


Summary
Amino acids are organic compounds that contain both amino and carboxylic acid functional groups.[1] Although over 500 amino acids exist in nature, by far the most important are the 22 α-amino acids incorporated into proteins.[2] Only these 22 appear in the genetic code of life.[3][4]

Amino acids can be classified according to the locations of the core structural functional groups (alpha- (α-), beta- (β-), gamma- (γ-) amino acids, etc.), other categories relate to polarity, ionization, and side chain group type (aliphatic, acyclic, aromatic, polar, etc.). In the form of proteins, amino acid residues form the second-largest component (water being the largest) of human muscles and other tissues.[5] Beyond their role as residues in proteins, amino acids participate in a number of processes such as neurotransmitter transport and biosynthesis. It is thought that they played a key role in enabling life on Earth and its emergence.
Amino acids are formally named by the IUPAC-IUBMB Joint Commission on Biochemical Nomenclature in terms of the fictitious "neutral" structure shown in the illustration. For example, the systematic name of alanine is 2-aminopropanoic acid, based on the formula CH3−CH(NH2)−COOH. The Commission justified this approach as follows:[6]
The systematic names and formulas given refer to hypothetical forms in which amino groups are unprotonated and carboxyl groups are undissociated. This convention is useful to avoid various nomenclatural problems but should not be taken to imply that these structures represent an appreciable fraction of the amino-acid molecules.
History edit
The first few amino acids were discovered in the early 1800s.[7][8] In 1806, French chemists Louis-Nicolas Vauquelin and Pierre Jean Robiquet isolated a compound from asparagus that was subsequently named asparagine, the first amino acid to be discovered.[9][10] Cystine was discovered in 1810,[11] although its monomer, cysteine, remained undiscovered until 1884.[12][10][a] Glycine and leucine were discovered in 1820.[13] The last of the 20 common amino acids to be discovered was threonine in 1935 by William Cumming Rose, who also determined the essential amino acids and established the minimum daily requirements of all amino acids for optimal growth.[14][15]
The unity of the chemical category was recognized by Wurtz in 1865, but he gave no particular name to it.[16] The first use of the term "amino acid" in the English language dates from 1898,[17] while the German term, Aminosäure, was used earlier.[18] Proteins were found to yield amino acids after enzymatic digestion or acid hydrolysis. In 1902, Emil Fischer and Franz Hofmeister independently proposed that proteins are formed from many amino acids, whereby bonds are formed between the amino group of one amino acid with the carboxyl group of another, resulting in a linear structure that Fischer termed "peptide".[19]
General structure edit

2-, alpha-, or α-amino acids[20] have the generic formula H2NCHRCOOH in most cases,[b] where R is an organic substituent known as a "side chain".[21]
Of the many hundreds of described amino acids, 22 are proteinogenic ("protein-building").[22][23][24] It is these 22 compounds that combine to give a vast array of peptides and proteins assembled by ribosomes.[25] Non-proteinogenic or modified amino acids may arise from post-translational modification or during nonribosomal peptide synthesis.
Chirality edit
The carbon atom next to the carboxyl group is called the α–carbon. In proteinogenic amino acids, it bears the amine and the R group or side chain specific to each amino acid. With four distinct substituents, the α–carbon is stereogenic in all α-amino acids except glycine. All chiral proteogenic amino acids have the L configuration. They are "left-handed" enantiomers, which refers to the stereoisomers of the alpha carbon.
A few D-amino acids ("right-handed") have been found in nature, e.g., in bacterial envelopes, as a neuromodulator (D-serine), and in some antibiotics.[26][27] Rarely, D-amino acid residues are found in proteins, and are converted from the L-amino acid as a post-translational modification.[28][c]
Side chains edit
Polar charged side chains edit
Five amino acids possess a charge at neutral pH. Often these side chains appear at the surfaces on proteins to enable their solubility in water, and side chains with opposite charges form important electrostatic contacts called salt bridges that maintain structures within a single protein or between interfacing proteins.[31] Many proteins bind metal into their structures specifically, and these interactions are commonly mediated by charged side chains such as aspartate, glutamate and histidine. Under certain conditions, each ion-forming group can be charged, forming double salts.[32]
The two negatively charged amino acids at neutral pH are aspartate (Asp, D) and glutamate (Glu, E). The anionic carboxylate groups behave as Brønsted bases in most circumstances.[31] Enzymes in very low pH environments, like the aspartic protease pepsin in mammalian stomachs, may have catalytic aspartate or glutamate residues that act as Brønsted acids.

There are three amino acids with side chains that are cations at neutral pH: arginine (Arg, R), lysine (Lys, K) and histidine (His, H). Arginine has a charged guanidino group and lysine a charged alkyl amino group, and are fully protonated at pH 7. Histidine's imidazole group has a pKa of 6.0, and is only around 10 % protonated at neutral pH. Because histidine is easily found in its basic and conjugate acid forms it often participates in catalytic proton transfers in enzyme reactions.[31]
Polar uncharged side chains edit
The polar, uncharged amino acids serine (Ser, S), threonine (Thr, T), asparagine (Asn, N) and glutamine (Gln, Q) readily form hydrogen bonds with water and other amino acids.[31] They do not ionize in normal conditions, a prominent exception being the catalytic serine in serine proteases. This is an example of severe perturbation, and is not characteristic of serine residues in general. Threonine has two chiral centers, not only the L (2S) chiral center at the α-carbon shared by all amino acids apart from achiral glycine, but also (3R) at the β-carbon. The full stereochemical specification is (2S,3R)-L-threonine.
Hydrophobic side chains edit
Nonpolar amino acid interactions are the primary driving force behind the processes that fold proteins into their functional three dimensional structures.[31] None of these amino acids' side chains ionize easily, and therefore do not have pKas, with the exception of tyrosine (Tyr, Y). The hydroxyl of tyrosine can deprotonate at high pH forming the negatively charged phenolate. Because of this one could place tyrosine into the polar, uncharged amino acid category, but its very low solubility in water matches the characteristics of hydrophobic amino acids well.
Special case side chains edit
Several side chains are not described well by the charged, polar and hydrophobic categories. Glycine (Gly, G) could be considered a polar amino acid since its small size means that its solubility is largely determined by the amino and carboxylate groups. However, the lack of any side chain provides glycine with a unique flexibility among amino acids with large ramifications to protein folding.[31] Cysteine (Cys, C) can also form hydrogen bonds readily, which would place it in the polar amino acid category, though it can often be found in protein structures forming covalent bonds, called disulphide bonds, with other cysteines. These bonds influence the folding and stability of proteins, and are essential in the formation of antibodies. Proline (Pro, P) has an alkyl side chain and could be considered hydrophobic, but because the side chain joins back onto the alpha amino group it becomes particularly inflexible when incorporated into proteins. Similar to glycine this influences protein structure in a way unique among amino acids. Selenocysteine (Sec, U) is a rare amino acid not directly encoded by DNA, but is incorporated into proteins via the ribosome. Selenocysteine has a lower redox potential compared to the similar cysteine, and participates in several unique enzymatic reactions.[33] Pyrrolysine (Pyl, O) is another amino acid not encoded in DNA, but synthesized into protein by ribosomes.[34] It is found in archaeal species where it participates in the catalytic activity of several methyltransferases.
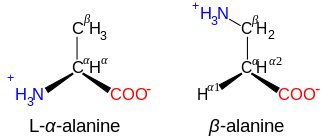
β- and γ-amino acids edit
Amino acids with the structure NH+3−CXY−CXY−CO−2, such as β-alanine, a component of carnosine and a few other peptides, are β-amino acids. Ones with the structure NH+3−CXY−CXY−CXY−CO−2 are γ-amino acids, and so on, where X and Y are two substituents (one of which is normally H).[6]
Zwitterions edit

The common natural forms of amino acids have a zwitterionic structure, with −NH+3 (−NH+2− in the case of proline) and −CO−2 functional groups attached to the same C atom, and are thus α-amino acids, and are the only ones found in proteins during translation in the ribosome. In aqueous solution at pH close to neutrality, amino acids exist as zwitterions, i.e. as dipolar ions with both NH+3 and CO−2 in charged states, so the overall structure is NH+3−CHR−CO−2. At physiological pH the so-called "neutral forms" −NH2−CHR−CO2H are not present to any measurable degree.[35] Although the two charges in the zwitterion structure add up to zero it is misleading to call a species with a net charge of zero "uncharged".
In strongly acidic conditions (pH below 3), the carboxylate group becomes protonated and the structure becomes an ammonio carboxylic acid, NH+3−CHR−CO2H. This is relevant for enzymes like pepsin that are active in acidic environments such as the mammalian stomach and lysosomes, but does not significantly apply to intracellular enzymes. In highly basic conditions (pH greater than 10, not normally seen in physiological conditions), the ammonio group is deprotonated to give NH2−CHR−CO−2.
Although various definitions of acids and bases are used in chemistry, the only one that is useful for chemistry in aqueous solution is that of Brønsted:[36][37] an acid is a species that can donate a proton to another species, and a base is one that can accept a proton. This criterion is used to label the groups in the above illustration. The carboxylate side chains of aspartate and glutamate residues are the principal Brønsted bases in proteins. Likewise, lysine, tyrosine and cysteine will typically act as a Brønsted acid. Histidine under these conditions can act both as a Brønsted acid and a base.
