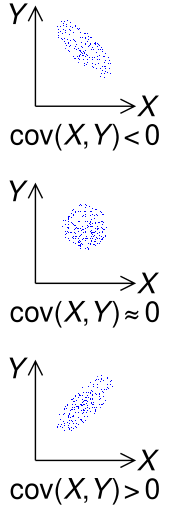
The sign of the covariance of two random variables X and Y
The sign of the covariance, therefore, shows the tendency in the linear relationship between the variables. If greater values of one variable mainly correspond with greater values of the other variable, and the same holds for lesser values (that is, the variables tend to show similar behavior), the covariance is positive.[2] In the opposite case, when greater values of one variable mainly correspond to lesser values of the other (that is, the variables tend to show opposite behavior), the covariance is negative. The magnitude of the covariance is the geometric mean of the variances that are in common for the two random variables. The correlation coefficient normalizes the covariance by dividing by the geometric mean of the total variances for the two random variables.
A distinction must be made between (1) the covariance of two random variables, which is a populationparameter that can be seen as a property of the joint probability distribution, and (2) the sample covariance, which in addition to serving as a descriptor of the sample, also serves as an estimated value of the population parameter.
where is the expected value of , also known as the mean of . The covariance is also sometimes denoted or , in analogy to variance. By using the linearity property of expectations, this can be simplified to the expected value of their product minus the product of their expected values:
The units of measurement of the covariance are those of times those of . By contrast, correlation coefficients, which depend on the covariance, are a dimensionless measure of linear dependence. (In fact, correlation coefficients can simply be understood as a normalized version of covariance.)
If the (real) random variable pair can take on the values for , with equal probabilities , then the covariance can be equivalently written in terms of the means and as
It can also be equivalently expressed, without directly referring to the means, as[5]
More generally, if there are possible realizations of , namely but with possibly unequal probabilities for , then the covariance is
In the case where two discrete random variables and have a joint probability distribution, represented by elements corresponding to the joint probabilities of , the covariance is calculated using a double summation over the indices of the matrix:
Examplesedit
Consider 3 independent random variables and two constants .
In the special case, and , the covariance between and , is just the variance of and the name covariance is entirely appropriate.
Geometric interpretation of the covariance example. Each cuboid is theaxis-alignedbounding box of its point (x, y, f (x, y)), and the X and Y means (magenta point). The covariance is the sum of the volumes of the cuboids in the 1st and 3rd quadrants (red) minus those in the 2nd and 4th (blue).
Suppose that and have the following joint probability mass function,[6] in which the six central cells give the discrete joint probabilities of the six hypothetical realizations :
x
5
6
7
y
8
0
0.4
0.1
0.5
9
0.3
0
0.2
0.5
0.3
0.4
0.3
1
can take on three values (5, 6 and 7) while can take on two (8 and 9). Their means are and . Then,
Propertiesedit
Covariance with itselfedit
The variance is a special case of the covariance in which the two variables are identical (that is, in which one variable has the same distribution as the other):[4]: 121
Covariance of linear combinationsedit
If , , , and are real-valued random variables and are real-valued constants, then the following facts are a consequence of the definition of covariance:
For a sequence of random variables in real-valued, and constants , we have
Hoeffding's covariance identityedit
A useful identity to compute the covariance between two random variables is the Hoeffding's covariance identity:[7]
where is the joint cumulative distribution function of the random vector and are the marginals.
Uncorrelatedness and independenceedit
Random variables whose covariance is zero are called uncorrelated.[4]: 121 Similarly, the components of random vectors whose covariance matrix is zero in every entry outside the main diagonal are also called uncorrelated.
The converse, however, is not generally true. For example, let be uniformly distributed in and let . Clearly, and are not independent, but
In this case, the relationship between and is non-linear, while correlation and covariance are measures of linear dependence between two random variables. This example shows that if two random variables are uncorrelated, that does not in general imply that they are independent. However, if two variables are jointly normally distributed (but not if they are merely individually normally distributed), uncorrelatedness does imply independence.[9]
and whose covariance is positive are called positively correlated, which implies if then likely . Conversely, and with negative covariance are negatively correlated, and if then likely .
Relationship to inner productsedit
Many of the properties of covariance can be extracted elegantly by observing that it satisfies similar properties to those of an inner product:
In fact these properties imply that the covariance defines an inner product over the quotient vector space obtained by taking the subspace of random variables with finite second moment and identifying any two that differ by a constant. (This identification turns the positive semi-definiteness above into positive definiteness.) That quotient vector space is isomorphic to the subspace of random variables with finite second moment and mean zero; on that subspace, the covariance is exactly the L2 inner product of real-valued functions on the sample space.
As a result, for random variables with finite variance, the inequality
Proof: If , then it holds trivially. Otherwise, let random variable
Then we have
Calculating the sample covarianceedit
The sample covariances among variables based on observations of each, drawn from an otherwise unobserved population, are given by the matrix with the entries
which is an estimate of the covariance between variable and variable .
The sample mean and the sample covariance matrix are unbiased estimates of the mean and the covariance matrix of the random vector, a vector whose jth element is one of the random variables. The reason the sample covariance matrix has in the denominator rather than is essentially that the population mean is not known and is replaced by the sample mean . If the population mean is known, the analogous unbiased estimate is given by
