007. Retrieved 15 August 2007.
- ^ Partick Lucas Austin (20 June 2017). "Standard eBooks is a Gutenberg Project You'll Actually Use". LifeHacker.com. Retrieved 20 October 2020.
- ^ Michael Sperberg-McQueen, "Textual Criticism and the Text Encoding Initiative", 1994, "Textual Criticism and the Text Encoding Initiative". Archived from the original on 4 March 2016. Retrieved 28 July 2015., retrieved 25 July 2015.
- ^ Hoffmann, Sebastian (2005). Grammaticalization And English Complex Prepositions: A Corpus-based Study (1st ed.). Routledge. ISBN 0-415-36049-8. OCLC 156424479.
- ^ Executive director of the World eBook Library.
- ^ a b Hane, Paula (2004). "Project Gutenberg Progresses". Information Today. 21 (5). Archived from the original on 30 September 2007. Retrieved 20 August 2007.
- ^ "The Project Gutenberg Literary Archive Foundation". Retrieved 13 February 2022.
- ^ "INDEX". PROJECT GUTENBERG. Retrieved 13 February 2022.
- ^ Schwencke, Ken; Tigas, Mike; Wei, Sisi; Glassford, Alec; Suozzo, Andrea; Roberts, Brandon (9 May 2013). "Project Gutenberg Literary Archive Foundation Inc Tr". Nonprofit Explorer. ProPublica.
- ^ Stroube, Bryan (September 2003). "Literary freedom". XRDS: Crossroads, the ACM Magazine for Students. 10 (1): 3. doi:10.1145/973381.973384. ISSN 1528-4972. S2CID 12606524.
- ^ "Cease and Desist Responses". Project Gutenberg Literary Archive Foundation. Retrieved 13 February 2022.
- ^ "donate". Project Gutenberg. Retrieved 13 February 2022.
- ^ Newby, Gregory B. "Curriculum Vitae". petascale.org. Archived from the original on 20 April 2021. Retrieved 13 February 2022.
Greg Newby's Personal Pages www.supercomputing.guru & www.petascale.org
- ^ "Greg Newby". Wired Next Fest 2021 Milano (in Italian). Retrieved 13 February 2022.
- ^ "Gregory B Newby". Author profiles. Association for Computing Machinery Digital Library. Retrieved 13 February 2022.
- ^ "Author: Gregory B. Newby". The Interaction Design Foundation. Retrieved 13 February 2022.
- ^ "Gregory B. Newby". The MIT Press. Retrieved 13 February 2022.
- ^ "Gregory B. Newby, University of Alaska System". ResearchGate. Retrieved 13 February 2022.
- ^ Newby, Gregory B. (18 October 2019). Forty-Five Years of Digitizing Ebooks: Project Gutenberg's Practices. Project Gutenberg.
- ^ "Gregory B. Newby". Open Source Research People. ibiblio. Retrieved 13 February 2022.
- ^ "Programmable Silicon! Don't be afraid, don't be very afraid!". programme.exordo.com. Archived from the original on 14 February 2022. Retrieved 13 February 2022.
- ^ "Compute Canada Announces New CTO to Lead Upgrades to National Advanced Research Platform". WestGrid. 16 December 2014. Archived from the original on 13 February 2022. Retrieved 13 February 2022.
- ^ "HPCS 2016". CANHEIT. Archived from the original on 19 January 2016. Retrieved 13 February 2022.
- ^ Mölders, Nicole; Morton, Don; Newby, Greg; Stevens, Eric; Stuefer, Martin (2008). "Nowcasting and Forecasting Alaskan Weather". Bulletin of the American Meteorological Society. 89 (4): 515–519. Bibcode:2008BAMS...89..515M. doi:10.1175/BAMS-89-4-515. ISSN 0003-0007. JSTOR 26216803.
- ^ "Penguin Computing Supplies PACMAN Supercomputer to University of Alaska Fairbanks". Penguin Computing. 25 May 2011. Retrieved 13 February 2022.
- ^ "Project Gutenberg Consortia Center". 2004. Archived from the original on 9 August 2007. Retrieved 20 August 2007.
- ^ a b c d e f g h i j k l "Partners, Sister Projects, Affiliates and Resources". Project Gutenberg. Retrieved 13 February 2022.
- ^ "The Distributed Proofreaders Foundation". Distributed proofreaders. August 2007. Archived from the original on 21 August 2007. Retrieved 10 August 2007.
- ^ "Gutenberg:Partners, Affiliates and Resources". Project Gutenberg. 17 July 2007. Archived from the original on 26 September 2007. Retrieved 20 August 2007.
- ^ "Project Gutenberg of Australia". 24 January 2007. Archived from the original on 14 August 2006. Retrieved 10 August 2006.
- ^ "Project Gutenberg Canada". Archived from the original on 18 January 2016. Retrieved 20 August 2007.
- ^ "Projekt Gutenberg-DE". Spiegel Online. 1994. Archived from the original on 30 June 2007. Retrieved 20 August 2007.
- ^ "Project Gutenberg Europe". EUnet Yugoslavia. 2005. Archived from the original on 20 August 2007. Retrieved 20 August 2007.
- ^ Kirps, Jos (22 May 2007). "Project Gutenberg Luxembourg". Archived from the original on 29 September 2007. Retrieved 20 August 2007.
- ^ Riikonen, Tapio (28 February 2005). "Projekti Lönnrot". Archived from the original on 10 August 2007. Retrieved 20 August 2007.
- ^ "Project Gutenberg of the Philippines". Archived from the original on 24 August 2007. Retrieved 20 August 2007.
- ^ "Project Gutenberg Russia". Archived from the original on 24 May 2012. Retrieved 5 April 2012.
- ^ a b "Partners, Affiliates and Resources". Archived from the original on 13 November 2012. Retrieved 27 February 2016.
- ^ "Project Gutenberg Self-Publishing Press". Archived from the original on 2 March 2016. Retrieved 27 February 2016.
- ^ "Project Gutenberg launches self-publishing library". RT Book Reviews. Archived from the original on 4 March 2016. Retrieved 27 February 2016.
- ^ "Domain Availability – Registration Information". GoDaddy. Archived from the original on 3 March 2016. Retrieved 27 February 2016.
- ^ "Project Gutenberg of Taiwan". Archived from the original on 11 May 2011. Retrieved 5 April 2009.
External links
edit Media from Commons
Media from Commons Texts from Wikisource
Texts from Wikisource Data from Wikidata
Data from Wikidata
- Official website
- Distributed Proofreaders – a worldwide group of volunteer editors that is now the main source of eBooks for Project Gutenberg
- Project Gutenberg News – Official News for Gutenberg.org. Includes the Newsletter Archives, 1989–present.
- Project Gutenberg Monthly Newsletter
- Works by Project Gutenberg at Project Gutenberg Works by or about Project Gutenberg at the Internet Archive