Isoelectric point edit

For amino acids with uncharged side-chains the zwitterion predominates at pH values between the two pKa values, but coexists in equilibrium with small amounts of net negative and net positive ions. At the midpoint between the two pKa values, the trace amount of net negative and trace of net positive ions balance, so that average net charge of all forms present is zero.[38] This pH is known as the isoelectric point pI, so pI = 1/2(pKa1 + pKa2).
For amino acids with charged side chains, the pKa of the side chain is involved. Thus for aspartate or glutamate with negative side chains, the terminal amino group is essentially entirely in the charged form −NH+3, but this positive charge needs to be balanced by the state with just one C-terminal carboxylate group is negatively charged. This occurs halfway between the two carboxylate pKa values: pI = 1/2(pKa1 + pKa(R)), where pKa(R) is the side chain pKa.[37]
Similar considerations apply to other amino acids with ionizable side-chains, including not only glutamate (similar to aspartate), but also cysteine, histidine, lysine, tyrosine and arginine with positive side chains.
Amino acids have zero mobility in electrophoresis at their isoelectric point, although this behaviour is more usually exploited for peptides and proteins than single amino acids. Zwitterions have minimum solubility at their isoelectric point, and some amino acids (in particular, with nonpolar side chains) can be isolated by precipitation from water by adjusting the pH to the required isoelectric point.
Physicochemical properties edit
The 20 canonical amino acids can be classified according to their properties. Important factors are charge, hydrophilicity or hydrophobicity, size, and functional groups.[27] These properties influence protein structure and protein–protein interactions. The water-soluble proteins tend to have their hydrophobic residues (Leu, Ile, Val, Phe, and Trp) buried in the middle of the protein, whereas hydrophilic side chains are exposed to the aqueous solvent. (In biochemistry, a residue refers to a specific monomer within the polymeric chain of a polysaccharide, protein or nucleic acid.) The integral membrane proteins tend to have outer rings of exposed hydrophobic amino acids that anchor them in the lipid bilayer. Some peripheral membrane proteins have a patch of hydrophobic amino acids on their surface that sticks to the membrane. In a similar fashion, proteins that have to bind to positively charged molecules have surfaces rich in negatively charged amino acids such as glutamate and aspartate, while proteins binding to negatively charged molecules have surfaces rich in positively charged amino acids like lysine and arginine. For example, lysine and arginine are present in large amounts in the low-complexity regions of nucleic-acid binding proteins.[39] There are various hydrophobicity scales of amino acid residues.[40]
Some amino acids have special properties. Cysteine can form covalent disulfide bonds to other cysteine residues. Proline forms a cycle to the polypeptide backbone, and glycine is more flexible than other amino acids.
Glycine and proline are strongly present within low complexity regions of both eukaryotic and prokaryotic proteins, whereas the opposite is the case with cysteine, phenylalanine, tryptophan, methionine, valine, leucine, isoleucine, which are highly reactive, or complex, or hydrophobic.[39][41][42]
Many proteins undergo a range of posttranslational modifications, whereby additional chemical groups are attached to the amino acid residue side chains sometimes producing lipoproteins (that are hydrophobic),[43] or glycoproteins (that are hydrophilic)[44] allowing the protein to attach temporarily to a membrane. For example, a signaling protein can attach and then detach from a cell membrane, because it contains cysteine residues that can have the fatty acid palmitic acid added to them and subsequently removed.[45]
Table of standard amino acid abbreviations and properties edit
Although one-letter symbols are included in the table, IUPAC–IUBMB recommend[6] that "Use of the one-letter symbols should be restricted to the comparison of long sequences".
The one-letter notation was chosen by IUPAC-IUB based on the following rules:[46]
- Initial letters are used where there is no ambuiguity: C cysteine, H histidine, I isoleucine, M methionine, S serine, V valine,[46]
- Where arbitrary assignment is needed, the structurally simpler amino acids are given precedence: A Alanine, G glycine, L leucine, P proline, T threonine,[46]
- F PHenylalanine and R aRginine are assigned by being phonetically suggestive,[46]
- W tryptophane is assigned based on the double ring being visually suggestive to the bulky letter W,[46]
- K lysine and Y tyrosine are assigned as alphabetically nearest to their initials L and T (note that U was avoided for its similarity with V, while X was reserved for undetermined or atypical amino acids); for tyrosine the mnemonic tYrosine was also proposed,[47]
- D aspartate was assigned arbitrarily, with the proposed mnemonic asparDic acid;[48] E glutamate was assigned in alphabetical sequence being larger by merely one methylene –CH2– group,[47]
- N asparagine was assigned arbitrarily, with the proposed mnemonic asparagiNe;[48] Q glutamine was assigned in alphabetical sequence of those still available (note again that O was avoided due to similarity with D), with the proposed mnemonic Qlutamine.[48]
| Amino acid | 3- and 1-letter symbols | Side chain | Hydropathy index[49] |
Molar absorptivity[50] | Molecular mass | Abundance in proteins (%)[51] |
Standard genetic coding, IUPAC notation | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 1 | Class | Chemical polarity[52] | Net charge at pH 7.4[52] |
Wavelength, λmax (nm) |
Coefficient ε (mM−1·cm−1) | |||||
| Alanine | Ala | A | Aliphatic | Nonpolar | Neutral | 1.8 | 89.094 | 8.76 | GCN | ||
| Arginine | Arg | R | Fixed cation | Basic polar | Positive | −4.5 | 174.203 | 5.78 | MGR, CGY[53] | ||
| Asparagine | Asn | N | Amide | Polar | Neutral | −3.5 | 132.119 | 3.93 | AAY | ||
| Aspartate | Asp | D | Anion | Brønsted base | Negative | −3.5 | 133.104 | 5.49 | GAY | ||
| Cysteine | Cys | C | Thiol | Brønsted acid | Neutral | 2.5 | 250 | 0.3 | 121.154 | 1.38 | UGY |
| Glutamine | Gln | Q | Amide | Polar | Neutral | −3.5 | 146.146 | 3.9 | CAR | ||
| Glutamate | Glu | E | Anion | Brønsted base | Negative | −3.5 | 147.131 | 6.32 | GAR | ||
| Glycine | Gly | G | Aliphatic | Nonpolar | Neutral | −0.4 | 75.067 | 7.03 | GGN | ||
| Histidine | His | H | Cationic | Brønsted acid and base | Positive, 10% Neutral, 90% |
−3.2 | 211 | 5.9 | 155.156 | 2.26 | CAY |
| Isoleucine | Ile | I | Aliphatic | Nonpolar | Neutral | 4.5 | 131.175 | 5.49 | AUH | ||
| Leucine | Leu | L | Aliphatic | Nonpolar | Neutral | 3.8 | 131.175 | 9.68 | YUR, CUY[54] | ||
| Lysine | Lys | K | Cation | Brønsted acid | Positive | −3.9 | 146.189 | 5.19 | AAR | ||
| Methionine | Met | M | Thioether | Nonpolar | Neutral | 1.9 | 149.208 | 2.32 | AUG | ||
| Phenylalanine | Phe | F | Aromatic | Nonpolar | Neutral | 2.8 | 257, 206, 188 | 0.2, 9.3, 60.0 | 165.192 | 3.87 | UUY |
| Proline | Pro | P | Cyclic | Nonpolar | Neutral | −1.6 | 115.132 | 5.02 | CCN | ||
| Serine | Ser | S | Hydroxylic | Polar | Neutral | −0.8 | 105.093 | 7.14 | UCN, AGY | ||
| Threonine | Thr | T | Hydroxylic | Polar | Neutral | −0.7 | 119.119 | 5.53 | ACN | ||
| Tryptophan | Trp | W | Aromatic | Nonpolar | Neutral | −0.9 | 280, 219 | 5.6, 47.0 | 204.228 | 1.25 | UGG |
| Tyrosine | Tyr | Y | Aromatic | Brønsted acid | Neutral | −1.3 | 274, 222, 193 | 1.4, 8.0, 48.0 | 181.191 | 2.91 | UAY |
| Valine | Val | V | Aliphatic | Nonpolar | Neutral | 4.2 | 117.148 | 6.73 | GUN | ||
Two additional amino acids are in some species coded for by codons that are usually interpreted as stop codons:
| 21st and 22nd amino acids | 3-letter | 1-letter | Molecular mass |
|---|---|---|---|
| Selenocysteine | Sec | U | 168.064 |
| Pyrrolysine | Pyl | O | 255.313 |
In addition to the specific amino acid codes, placeholders are used in cases where chemical or crystallographic analysis of a peptide or protein cannot conclusively determine the identity of a residue. They are also used to summarize conserved protein sequence motifs. The use of single letters to indicate sets of similar residues is similar to the use of abbreviation codes for degenerate bases.[55][56]
| Ambiguous amino acids | 3-letter | 1-letter | Amino acids included | Codons included |
|---|---|---|---|---|
| Any / unknown | Xaa | X | All | NNN |
| Asparagine or aspartate | Asx | B | D, N | RAY |
| Glutamine or glutamate | Glx | Z | E, Q | SAR |
| Leucine or isoleucine | Xle | J | I, L | YTR, ATH, CTY[57] |
| Hydrophobic | Φ | V, I, L, F, W, Y, M | NTN, TAY, TGG | |
| Aromatic | Ω | F, W, Y, H | YWY, TTY, TGG[58] | |
| Aliphatic (non-aromatic) | Ψ | V, I, L, M | VTN, TTR[59] | |
| Small | π | P, G, A, S | BCN, RGY, GGR | |
| Hydrophilic | ζ | S, T, H, N, Q, E, D, K, R | VAN, WCN, CGN, AGY[60] | |
| Positively-charged | + | K, R, H | ARR, CRY, CGR | |
| Negatively-charged | − | D, E | GAN |
Unk is sometimes used instead of Xaa, but is less standard.