.
Generalizationsedit
Auto-covariance matrix of real random vectorsedit
For a vector of jointly distributed random variables with finite second moments, its auto-covariance matrix (also known as the variance–covariance matrix or simply the covariance matrix) (also denoted by or ) is defined as[10]: 335
Let be a random vector with covariance matrix Σ, and let A be a matrix that can act on on the left. The covariance matrix of the matrix-vector product A X is:
Cross-covariance matrix of real random vectorsedit
For real random vectors and , the cross-covariance matrix is equal to[10]: 336
(Eq.2)
where is the transpose of the vector (or matrix) .
The -th element of this matrix is equal to the covariance between the i-th scalar component of and the j-th scalar component of . In particular, is the transpose of .
Cross-covariance sesquilinear form of random vectors in a real or complex Hilbert spaceedit
More generally let and , be Hilbert spaces over or with anti linear in the first variable, and let be resp. valued random variables.
Then the covariance of and is the sesquilinear form on
(anti linear in the first variable) given by
Numerical computationedit
When , the equation is prone to catastrophic cancellation if and are not computed exactly and thus should be avoided in computer programs when the data has not been centered before.[11]Numerically stable algorithms should be preferred in this case.[12]
Commentsedit
The covariance is sometimes called a measure of "linear dependence" between the two random variables. That does not mean the same thing as in the context of linear algebra (see linear dependence). When the covariance is normalized, one obtains the Pearson correlation coefficient, which gives the goodness of the fit for the best possible linear function describing the relation between the variables. In this sense covariance is a linear gauge of dependence.
Applicationsedit
In genetics and molecular biologyedit
Covariance is an important measure in biology. Certain sequences of DNA are conserved more than others among species, and thus to study secondary and tertiary structures of proteins, or of RNA structures, sequences are compared in closely related species. If sequence changes are found or no changes at all are found in noncoding RNA (such as microRNA), sequences are found to be necessary for common structural motifs, such as an RNA loop. In genetics, covariance serves a basis for computation of Genetic Relationship Matrix (GRM) (aka kinship matrix), enabling inference on population structure from sample with no known close relatives as well as inference on estimation of heritability of complex traits.
In the theory of evolution and natural selection, the price equation describes how a genetic trait changes in frequency over time. The equation uses a covariance between a trait and fitness, to give a mathematical description of evolution and natural selection. It provides a way to understand the effects that gene transmission and natural selection have on the proportion of genes within each new generation of a population.[13][14]
In meteorological and oceanographic data assimilationedit
The covariance matrix is important in estimating the initial conditions required for running weather forecast models, a procedure known as data assimilation. The 'forecast error covariance matrix' is typically constructed between perturbations around a mean state (either a climatological or ensemble mean). The 'observation error covariance matrix' is constructed to represent the magnitude of combined observational errors (on the diagonal) and the correlated errors between measurements (off the diagonal). This is an example of its widespread application to Kalman filtering and more general state estimation for time-varying systems.
In micrometeorologyedit
The eddy covariance technique is a key atmospherics measurement technique where the covariance between instantaneous deviation in vertical wind speed from the mean value and instantaneous deviation in gas concentration is the basis for calculating the vertical turbulent fluxes.
In signal processingedit
The covariance matrix is used to capture the spectral variability of a signal.[15]
^Oxford Dictionary of Statistics, Oxford University Press, 2002, p. 104.
^ abcdePark, Kun Il (2018). Fundamentals of Probability and Stochastic Processes with Applications to Communications. Springer. ISBN 9783319680743.
^Yuli Zhang; Huaiyu Wu; Lei Cheng (June 2012). "Some new deformation formulas about variance and covariance". Proceedings of 4th International Conference on Modelling, Identification and Control(ICMIC2012). pp. 987–992.
^"Covariance of X and Y | STAT 414/415". The Pennsylvania State University. Archived from the original on August 17, 2017. Retrieved August 4, 2019.
^Papoulis (1991). Probability, Random Variables and Stochastic Processes. McGraw-Hill.
^Siegrist, Kyle. "Covariance and Correlation". University of Alabama in Huntsville. Retrieved Oct 3, 2022.
^Dekking, Michel, ed. (2005). A modern introduction to probability and statistics: understandig why and how. Springer texts in statistics. London [Heidelberg]: Springer. ISBN 978-1-85233-896-1.
^ abGubner, John A. (2006). Probability and Random Processes for Electrical and Computer Engineers. Cambridge University Press. ISBN 978-0-521-86470-1.
^Schubert, Erich; Gertz, Michael (2018). "Numerically stable parallel computation of (Co-)variance". Proceedings of the 30th International Conference on Scientific and Statistical Database Management. Bozen-Bolzano, Italy: ACM Press. pp. 1–12. doi:10.1145/3221269.3223036. ISBN 978-1-4503-6505-5. S2CID 49665540.
^Price, George (1970). "Selection and covariance". Nature (journal). 227 (5257): 520–521. Bibcode:1970Natur.227..520P. doi:10.1038/227520a0. PMID 5428476. S2CID 4264723.
^Harman, Oren (2020). "When science mirrors life: on the origins of the Price equation". Philosophical Transactions of the Royal Society B: Biological Sciences. 375 (1797). royalsocietypublishing.org: 1–7. doi:10.1098/rstb.2019.0352. PMC7133509. PMID 32146891.
^Sahidullah, Md.; Kinnunen, Tomi (March 2016). "Local spectral variability features for speaker verification". Digital Signal Processing. 50: 1–11. doi:10.1016/j.dsp.2015.10.011.