Ter or * (from termination) is used in notation for mutations in proteins when a stop codon occurs. It corresponds to no amino acid at all.[61]
In addition, many nonstandard amino acids have a specific code. For example, several peptide drugs, such as Bortezomib and MG132, are artificially synthesized and retain their protecting groups, which have specific codes. Bortezomib is Pyz–Phe–boroLeu, and MG132 is Z–Leu–Leu–Leu–al. To aid in the analysis of protein structure, photo-reactive amino acid analogs are available. These include photoleucine (pLeu) and photomethionine (pMet).[62]
Occurrence and functions in biochemistry edit
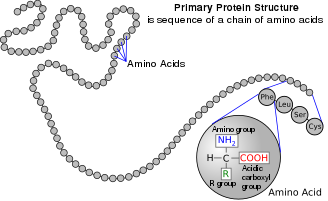

Proteinogenic amino acids edit
Amino acids are the precursors to proteins.[25] They join by condensation reactions to form short polymer chains called peptides or longer chains called either polypeptides or proteins. These chains are linear and unbranched, with each amino acid residue within the chain attached to two neighboring amino acids. In nature, the process of making proteins encoded by DNA/RNA genetic material is called translation and involves the step-by-step addition of amino acids to a growing protein chain by a ribozyme that is called a ribosome.[63] The order in which the amino acids are added is read through the genetic code from an mRNA template, which is an RNA copy of one of the organism's genes.
Twenty-two amino acids are naturally incorporated into polypeptides and are called proteinogenic or natural amino acids.[27] Of these, 20 are encoded by the universal genetic code. The remaining 2, selenocysteine and pyrrolysine, are incorporated into proteins by unique synthetic mechanisms. Selenocysteine is incorporated when the mRNA being translated includes a SECIS element, which causes the UGA codon to encode selenocysteine instead of a stop codon.[64] Pyrrolysine is used by some methanogenic archaea in enzymes that they use to produce methane. It is coded for with the codon UAG, which is normally a stop codon in other organisms.[65] This UAG codon is followed by a PYLIS downstream sequence.[66]
Several independent evolutionary studies have suggested that Gly, Ala, Asp, Val, Ser, Pro, Glu, Leu, Thr may belong to a group of amino acids that constituted the early genetic code, whereas Cys, Met, Tyr, Trp, His, Phe may belong to a group of amino acids that constituted later additions of the genetic code.[67][68][69]
Standard vs nonstandard amino acids edit
The 20 amino acids that are encoded directly by the codons of the universal genetic code are called standard or canonical amino acids. A modified form of methionine (N-formylmethionine) is often incorporated in place of methionine as the initial amino acid of proteins in bacteria, mitochondria and chloroplasts. Other amino acids are called nonstandard or non-canonical. Most of the nonstandard amino acids are also non-proteinogenic (i.e. they cannot be incorporated into proteins during translation), but two of them are proteinogenic, as they can be incorporated translationally into proteins by exploiting information not encoded in the universal genetic code.
The two nonstandard proteinogenic amino acids are selenocysteine (present in many non-eukaryotes as well as most eukaryotes, but not coded directly by DNA) and pyrrolysine (found only in some archaea and at least one bacterium). The incorporation of these nonstandard amino acids is rare. For example, 25 human proteins include selenocysteine in their primary structure,[70] and the structurally characterized enzymes (selenoenzymes) employ selenocysteine as the catalytic moiety in their active sites.[71] Pyrrolysine and selenocysteine are encoded via variant codons. For example, selenocysteine is encoded by stop codon and SECIS element.[72][73][74]
N-formylmethionine (which is often the initial amino acid of proteins in bacteria, mitochondria, and chloroplasts) is generally considered as a form of methionine rather than as a separate proteinogenic amino acid. Codon–tRNA combinations not found in nature can also be used to "expand" the genetic code and form novel proteins known as alloproteins incorporating non-proteinogenic amino acids.[75][76][77]
Non-proteinogenic amino acids edit
Aside from the 22 proteinogenic amino acids, many non-proteinogenic amino acids are known. Those either are not found in proteins (for example carnitine, GABA, levothyroxine) or are not produced directly and in isolation by standard cellular machinery. For example, hydroxyproline , is synthesised from proline. Another example is selenomethionine).
Non-proteinogenic amino acids that are found in proteins are formed by post-translational modification. Such modifications can also determine the localization of the protein, e.g., the addition of long hydrophobic groups can cause a protein to bind to a phospholipid membrane.[78] Examples:
- the carboxylation of glutamate allows for better binding of calcium cations,[79]
- Hydroxyproline, generated by hydroxylation of proline, is a major component of the connective tissue collagen.[80]
- Hypusine in the translation initiation factor EIF5A, contains a modification of lysine.[81]
Some non-proteinogenic amino acids are not found in proteins. Examples include 2-aminoisobutyric acid and the neurotransmitter gamma-aminobutyric acid. Non-proteinogenic amino acids often occur as intermediates in the metabolic pathways for standard amino acids – for example, ornithine and citrulline occur in the urea cycle, part of amino acid catabolism (see below).[82] A rare exception to the dominance of α-amino acids in biology is the β-amino acid beta alanine (3-aminopropanoic acid), which is used in plants and microorganisms in the synthesis of pantothenic acid (vitamin B5), a component of coenzyme A.[83]
In mammalian nutrition edit
Amino acids are not typical component of food: animals eat proteins. The protein is broken down into amino acids in the process of digestion. They are then used to synthesize new proteins, other biomolecules, or are oxidized to urea and carbon dioxide as a source of energy.[84] The oxidation pathway starts with the removal of the amino group by a transaminase; the amino group is then fed into the urea cycle. The other product of transamidation is a keto acid that enters the citric acid cycle.[85] Glucogenic amino acids can also be converted into glucose, through gluconeogenesis.[86]
Of the 20 standard amino acids, nine (His, Ile, Leu, Lys, Met, Phe, Thr, Trp and Val) are called essential amino acids because the human body cannot synthesize them from other compounds at the level needed for normal growth, so they must be obtained from food.[87][88][89]
Semi-essential and conditionally essential amino acids, and juvenile requirements edit
In addition, cysteine, tyrosine, and arginine are considered semiessential amino acids, and taurine a semi-essential aminosulfonic acid in children. Some amino acids are conditionally essential for certain ages or medical conditions. Essential amino acids may also vary from species to species.[d] The metabolic pathways that synthesize these monomers are not fully developed.[90][91]
Non-protein functions edit
Many proteinogenic and non-proteinogenic amino acids have biological functions beyond being precursors to proteins and peptides.In humans, amino acids also have important roles in diverse biosynthetic pathways. Defenses against herbivores in plants sometimes employ amino acids.[95] Examples:
Standard amino acids edit
- Tryptophan is a precursor of the neurotransmitter serotonin.[96]
- Tyrosine (and its precursor phenylalanine) are precursors of the catecholamine neurotransmitters dopamine, epinephrine and norepinephrine and various trace amines.
- Phenylalanine is a precursor of phenethylamine and tyrosine in humans. In plants, it is a precursor of various phenylpropanoids, which are important in plant metabolism.
- Glycine is a precursor of porphyrins such as heme.[97]
- Arginine is a precursor of nitric oxide.[98]
- Ornithine and S-adenosylmethionine are precursors of polyamines.[99]
- Aspartate, glycine, and glutamine are precursors of nucleotides.[100] However, not all of the functions of other abundant nonstandard amino acids are known.
Roles for nonstandard amino acids edit
- Carnitine is used in lipid transport.
- gamma-aminobutyric acid is a neurotransmitter.[101]
- 5-HTP (5-hydroxytryptophan) is used for experimental treatment of depression.[102]
- L-DOPA (L-dihydroxyphenylalanine) for Parkinson's treatment,[103]
- Eflornithine inhibits ornithine decarboxylase and used in the treatment of sleeping sickness.[104]
- Canavanine, an analogue of arginine found in many legumes is an antifeedant, protecting the plant from predators.[105]
- Mimosine found in some legumes, is another possible antifeedant.[106] This compound is an analogue of tyrosine and can poison animals that graze on these plants.
Uses in industry edit
Animal feed edit
Amino acids are sometimes added to animal feed because some of the components of these feeds, such as soybeans, have low levels of some of the essential amino acids, especially of lysine, methionine, threonine, and tryptophan.[107] Likewise amino acids are used to chelate metal cations in order to improve the absorption of minerals from feed supplements.[108]
Food edit
The food industry is a major consumer of amino acids, especially glutamic acid, which is used as a flavor enhancer,[109] and aspartame (aspartylphenylalanine 1-methyl ester), which is used as an artificial sweetener.[110] Amino acids are sometimes added to food by manufacturers to alleviate symptoms of mineral deficiencies, such as anemia, by improving mineral absorption and reducing negative side effects from inorganic mineral supplementation.[111]
Chemical building blocks edit
Amino acids are low-cost feedstocks used in chiral pool synthesis as enantiomerically pure building blocks.[112][113]
Amino acids are used in the synthesis of some cosmetics.[107]
Aspirational uses edit
Fertilizer edit
The chelating ability of amino acids is sometimes used in fertilizers to facilitate the delivery of minerals to plants in order to correct mineral deficiencies, such as iron chlorosis. These fertilizers are also used to prevent deficiencies from occurring and to improve the overall health of the plants.[114]
Biodegradable plastics edit
Amino acids have been considered as components of biodegradable polymers, which have applications as environmentally friendly packaging and in medicine in drug delivery and the construction of prosthetic implants.[115] An interesting example of such materials is polyaspartate, a water-soluble biodegradable polymer that may have applications in disposable diapers and agriculture.[116] Due to its solubility and ability to chelate metal ions, polyaspartate is also being used as a biodegradable antiscaling agent and a corrosion inhibitor.[117][118]
Synthesis edit

Chemical synthesis edit
The commercial production of amino acids usually relies on mutant bacteria that overproduce individual amino acids using glucose as a carbon source. Some amino acids are produced by enzymatic conversions of synthetic intermediates. 2-Aminothiazoline-4-carboxylic acid is an intermediate in one industrial synthesis of L-cysteine for example. Aspartic acid is produced by the addition of ammonia to fumarate using a lyase.[111]
Biosynthesis edit
In plants, nitrogen is first assimilated into organic compounds in the form of glutamate, formed from alpha-ketoglutarate and ammonia in the mitochondrion. For other amino acids, plants use transaminases to move the amino group from glutamate to another alpha-keto acid. For example, aspartate aminotransferase converts glutamate and oxaloacetate to alpha-ketoglutarate and aspartate.[119] Other organisms use transaminases for amino acid synthesis, too.
Nonstandard amino acids are usually formed through modifications to standard amino acids. For example, homocysteine is formed through the transsulfuration pathway or by the demethylation of methionine via the intermediate metabolite S-adenosylmethionine,[120] while hydroxyproline is made by a post translational modification of proline.[121]
Microorganisms and plants synthesize many uncommon amino acids. For example, some microbes make 2-aminoisobutyric acid and lanthionine, which is a sulfide-bridged derivative of alanine. Both of these amino acids are found in peptidic lantibiotics such as alamethicin.[122] However, in plants, 1-aminocyclopropane-1-carboxylic acid is a small disubstituted cyclic amino acid that is an intermediate in the production of the plant hormone ethylene.[123]
Primordial synthesis edit
The formation of amino acids and peptides are assumed to precede and perhaps induce the emergence of life on earth. Amino acids can form from simple precursors under various conditions.[124] Surface-based chemical metabolism of amino acids and very small compounds may have led to the build-up of amino acids, coenzymes and phosphate-based small carbon molecules.[125][additional citation(s) needed] Amino acids and similar building blocks could have been elaborated into proto-peptides, with peptides being considered key players in the origin of life.[126]
In the famous Urey-Miller experiment, the passage of an electric arc through a mixture of methane, hydrogen, and ammonia produces a large number of amino acids. Since then, scientists have discovered a range of ways and components by which the potentially prebiotic formation and chemical evolution of peptides may have occurred, such as condensing agents, the design of self-replicating peptides and a number of non-enzymatic mechanisms by which amino acids could have emerged and elaborated into peptides.[126] Several hypotheses invoke the Strecker synthesis whereby hydrogen cyanide, simple aldehydes, ammonia, and water produce amino acids.[124]
According to a review, amino acids, and even peptides, "turn up fairly regularly in the various experimental broths that have been allowed to be cooked from simple chemicals. This is because nucleotides are far more difficult to synthesize chemically than amino acids." For a chronological order, it suggests that there must have been a 'protein world' or at least a 'polypeptide world', possibly later followed by the 'RNA world' and the 'DNA world'.[127] Codon–amino acids mappings may be the biological information system at the primordial origin of life on Earth.[128] While amino acids and consequently simple peptides must have formed under different experimentally probed geochemical scenarios, the transition from an abiotic world to the first life forms is to a large extent still unresolved.[129]
Reactions edit
Amino acids undergo the reactions expected of the constituent functional groups.[130][131]
Peptide bond formation edit

As both the amine and carboxylic acid groups of amino acids can react to form amide bonds, one amino acid molecule can react with another and become joined through an amide linkage. This polymerization of amino acids is what creates proteins. This condensation reaction yields the newly formed peptide bond and a molecule of water. In cells, this reaction does not occur directly; instead, the amino acid is first activated by attachment to a transfer RNA molecule through an ester bond. This aminoacyl-tRNA is produced in an ATP-dependent reaction carried out by an aminoacyl tRNA synthetase.[132] This aminoacyl-tRNA is then a substrate for the ribosome, which catalyzes the attack of the amino group of the elongating protein chain on the ester bond.[133] As a result of this mechanism, all proteins made by ribosomes are synthesized starting at their N-terminus and moving toward their C-terminus.
However, not all peptide bonds are formed in this way. In a few cases, peptides are synthesized by specific enzymes. For example, the tripeptide glutathione is an essential part of the defenses of cells against oxidative stress. This peptide is synthesized in two steps from free amino acids.[134] In the first step, gamma-glutamylcysteine synthetase condenses cysteine and glutamate through a peptide bond formed between the side chain carboxyl of the glutamate (the gamma carbon of this side chain) and the amino group of the cysteine. This dipeptide is then condensed with glycine by glutathione synthetase to form glutathione.[135]
In chemistry, peptides are synthesized by a variety of reactions. One of the most-used in solid-phase peptide synthesis uses the aromatic oxime derivatives of amino acids as activated units. These are added in sequence onto the growing peptide chain, which is attached to a solid resin support.[136] Libraries of peptides are used in drug discovery through high-throughput screening.[137]
The combination of functional groups allow amino acids to be effective polydentate ligands for metal–amino acid chelates.[138] The multiple side chains of amino acids can also undergo chemical reactions.
Catabolism edit

* Glucogenic, with the products having the ability to form glucose by gluconeogenesis
* Ketogenic, with the products not having the ability to form glucose. These products may still be used for ketogenesis or lipid synthesis.
* Amino acids catabolized into both glucogenic and ketogenic products.
Degradation of an amino acid often involves deamination by moving its amino group to α-ketoglutarate, forming glutamate. This process involves transaminases, often the same as those used in amination during synthesis. In many vertebrates, the amino group is then removed through the urea cycle and is excreted in the form of urea. However, amino acid degradation can produce uric acid or ammonia instead. For example, serine dehydratase converts serine to pyruvate and ammonia.[100] After removal of one or more amino groups, the remainder of the molecule can sometimes be used to synthesize new amino acids, or it can be used for energy by entering glycolysis or the citric acid cycle, as detailed in image at right.
Complexation edit
Amino acids are bidentate ligands, forming transition metal amino acid complexes.[140]

Chemical analysis edit
The total nitrogen content of organic matter is mainly formed by the amino groups in proteins. The Total Kjeldahl Nitrogen (TKN) is a measure of nitrogen widely used in the analysis of (waste) water, soil, food, feed and organic matter in general. As the name suggests, the Kjeldahl method is applied. More sensitive methods are available.[141][142]
See also edit
Notes edit
- ^ The late discovery is explained by the fact that cysteine becomes oxidized to cystine in air.
- ^ Proline and other cyclic amino acids are an exception to this general formula. Cyclization of the α-amino acid creates the corresponding secondary amine. These are occasionally referred to as imino acids.
- ^ The L and D convention for amino acid configuration refers not to the optical activity of the amino acid itself but rather to the optical activity of the isomer of glyceraldehyde from which that amino acid can, in theory, be synthesized (D-glyceraldehyde is dextrorotatory; L-glyceraldehyde is levorotatory). An alternative convention is to use the (S) and (R) designators to specify the absolute configuration.[29] Almost all of the amino acids in proteins are (S) at the α carbon, with cysteine being (R) and glycine non-chiral.[30] Cysteine has its side chain in the same geometric location as the other amino acids, but the R/S terminology is reversed because sulfur has higher atomic number compared to the carboxyl oxygen which gives the side chain a higher priority by the Cahn-Ingold-Prelog sequence rules.
- ^ For example, ruminants such as cows obtain a number of amino acids via microbes in the first two stomach chambers.
References edit
- ^ Nelson DL, Cox MM (2005). Principles of Biochemistry (4th ed.). New York: W. H. Freeman. ISBN 0-7167-4339-6.
- ^ Flissi, Areski; Ricart, Emma; Campart, Clémentine; Chevalier, Mickael; Dufresne, Yoann; Michalik, Juraj; Jacques, Philippe; Flahaut, Christophe; Lisacek, Frédérique; Leclère, Valérie; Pupin, Maude (2020). "Norine: update of the nonribosomal peptide resource". Nucleic Acids Research. 48 (D1): D465–D469. doi:10.1093/nar/gkz1000. PMC 7145658. PMID 31691799.