![{\displaystyle \operatorname {cov} (X,Y)=\operatorname {E} {{\big [}(X-\operatorname {E} [X])(Y-\operatorname {E} [Y]){\big ]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f98a8bf924edb41a8025b5ffaa1b255b4a6f48b9)
![{\displaystyle \operatorname {E} [X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/44dd294aa33c0865f58e2b1bdaf44ebe911dbf93)


![{\displaystyle {\begin{aligned}\operatorname {cov} (X,Y)&=\operatorname {E} \left[\left(X-\operatorname {E} \left[X\right]\right)\left(Y-\operatorname {E} \left[Y\right]\right)\right]\\&=\operatorname {E} \left[XY-X\operatorname {E} \left[Y\right]-\operatorname {E} \left[X\right]Y+\operatorname {E} \left[X\right]\operatorname {E} \left[Y\right]\right]\\&=\operatorname {E} \left[XY\right]-\operatorname {E} \left[X\right]\operatorname {E} \left[Y\right]-\operatorname {E} \left[X\right]\operatorname {E} \left[Y\right]+\operatorname {E} \left[X\right]\operatorname {E} \left[Y\right]\\&=\operatorname {E} \left[XY\right]-\operatorname {E} \left[X\right]\operatorname {E} \left[Y\right],\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b82a8c24b0063ffd95d8624f460acaaacb2a99b3)


![{\displaystyle \operatorname {cov} (Z,W)=\operatorname {E} \left[(Z-\operatorname {E} [Z]){\overline {(W-\operatorname {E} [W])}}\right]=\operatorname {E} \left[Z{\overline {W}}\right]-\operatorname {E} [Z]\operatorname {E} \left[{\overline {W}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cc823fe25634365b1859a3ee206ca894203a9ee2)