- ^ Richard Cammack, ed. (2009). "Newsletter 2009". Biochemical Nomenclature Committee of IUPAC and NC-IUBMB. Pyrrolysine. Archived from the original on 12 September 2017. Retrieved 16 April 2012.
- ^ Rother, Michael; Krzycki, Joseph A. (1 January 2010). "Selenocysteine, Pyrrolysine, and the Unique Energy Metabolism of Methanogenic Archaea". Archaea. 2010: 1–14. doi:10.1155/2010/453642. ISSN 1472-3646. PMC 2933860. PMID 20847933.
- ^ Latham MC (1997). "Chapter 8. Body composition, the functions of food, metabolism and energy". Human nutrition in the developing world. Food and Nutrition Series – No. 29. Rome: Food and Agriculture Organization of the United Nations. Archived from the original on 8 October 2012. Retrieved 9 September 2012.
- ^ a b c "Nomenclature and Symbolism for Amino Acids and Peptides". IUPAC-IUB Joint Commission on Biochemical Nomenclature. 1983. Archived from the original on 9 October 2008. Retrieved 17 November 2008.
- ^ Vickery HB, Schmidt CL (1931). "The history of the discovery of the amino acids". Chem. Rev. 9 (2): 169–318. doi:10.1021/cr60033a001.
- ^ Hansen S (May 2015). "Die Entdeckung der proteinogenen Aminosäuren von 1805 in Paris bis 1935 in Illinois" (PDF) (in German). Berlin. Archived from the original (PDF) on 1 December 2017.
- ^ Vauquelin LN, Robiquet PJ (1806). "The discovery of a new plant principle in Asparagus sativus". Annales de Chimie. 57: 88–93.
- ^ a b Anfinsen CB, Edsall JT, Richards FM (1972). Advances in Protein Chemistry. New York: Academic Press. pp. 99, 103. ISBN 978-0-12-034226-6.
- ^ Wollaston WH (1810). "On cystic oxide, a new species of urinary calculus". Philosophical Transactions of the Royal Society. 100: 223–230. doi:10.1098/rstl.1810.0015. S2CID 110151163.
- ^ Baumann E (1884). "Über cystin und cystein". Z Physiol Chem. 8 (4): 299–305. Archived from the original on 14 March 2011. Retrieved 28 March 2011.
- ^ Braconnot HM (1820). "Sur la conversion des matières animales en nouvelles substances par le moyen de l'acide sulfurique". Annales de Chimie et de Physique. 2nd Series. 13: 113–125.
- ^ Simoni RD, Hill RL, Vaughan M (September 2002). "The discovery of the amino acid threonine: the work of William C. Rose [classical article]". The Journal of Biological Chemistry. 277 (37): E25. doi:10.1016/S0021-9258(20)74369-3. PMID 12218068. Archived from the original on 10 June 2019. Retrieved 4 July 2015.
- ^ McCoy RH, Meyer CE, Rose WC (1935). "Feeding Experiments with Mixtures of Highly Purified Amino Acids. VIII. Isolation and Identification of a New Essential Amino Acid". Journal of Biological Chemistry. 112: 283–302. doi:10.1016/S0021-9258(18)74986-7.
- ^ Menten, P. Dictionnaire de chimie: Une approche étymologique et historique. De Boeck, Bruxelles. link Archived 28 December 2019 at the Wayback Machine.
- ^ Harper D. "amino-". Online Etymology Dictionary. Archived from the original on 2 December 2017. Retrieved 19 July 2010.
- ^ Paal C (1894). "Ueber die Einwirkung von Phenyl-i-cyanat auf organische Aminosäuren". Berichte der Deutschen Chemischen Gesellschaft. 27: 974–979. doi:10.1002/cber.189402701205. Archived from the original on 25 July 2020.
- ^ Fruton JS (1990). "Chapter 5- Emil Fischer and Franz Hofmeister". Contrasts in Scientific Style: Research Groups in the Chemical and Biochemical Sciences. Vol. 191. American Philosophical Society. pp. 163–165. ISBN 978-0-87169-191-0.
- ^ "Alpha amino acid". Merriam-Webster Medical. Archived from the original on 3 January 2015. Retrieved 3 January 2015..
- ^ Clark, Jim (August 2007). "An introduction to amino acids". chemguide. Archived from the original on 30 April 2015. Retrieved 4 July 2015.
- ^ Jakubke HD, Sewald N (2008). "Amino acids". Peptides from A to Z: A Concise Encyclopedia. Germany: Wiley-VCH. p. 20. ISBN 9783527621170. Archived from the original on 17 May 2016. Retrieved 5 January 2016 – via Google Books.
- ^ Pollegioni L, Servi S, eds. (2012). Unnatural Amino Acids: Methods and Protocols. Methods in Molecular Biology. Vol. 794. Humana Press. p. v. doi:10.1007/978-1-61779-331-8. ISBN 978-1-61779-331-8. OCLC 756512314. S2CID 3705304.
- ^ Hertweck C (October 2011). "Biosynthesis and Charging of Pyrrolysine, the 22nd Genetically Encoded Amino Acid". Angewandte Chemie International Edition. 50 (41): 9540–9541. doi:10.1002/anie.201103769. PMID 21796749. S2CID 5359077.

- ^ a b "Chapter 1: Proteins are the Body's Worker Molecules". The Structures of Life. National Institute of General Medical Sciences. 27 October 2011. Archived from the original on 7 June 2014. Retrieved 20 May 2008.
- ^ Michal G, Schomburg D, eds. (2012). Biochemical Pathways: An Atlas of Biochemistry and Molecular Biology (2nd ed.). Oxford: Wiley-Blackwell. p. 5. ISBN 978-0-470-14684-2.
- ^ a b c Creighton TH (1993). "Chapter 1". Proteins: structures and molecular properties. San Francisco: W. H. Freeman. ISBN 978-0-7167-7030-5.
- ^ Genchi, Giuseppe (1 September 2017). "An overview on d-amino acids". Amino Acids. 49 (9): 1521–1533. doi:10.1007/s00726-017-2459-5. ISSN 1438-2199. PMID 28681245. S2CID 254088816.
- ^ Cahn, R.S.; Ingold, C.K.; Prelog, V. (1966). "Specification of Molecular Chirality". Angewandte Chemie International Edition. 5 (4): 385–415. doi:10.1002/anie.196603851.
- ^ Hatem SM (2006). "Gas chromatographic determination of Amino Acid Enantiomers in tobacco and bottled wines". University of Giessen. Archived from the original on 22 January 2009. Retrieved 17 November 2008.
- ^ a b c d e f Garrett, Reginald H.; Grisham, Charles M. (2010). Biochemistry (4th ed.). Belmont, CA: Brooks/Cole, Cengage Learning. pp. 74, 134–176, 430–442. ISBN 978-0-495-10935-8. OCLC 297392560.
- ^ Novikov, Anton P.; Safonov, Alexey V.; German, Konstantin E.; Grigoriev, Mikhail S. (1 December 2023). "What kind of interactions we may get moving from zwitter to "dritter" ions: C–O⋯Re(O4) and Re–O⋯Re(O4) anion⋯anion interactions make structural difference between L-histidinium perrhenate and pertechnetate". CrystEngComm. 26: 61–69. doi:10.1039/D3CE01164J. ISSN 1466-8033. S2CID 265572280.
- ^ Papp, Laura Vanda; Lu, Jun; Holmgren, Arne; Khanna, Kum Kum (1 July 2007). "From Selenium to Selenoproteins: Synthesis, Identity, and Their Role in Human Health". Antioxidants & Redox Signaling. 9 (7): 775–806. doi:10.1089/ars.2007.1528. ISSN 1523-0864. PMID 17508906.
- ^ Hao, Bing; Gong, Weimin; Ferguson, Tsuneo K.; James, Carey M.; Krzycki, Joseph A.; Chan, Michael K. (24 May 2002). "A New UAG-Encoded Residue in the Structure of a Methanogen Methyltransferase". Science. 296 (5572): 1462–1466. Bibcode:2002Sci...296.1462H. doi:10.1126/science.1069556. ISSN 0036-8075. PMID 12029132. S2CID 35519996.
- ^ Steinhardt, J.; Reynolds, J. A. (1969). Multiple equilibria in proteins. New York: Academic Press. pp. 176–21. ISBN 978-0126654509.
- ^ Brønsted, J. N. (1923). "Einige Bemerkungen über den Begriff der Säuren und Basen" [Remarks on the concept of acids and bases]. Recueil des Travaux Chimiques des Pays-Bas. 42 (8): 718–728. doi:10.1002/recl.19230420815.
- ^ a b Vollhardt, K. Peter C. (2007). Organic chemistry : structure and function. Neil Eric Schore (5th ed.). New York: W.H. Freeman. pp. 58–66. ISBN 978-0-7167-9949-8. OCLC 61448218.
- ^ Fennema OR (19 June 1996). Food Chemistry 3rd Ed. CRC Press. pp. 327–328. ISBN 978-0-8247-9691-4.
- ^ a b Ntountoumi C, Vlastaridis P, Mossialos D, Stathopoulos C, Iliopoulos I, Promponas V, et al. (November 2019). "Low complexity regions in the proteins of prokaryotes perform important functional roles and are highly conserved". Nucleic Acids Research. 47 (19): 9998–10009. doi:10.1093/nar/gkz730. PMC 6821194. PMID 31504783.
- ^ Urry DW (2004). "The change in Gibbs free energy for hydrophobic association: Derivation and evaluation by means of inverse temperature transitions". Chemical Physics Letters. 399 (1–3): 177–183. Bibcode:2004CPL...399..177U. doi:10.1016/S0009-2614(04)01565-9.
- ^ Marcotte EM, Pellegrini M, Yeates TO, Eisenberg D (October 1999). "A census of protein repeats". Journal of Molecular Biology. 293 (1): 151–60. doi:10.1006/jmbi.1999.3136. PMID 10512723.
- ^ Haerty W, Golding GB (October 2010). Bonen L (ed.). "Low-complexity sequences and single amino acid repeats: not just "junk" peptide sequences". Genome. 53 (10): 753–62. doi:10.1139/G10-063. PMID 20962881.
- ^ Magee T, Seabra MC (April 2005). "Fatty acylation and prenylation of proteins: what's hot in fat". Current Opinion in Cell Biology. 17 (2): 190–196. doi:10.1016/j.ceb.2005.02.003. PMID 15780596.
- ^ Pilobello KT, Mahal LK (June 2007). "Deciphering the glycocode: the complexity and analytical challenge of glycomics". Current Opinion in Chemical Biology. 11 (3): 300–305. doi:10.1016/j.cbpa.2007.05.002. PMID 17500024.
- ^ Smotrys JE, Linder ME (2004). "Palmitoylation of intracellular signaling proteins: regulation and function". Annual Review of Biochemistry. 73 (1): 559–587. doi:10.1146/annurev.biochem.73.011303.073954. PMID 15189153.
- ^ a b c d e "IUPAC-IUB Commission on Biochemical Nomenclature A One-Letter Notation for Amino Acid Sequences". Journal of Biological Chemistry. 243 (13): 3557–3559. 10 July 1968. doi:10.1016/S0021-9258(19)34176-6.
- ^ a b Saffran, M. (April 1998). "Amino acid names and parlor games: from trivial names to a one-letter code, amino acid names have strained students' memories. Is a more rational nomenclature possible?". Biochemical Education. 26 (2): 116–118. doi:10.1016/S0307-4412(97)00167-2.
- ^ a b c Adoga, Godwin I; Nicholson, Bh (January 1988). "Letters to the editor". Biochemical Education. 16 (1): 49. doi:10.1016/0307-4412(88)90026-X.
- ^ Kyte J, Doolittle RF (May 1982). "A simple method for displaying the hydropathic character of a protein". Journal of Molecular Biology. 157 (1): 105–132. CiteSeerX 10.1.1.458.454. doi:10.1016/0022-2836(82)90515-0. PMID 7108955.
- ^ Freifelder D (1983). Physical Biochemistry (2nd ed.). W. H. Freeman and Company. ISBN 978-0-7167-1315-9.[page needed]
- ^ Kozlowski LP (January 2017). "Proteome-pI: proteome isoelectric point database". Nucleic Acids Research. 45 (D1): D1112–D1116. doi:10.1093/nar/gkw978. PMC 5210655. PMID 27789699.
- ^ a b Hausman RE, Cooper GM (2004). The cell: a molecular approach. Washington, D.C: ASM Press. p. 51. ISBN 978-0-87893-214-6.
- ^ Codons can also be expressed by: CGN, AGR
- ^ codons can also be expressed by: CUN, UUR
- ^ Aasland R, Abrams C, Ampe C, Ball LJ, Bedford MT, Cesareni G, Gimona M, Hurley JH, Jarchau T, Lehto VP, Lemmon MA, Linding R, Mayer BJ, Nagai M, Sudol M, Walter U, Winder SJ (February 2002). "Normalization of nomenclature for peptide motifs as ligands of modular protein domains". FEBS Letters. 513 (1): 141–144. doi:10.1111/j.1432-1033.1968.tb00350.x. PMID 11911894.
- ^ IUPAC–IUB Commission on Biochemical Nomenclature (1972). "A one-letter notation for amino acid sequences". Pure and Applied Chemistry. 31 (4): 641–645. doi:10.1351/pac197231040639. PMID 5080161.
- ^ Codons can also be expressed by: CTN, ATH, TTR; MTY, YTR, ATA; MTY, HTA, YTG
- ^ Codons can also be expressed by: TWY, CAY, TGG
- ^ Codons can also be expressed by: NTR, VTY
- ^ Codons can also be expressed by: VAN, WCN, MGY, CGP
- ^ "HGVS: Sequence Variant Nomenclature, Protein Recommendations". Archived from the original on 24 September 2021. Retrieved 23 September 2021.
- ^ Suchanek M, Radzikowska A, Thiele C (April 2005). "Photo-leucine and photo-methionine allow identification of protein–protein interactions in living cells". Nature Methods. 2 (4): 261–267. doi:10.1038/nmeth752. PMID 15782218.
- ^ Rodnina MV, Beringer M, Wintermeyer W (January 2007). "How ribosomes make peptide bonds". Trends in Biochemical Sciences. 32 (1): 20–26. doi:10.1016/j.tibs.2006.11.007. PMID 17157507.
- ^ Driscoll DM, Copeland PR (2003). "Mechanism and regulation of selenoprotein synthesis". Annual Review of Nutrition. 23 (1): 17–40. doi:10.1146/annurev.nutr.23.011702.073318. PMID 12524431.
- ^ Krzycki JA (December 2005). "The direct genetic encoding of pyrrolysine". Current Opinion in Microbiology. 8 (6): 706–712. doi:10.1016/j.mib.2005.10.009. PMID 16256420.
- ^ Théobald-Dietrich A, Giegé R, Rudinger-Thirion J (2005). "Evidence for the existence in mRNAs of a hairpin element responsible for ribosome dependent pyrrolysine insertion into proteins". Biochimie. 87 (9–10): 813–817. doi:10.1016/j.biochi.2005.03.006. PMID 16164991.
- ^ Wong, J. T.-F. (1975). "A Co-Evolution Theory of the Genetic Code". Proceedings of the National Academy of Sciences. 72 (5): 1909–1912. Bibcode:1975PNAS...72.1909T. doi:10.1073/pnas.72.5.1909. PMC 432657. PMID 1057181.
- ^ Trifonov EN (December 2000). "Consensus temporal order of amino acids and evolution of the triplet code". Gene. 261 (1): 139–151. doi:10.1016/S0378-1119(00)00476-5. PMID 11164045.
- ^ Higgs PG, Pudritz RE (June 2009). "A thermodynamic basis for prebiotic amino acid synthesis and the nature of the first genetic code". Astrobiology. 9 (5): 483–90. arXiv:0904.0402. Bibcode:2009AsBio...9..483H. doi:10.1089/ast.2008.0280. PMID 19566427. S2CID 9039622.
- ^ Kryukov GV, Castellano S, Novoselov SV, Lobanov AV, Zehtab O, Guigó R, Gladyshev VN (May 2003). "Characterization of mammalian selenoproteomes". Science. 300 (5624): 1439–1443. Bibcode:2003Sci...300.1439K. doi:10.1126/science.1083516. PMID 12775843. S2CID 10363908. Archived from the original on 23 July 2018. Retrieved 12 June 2019.
- ^ Gromer S, Urig S, Becker K (January 2004). "The thioredoxin system—from science to clinic". Medicinal Research Reviews. 24 (1): 40–89. doi:10.1002/med.10051. PMID 14595672. S2CID 1944741.
- ^ Tjong H (2008). Modeling Electrostatic Contributions to Protein Folding and Binding (PhD thesis). Florida State University. p. 1 footnote. Archived from the original on 28 January 2020. Retrieved 28 January 2020.
- ^ Stewart L, Burgin AB (2005). "Whole Gene Synthesis: A Gene-O-Matic Future". Frontiers in Drug Design & Discovery. 1. Bentham Science Publishers: 299. doi:10.2174/1574088054583318. ISBN 978-1-60805-199-1. ISSN 1574-0889. Archived from the original on 14 April 2021. Retrieved 5 January 2016.
- ^ Elzanowski A, Ostell J (7 April 2008). "The Genetic Codes". National Center for Biotechnology Information (NCBI). Archived from the original on 20 August 2016. Retrieved 10 March 2010.
- ^ Xie J, Schultz PG (December 2005). "Adding amino acids to the genetic repertoire". Current Opinion in Chemical Biology. 9 (6): 548–554. doi:10.1016/j.cbpa.2005.10.011. PMID 16260173.
- ^ Wang Q, Parrish AR, Wang L (March 2009). "Expanding the genetic code for biological studies". Chemistry & Biology. 16 (3): 323–336. doi:10.1016/j.chembiol.2009.03.001. PMC 2696486. PMID 19318213.
- ^ Simon M (2005). Emergent computation: emphasizing bioinformatics. New York: AIP Press/Springer Science+Business Media. pp. 105–106. ISBN 978-0-387-22046-8.
- ^ Blenis J, Resh MD (December 1993). "Subcellular localization specified by protein acylation and phosphorylation". Current Opinion in Cell Biology. 5 (6): 984–989. doi:10.1016/0955-0674(93)90081-Z. PMID 8129952.