![{\displaystyle \operatorname {E} [Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/639e8577c6faffc0471c7e123ead30970034e6d5)







![{\displaystyle \operatorname {cov} (X,Y)=\sum _{i=1}^{n}\sum _{j=1}^{n}p_{i,j}(x_{i}-E[X])(y_{j}-E[Y]).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b036eb4d41b2fb6291fda39c942f5720f4cf3329)













![{\displaystyle {\begin{aligned}\operatorname {cov} (X,Y)={}&\sigma _{XY}=\sum _{(x,y)\in S}f(x,y)\left(x-\mu _{X}\right)\left(y-\mu _{Y}\right)\\[4pt]={}&(0)(5-6)(8-8.5)+(0.4)(6-6)(8-8.5)+(0.1)(7-6)(8-8.5)+{}\\[4pt]&(0.3)(5-6)(9-8.5)+(0)(6-6)(9-8.5)+(0.2)(7-6)(9-8.5)\\[4pt]={}&{-0.1}\;.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8a80fa4db641ca7ddd6f7a3fee8620eed15321a7)












![{\displaystyle \operatorname {E} [XY]=\operatorname {E} [X]\cdot \operatorname {E} [Y].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c0c2870ec57051083bd6262aa4069a2500dfda44)
![{\displaystyle [-1,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/51e3b7f14a6f70e614728c583409a0b9a8b9de01)

![{\displaystyle {\begin{aligned}\operatorname {cov} (X,Y)&=\operatorname {cov} \left(X,X^{2}\right)\\&=\operatorname {E} \left[X\cdot X^{2}\right]-\operatorname {E} [X]\cdot \operatorname {E} \left[X^{2}\right]\\&=\operatorname {E} \left[X^{3}\right]-\operatorname {E} [X]\operatorname {E} \left[X^{2}\right]\\&=0-0\cdot \operatorname {E} [X^{2}]\\&=0.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/19b6f2d636d5ef9ba85b6350e49222109a28d665)
![{\displaystyle X>E[X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/166d8f9cb60b8835b723e34645e1f0c52a1852a5)
![{\displaystyle Y>E[Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/02c197c6857af01266e2ed7c29485cad5a15118d)
![{\displaystyle Y<E[Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3eef3a2a3d98417f1d7684c3a6e530909c1c7c73)










![{\displaystyle {\begin{aligned}0\leq \sigma ^{2}(Z)&=\operatorname {cov} \left(X-{\frac {\operatorname {cov} (X,Y)}{\sigma ^{2}(Y)}}Y,\;X-{\frac {\operatorname {cov} (X,Y)}{\sigma ^{2}(Y)}}Y\right)\\[12pt]&=\sigma ^{2}(X)-{\frac {(\operatorname {cov} (X,Y))^{2}}{\sigma ^{2}(Y)}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fc8741ab12cb5943efe9d8dbfeb455517bc63347)



![{\displaystyle \textstyle {\overline {\mathbf {q} }}=\left[q_{jk}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cb28ac928a2a379d039d27fb99d56dd21c1c027c)















![{\displaystyle {\begin{aligned}\operatorname {K} _{\mathbf {XX} }=\operatorname {cov} (\mathbf {X} ,\mathbf {X} )&=\operatorname {E} \left[(\mathbf {X} -\operatorname {E} [\mathbf {X} ])(\mathbf {X} -\operatorname {E} [\mathbf {X} ])^{\mathrm {T} }\right]\\&=\operatorname {E} \left[\mathbf {XX} ^{\mathrm {T} }\right]-\operatorname {E} [\mathbf {X} ]\operatorname {E} [\mathbf {X} ]^{\mathrm {T} }.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/15725714f72a46ffb0686bafdb209260b842ac39)