- ^ Vermeer C (March 1990). "Gamma-carboxyglutamate-containing proteins and the vitamin K-dependent carboxylase". The Biochemical Journal. 266 (3): 625–636. doi:10.1042/bj2660625. PMC 1131186. PMID 2183788.
- ^ Bhattacharjee A, Bansal M (March 2005). "Collagen Structure: the Madras triple helix and the current scenario". IUBMB Life. 57 (3): 161–172. doi:10.1080/15216540500090710. PMID 16036578. S2CID 7211864.
- ^ Park MH (February 2006). "The post-translational synthesis of a polyamine-derived amino acid, hypusine, in the eukaryotic translation initiation factor 5A (eIF5A)". Journal of Biochemistry. 139 (2): 161–169. doi:10.1093/jb/mvj034. PMC 2494880. PMID 16452303.
- ^ Curis E, Nicolis I, Moinard C, Osowska S, Zerrouk N, Bénazeth S, Cynober L (November 2005). "Almost all about citrulline in mammals". Amino Acids. 29 (3): 177–205. doi:10.1007/s00726-005-0235-4. PMID 16082501. S2CID 23877884.
- ^ Coxon KM, Chakauya E, Ottenhof HH, Whitney HM, Blundell TL, Abell C, Smith AG (August 2005). "Pantothenate biosynthesis in higher plants". Biochemical Society Transactions. 33 (Pt 4): 743–746. doi:10.1042/BST0330743. PMID 16042590.
- ^ Sakami W, Harrington H (1963). "Amino acid metabolism". Annual Review of Biochemistry. 32 (1): 355–398. doi:10.1146/annurev.bi.32.070163.002035. PMID 14144484.
- ^ Brosnan JT (April 2000). "Glutamate, at the interface between amino acid and carbohydrate metabolism". The Journal of Nutrition. 130 (4S Suppl): 988S–990S. doi:10.1093/jn/130.4.988S. PMID 10736367.
- ^ Young VR, Ajami AM (September 2001). "Glutamine: the emperor or his clothes?". The Journal of Nutrition. 131 (9 Suppl): 2449S–2459S, 2486S–2487S. doi:10.1093/jn/131.9.2449S. PMID 11533293.
- ^ Young VR (August 1994). "Adult amino acid requirements: the case for a major revision in current recommendations". The Journal of Nutrition. 124 (8 Suppl): 1517S–1523S. doi:10.1093/jn/124.suppl_8.1517S. PMID 8064412.
- ^ Fürst P, Stehle P (June 2004). "What are the essential elements needed for the determination of amino acid requirements in humans?". The Journal of Nutrition. 134 (6 Suppl): 1558S–1565S. doi:10.1093/jn/134.6.1558S. PMID 15173430.
- ^ Reeds PJ (July 2000). "Dispensable and indispensable amino acids for humans". The Journal of Nutrition. 130 (7): 1835S–1840S. doi:10.1093/jn/130.7.1835S. PMID 10867060.
- ^ Imura K, Okada A (January 1998). "Amino acid metabolism in pediatric patients". Nutrition. 14 (1): 143–148. doi:10.1016/S0899-9007(97)00230-X. PMID 9437700.
- ^ Lourenço R, Camilo ME (2002). "Taurine: a conditionally essential amino acid in humans? An overview in health and disease". Nutricion Hospitalaria. 17 (6): 262–270. PMID 12514918.
- ^ Broadley KJ (March 2010). "The vascular effects of trace amines and amphetamines". Pharmacology & Therapeutics. 125 (3): 363–375. doi:10.1016/j.pharmthera.2009.11.005. PMID 19948186.
- ^ Lindemann L, Hoener MC (May 2005). "A renaissance in trace amines inspired by a novel GPCR family". Trends in Pharmacological Sciences. 26 (5): 274–281. doi:10.1016/j.tips.2005.03.007. PMID 15860375.
- ^ Wang X, Li J, Dong G, Yue J (February 2014). "The endogenous substrates of brain CYP2D". European Journal of Pharmacology. 724: 211–218. doi:10.1016/j.ejphar.2013.12.025. PMID 24374199.
- ^ Hylin JW (1969). "Toxic peptides and amino acids in foods and feeds". Journal of Agricultural and Food Chemistry. 17 (3): 492–496. doi:10.1021/jf60163a003.
- ^ Savelieva KV, Zhao S, Pogorelov VM, Rajan I, Yang Q, Cullinan E, Lanthorn TH (2008). Bartolomucci A (ed.). "Genetic disruption of both tryptophan hydroxylase genes dramatically reduces serotonin and affects behavior in models sensitive to antidepressants". PLOS ONE. 3 (10): e3301. Bibcode:2008PLoSO...3.3301S. doi:10.1371/journal.pone.0003301. PMC 2565062. PMID 18923670.
- ^ Shemin D, Rittenberg D (December 1946). "The biological utilization of glycine for the synthesis of the protoporphyrin of hemoglobin". The Journal of Biological Chemistry. 166 (2): 621–625. doi:10.1016/S0021-9258(17)35200-6. PMID 20276176. Archived from the original on 7 May 2022. Retrieved 3 November 2008.
- ^ Tejero J, Biswas A, Wang ZQ, Page RC, Haque MM, Hemann C, Zweier JL, Misra S, Stuehr DJ (November 2008). "Stabilization and characterization of a heme-oxy reaction intermediate in inducible nitric-oxide synthase". The Journal of Biological Chemistry. 283 (48): 33498–33507. doi:10.1074/jbc.M806122200. PMC 2586280. PMID 18815130.
- ^ Rodríguez-Caso C, Montañez R, Cascante M, Sánchez-Jiménez F, Medina MA (August 2006). "Mathematical modeling of polyamine metabolism in mammals". The Journal of Biological Chemistry. 281 (31): 21799–21812. doi:10.1074/jbc.M602756200. PMID 16709566.
- ^ a b Stryer L, Berg JM, Tymoczko JL (2002). Biochemistry (5th ed.). New York: W.H. Freeman. pp. 693–698. ISBN 978-0-7167-4684-3.
- ^ Petroff OA (December 2002). "GABA and glutamate in the human brain". The Neuroscientist. 8 (6): 562–573. doi:10.1177/1073858402238515. PMID 12467378. S2CID 84891972.
- ^ Turner EH, Loftis JM, Blackwell AD (March 2006). "Serotonin a la carte: supplementation with the serotonin precursor 5-hydroxytryptophan". Pharmacology & Therapeutics. 109 (3): 325–338. doi:10.1016/j.pharmthera.2005.06.004. PMID 16023217. S2CID 2563606. Archived from the original on 13 April 2020. Retrieved 12 June 2019.
- ^ Kostrzewa RM, Nowak P, Kostrzewa JP, Kostrzewa RA, Brus R (March 2005). "Peculiarities of L-DOPA treatment of Parkinson's disease". Amino Acids. 28 (2): 157–164. doi:10.1007/s00726-005-0162-4. PMID 15750845. S2CID 33603501.
- ^ Heby O, Persson L, Rentala M (August 2007). "Targeting the polyamine biosynthetic enzymes: a promising approach to therapy of African sleeping sickness, Chagas' disease, and leishmaniasis". Amino Acids. 33 (2): 359–366. doi:10.1007/s00726-007-0537-9. PMID 17610127. S2CID 26273053.
- ^ Rosenthal GA (2001). "L-Canavanine: a higher plant insecticidal allelochemical". Amino Acids. 21 (3): 319–330. doi:10.1007/s007260170017. PMID 11764412. S2CID 3144019.
- ^ Hammond, Andrew C. (1 May 1995). "Leucaena toxicosis and its control in ruminants". Journal of Animal Science. 73 (5): 1487–1492. doi:10.2527/1995.7351487x. PMID 7665380. Archived from the original on 7 May 2022. Retrieved 7 May 2022.
- ^ a b Leuchtenberger W, Huthmacher K, Drauz K (November 2005). "Biotechnological production of amino acids and derivatives: current status and prospects". Applied Microbiology and Biotechnology. 69 (1): 1–8. doi:10.1007/s00253-005-0155-y. PMID 16195792. S2CID 24161808.
- ^ Ashmead HD (1993). The Role of Amino Acid Chelates in Animal Nutrition. Westwood: Noyes Publications.
- ^ Garattini S (April 2000). "Glutamic acid, twenty years later". The Journal of Nutrition. 130 (4S Suppl): 901S–909S. doi:10.1093/jn/130.4.901S. PMID 10736350.
- ^ Stegink LD (July 1987). "The aspartame story: a model for the clinical testing of a food additive". The American Journal of Clinical Nutrition. 46 (1 Suppl): 204–215. doi:10.1093/ajcn/46.1.204. PMID 3300262.
- ^ a b Drauz K, Grayson I, Kleemann A, Krimmer HP, Leuchtenberger W, Weckbecker C (2007). "Amino Acids". Ullmann's Encyclopedia of Industrial Chemistry. Weinheim: Wiley-VCH. doi:10.1002/14356007.a02_057.pub2. ISBN 978-3527306732.
- ^ Hanessian S (1993). "Reflections on the total synthesis of natural products: Art, craft, logic, and the chiron approach". Pure and Applied Chemistry. 65 (6): 1189–1204. doi:10.1351/pac199365061189. S2CID 43992655.
- ^ Blaser HU (1992). "The chiral pool as a source of enantioselective catalysts and auxiliaries". Chemical Reviews. 92 (5): 935–952. doi:10.1021/cr00013a009.
- ^ Ashmead HD (1986). Foliar Feeding of Plants with Amino Acid Chelates. Park Ridge: Noyes Publications.
- ^ Sanda F, Endo T (1999). "Syntheses and functions of polymers based on amino acids". Macromolecular Chemistry and Physics. 200 (12): 2651–2661. doi:10.1002/(SICI)1521-3935(19991201)200:12<2651::AID-MACP2651>3.0.CO;2-P.
- ^ Gross RA, Kalra B (August 2002). "Biodegradable polymers for the environment". Science. 297 (5582): 803–807. Bibcode:2002Sci...297..803G. doi:10.1126/science.297.5582.803. PMID 12161646. Archived from the original on 25 July 2020. Retrieved 12 June 2019.
- ^ Low KC, Wheeler AP, Koskan LP (1996). Commercial poly(aspartic acid) and Its Uses. Advances in Chemistry Series. Vol. 248. Washington, D.C.: American Chemical Society.
- ^ Thombre SM, Sarwade BD (2005). "Synthesis and Biodegradability of Polyaspartic Acid: A Critical Review". Journal of Macromolecular Science, Part A. 42 (9): 1299–1315. doi:10.1080/10601320500189604. S2CID 94818855.
- ^ Jones RC, Buchanan BB, Gruissem W (2000). Biochemistry & molecular biology of plants. Rockville, Md: American Society of Plant Physiologists. pp. 371–372. ISBN 978-0-943088-39-6.
- ^ Brosnan JT, Brosnan ME (June 2006). "The sulfur-containing amino acids: an overview". The Journal of Nutrition. 136 (6 Suppl): 1636S–1640S. doi:10.1093/jn/136.6.1636S. PMID 16702333.
- ^ Kivirikko KI, Pihlajaniemi T (1998). "Collagen Hydroxylases and the Protein Disulfide Isomerase Subunit of Prolyl 4-Hydroxylases". Advances in Enzymology and Related Areas of Molecular Biology. Advances in Enzymology – and Related Areas of Molecular Biology. Vol. 72. pp. 325–398. doi:10.1002/9780470123188.ch9. ISBN 9780470123188. PMID 9559057.
- ^ Whitmore L, Wallace BA (May 2004). "Analysis of peptaibol sequence composition: implications for in vivo synthesis and channel formation". European Biophysics Journal. 33 (3): 233–237. doi:10.1007/s00249-003-0348-1. PMID 14534753. S2CID 24638475.
- ^ Alexander L, Grierson D (October 2002). "Ethylene biosynthesis and action in tomato: a model for climacteric fruit ripening". Journal of Experimental Botany. 53 (377): 2039–2055. doi:10.1093/jxb/erf072. PMID 12324528.
- ^ a b Kitadai, Norio; Maruyama, Shigenori (2018). "Origins of building blocks of life: A review". Geoscience Frontiers. 9 (4): 1117–1153. Bibcode:2018GeoFr...9.1117K. doi:10.1016/j.gsf.2017.07.007. S2CID 102659869.
- ^ Danchin, Antoine (12 June 2017). "From chemical metabolism to life: the origin of the genetic coding process". Beilstein Journal of Organic Chemistry. 13 (1): 1119–1135. doi:10.3762/bjoc.13.111. ISSN 1860-5397. PMC 5480338. PMID 28684991.
- ^ a b Frenkel-Pinter, Moran; Samanta, Mousumi; Ashkenasy, Gonen; Leman, Luke J. (10 June 2020). "Prebiotic Peptides: Molecular Hubs in the Origin of Life". Chemical Reviews. 120 (11): 4707–4765. doi:10.1021/acs.chemrev.9b00664. ISSN 0009-2665. PMID 32101414. S2CID 211536416.
- ^ Milner-White, E. James (6 December 2019). "Protein three-dimensional structures at the origin of life". Interface Focus. 9 (6): 20190057. doi:10.1098/rsfs.2019.0057. PMC 6802138. PMID 31641431.
- ^ Chatterjee, Sankar; Yadav, Surya (June 2022). "The Coevolution of Biomolecules and Prebiotic Information Systems in the Origin of Life: A Visualization Model for Assembling the First Gene". Life. 12 (6): 834. Bibcode:2022Life...12..834C. doi:10.3390/life12060834. ISSN 2075-1729. PMC 9225589. PMID 35743865.
- ^ Kirschning, Andreas (26 May 2021). "The coenzyme/protein pair and the molecular evolution of life". Natural Product Reports. 38 (5): 993–1010. doi:10.1039/D0NP00037J. ISSN 1460-4752. PMID 33206101. S2CID 227037164.
- ^ Elmore DT, Barrett GC (1998). Amino acids and peptides. Cambridge, UK: Cambridge University Press. pp. 48–60. ISBN 978-0-521-46827-5.
- ^ Gutteridge A, Thornton JM (November 2005). "Understanding nature's catalytic toolkit". Trends in Biochemical Sciences. 30 (11): 622–629. doi:10.1016/j.tibs.2005.09.006. PMID 16214343.
- ^ Ibba M, Söll D (May 2001). "The renaissance of aminoacyl-tRNA synthesis". EMBO Reports. 2 (5): 382–387. doi:10.1093/embo-reports/kve095. PMC 1083889. PMID 11375928.
- ^ Lengyel P, Söll D (June 1969). "Mechanism of protein biosynthesis". Bacteriological Reviews. 33 (2): 264–301. doi:10.1128/MMBR.33.2.264-301.1969. PMC 378322. PMID 4896351.
- ^ Wu G, Fang YZ, Yang S, Lupton JR, Turner ND (March 2004). "Glutathione metabolism and its implications for health". The Journal of Nutrition. 134 (3): 489–492. doi:10.1093/jn/134.3.489. PMID 14988435.
- ^ Meister A (November 1988). "Glutathione metabolism and its selective modification". The Journal of Biological Chemistry. 263 (33): 17205–17208. doi:10.1016/S0021-9258(19)77815-6. PMID 3053703.
- ^ Carpino LA (1992). "1-Hydroxy-7-azabenzotriazole. An efficient peptide coupling additive". Journal of the American Chemical Society. 115 (10): 4397–4398. doi:10.1021/ja00063a082.
- ^ Marasco D, Perretta G, Sabatella M, Ruvo M (October 2008). "Past and future perspectives of synthetic peptide libraries". Current Protein & Peptide Science. 9 (5): 447–467. doi:10.2174/138920308785915209. PMID 18855697.
- ^ Konara S, Gagnona K, Clearfield A, Thompson C, Hartle J, Ericson C, Nelson C (2010). "Structural determination and characterization of copper and zinc bis-glycinates with X-ray crystallography and mass spectrometry". Journal of Coordination Chemistry. 63 (19): 3335–3347. doi:10.1080/00958972.2010.514336. S2CID 94822047.
- ^ Stipanuk MH (2006). Biochemical, physiological, & molecular aspects of human nutrition (2nd ed.). Saunders Elsevier.
- ^ Dghaym RD, Dhawan R, Arndtsen BA (September 2001). "The Use of Carbon Monoxide and Imines as Peptide Derivative Synthons: A Facile Palladium-Catalyzed Synthesis of α-Amino Acid Derived Imidazolines". Angewandte Chemie. 40 (17): 3228–3230. doi:10.1002/(SICI)1521-3773(19980703)37:12<1634::AID-ANIE1634>3.0.CO;2-C. PMID 29712039.
- ^ Muñoz-Huerta RF, Guevara-Gonzalez RG, Contreras-Medina LM, Torres-Pacheco I, Prado-Olivarez J, Ocampo-Velazquez RV (August 2013). "A review of methods for sensing the nitrogen status in plants: advantages, disadvantages and recent advances". Sensors. 13 (8). Basel, Switzerland: 10823–43. Bibcode:2013Senso..1310823M. doi:10.3390/s130810823. PMC 3812630. PMID 23959242.
- ^ Martin PD, Malley DF, Manning G, Fuller L (2002). "Determination of soil organic carbon and nitrogen at thefield level using near-infrared spectroscopy". Canadian Journal of Soil Science. 82 (4): 413–422. doi:10.4141/S01-054.
Further reading edit
- Tymoczko JL (2012). "Protein Composition and Structure". Biochemistry. New York: W. H. Freeman and company. pp. 28–31. ISBN 9781429229364.
- Doolittle RF (1989). "Redundancies in protein sequences". In Fasman GD (ed.). Predictions of Protein Structure and the Principles of Protein Conformation. New York: Plenum Press. pp. 599–623. ISBN 978-0-306-43131-9. LCCN 89008555.
- Nelson DL, Cox MM (2000). Lehninger Principles of Biochemistry (3rd ed.). Worth Publishers. ISBN 978-1-57259-153-0. LCCN 99049137.
- Meierhenrich U (2008). Amino acids and the asymmetry of life (PDF). Berlin: Springer Verlag. ISBN 978-3-540-76885-2. LCCN 2008930865. Archived from the original (PDF) on 12 January 2012.
External links edit
 Media related to Amino acids at Wikimedia Commons
Media related to Amino acids at Wikimedia Commons