![{\displaystyle {\begin{aligned}\operatorname {cov} (\mathbf {AX} ,\mathbf {AX} )&=\operatorname {E} \left[\mathbf {AX(A} \mathbf {X)} ^{\mathrm {T} }\right]-\operatorname {E} [\mathbf {AX} ]\operatorname {E} \left[(\mathbf {A} \mathbf {X} )^{\mathrm {T} }\right]\\&=\operatorname {E} \left[\mathbf {AXX} ^{\mathrm {T} }\mathbf {A} ^{\mathrm {T} }\right]-\operatorname {E} [\mathbf {AX} ]\operatorname {E} \left[\mathbf {X} ^{\mathrm {T} }\mathbf {A} ^{\mathrm {T} }\right]\\&=\mathbf {A} \operatorname {E} \left[\mathbf {XX} ^{\mathrm {T} }\right]\mathbf {A} ^{\mathrm {T} }-\mathbf {A} \operatorname {E} [\mathbf {X} ]\operatorname {E} \left[\mathbf {X} ^{\mathrm {T} }\right]\mathbf {A} ^{\mathrm {T} }\\&=\mathbf {A} \left(\operatorname {E} \left[\mathbf {XX} ^{\mathrm {T} }\right]-\operatorname {E} [\mathbf {X} ]\operatorname {E} \left[\mathbf {X} ^{\mathrm {T} }\right]\right)\mathbf {A} ^{\mathrm {T} }\\&=\mathbf {A} \Sigma \mathbf {A} ^{\mathrm {T} }.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c1b2123c32a8acefc209a4f69d571ee1197a8c59)



![{\displaystyle {\begin{aligned}\operatorname {K} _{\mathbf {X} \mathbf {Y} }=\operatorname {cov} (\mathbf {X} ,\mathbf {Y} )&=\operatorname {E} \left[(\mathbf {X} -\operatorname {E} [\mathbf {X} ])(\mathbf {Y} -\operatorname {E} [\mathbf {Y} ])^{\mathrm {T} }\right]\\&=\operatorname {E} \left[\mathbf {X} \mathbf {Y} ^{\mathrm {T} }\right]-\operatorname {E} [\mathbf {X} ]\operatorname {E} [\mathbf {Y} ]^{\mathrm {T} }\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/99e6f5ef675f7bb826d04f206bd212d14632ab8c)















![{\displaystyle {\begin{aligned}\operatorname {K} _{X,Y}(h_{1},h_{2})=\operatorname {cov} (\mathbf {X} ,\mathbf {Y} )(h_{1},h_{2})&=\operatorname {E} \left[\langle h_{1},(\mathbf {X} -\operatorname {E} [\mathbf {X} ])\rangle _{1}\langle (\mathbf {Y} -\operatorname {E} [\mathbf {Y} ]),h_{2}\rangle _{2}\right]\\&=\operatorname {E} [\langle h_{1},\mathbf {X} \rangle _{1}\langle \mathbf {Y} ,h_{2}\rangle _{2}]-\operatorname {E} [\langle h,\mathbf {X} \rangle _{1}]\operatorname {E} [\langle \mathbf {Y} ,h_{2}\rangle _{2}]\\&=\langle h_{1},\operatorname {E} \left[(\mathbf {X} -\operatorname {E} [\mathbf {X} ])(\mathbf {Y} -\operatorname {E} [\mathbf {Y} ])^{\dagger }\right]h_{2}\rangle _{1}\\&=\langle h_{1},\left(\operatorname {E} [\mathbf {X} \mathbf {Y} ^{\dagger }]-\operatorname {E} [\mathbf {X} ]\operatorname {E} [\mathbf {Y} ]^{\dagger }\right)h_{2}\rangle _{1}\\\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a5e62db23468fadd6a7f877ed44ede2bfbc07365)
![{\displaystyle \operatorname {E} [XY]\approx \operatorname {E} [X]\operatorname {E} [Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5cc8091d0da21aa8f5a114797ba5113ddf534f69)
![{\displaystyle \operatorname {cov} (X,Y)=\operatorname {E} \left[XY\right]-\operatorname {E} \left[X\right]\operatorname {E} \left[Y\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bdf56a30f7ff1be354713f144bfd02ba949a77f4)
![{\displaystyle \operatorname {E} \left[XY\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/128f7734bafe2a92d25d3df5fbb614e1d22b2e45)
![{\displaystyle \operatorname {E} \left[X\right]\operatorname {E} \left[Y\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f05701ae57cc8e32cd812037d7ba5d3d433021d4)