


Summary
As described by the third of Newton's laws of motion of classical mechanics, all forces occur in pairs such that if one object exerts a force on another object, then the second object exerts an equal and opposite reaction force on the first.[1][2] The third law is also more generally stated as: "To every action there is always opposed an equal reaction: or the mutual actions of two bodies upon each other are always equal, and directed to contrary parts."[3] The attribution of which of the two forces is the action and which is the reaction is arbitrary. Either of the two can be considered the action, while the other is its associated reaction.
Examples edit
Interaction with ground edit
When something is exerting force on the ground, the ground will push back with equal force in the opposite direction. In certain fields of applied physics, such as biomechanics, this force by the ground is called 'ground reaction force'; the force by the object on the ground is viewed as the 'action'.
When someone wants to jump, he or she exerts additional downward force on the ground ('action'). Simultaneously, the ground exerts upward force on the person ('reaction'). If this upward force is greater than the person's weight, this will result in upward acceleration. When these forces are perpendicular to the ground, they are also called a normal force.
Likewise, the spinning wheels of a vehicle attempt to slide backward across the ground. If the ground is not too slippery, this results in a pair of friction forces: the 'action' by the wheel on the ground in backward direction, and the 'reaction' by the ground on the wheel in forward direction. This forward force propels the vehicle.
Gravitational forces edit
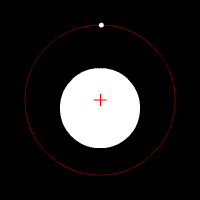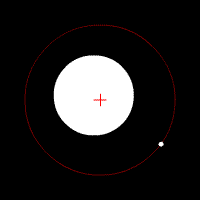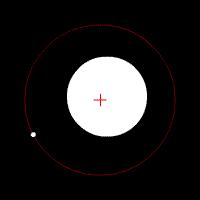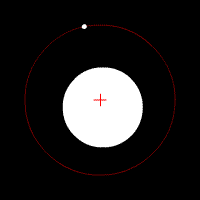
The Earth, among other planets, orbits the Sun because the Sun exerts a gravitational pull that acts as a centripetal force, holding the Earth to it, which would otherwise go shooting off into space. If the Sun's pull is considered an action, then Earth simultaneously exerts a reaction as a gravitational pull on the Sun. Earth's pull has the same amplitude as the Sun but in the opposite direction. Since the Sun's mass is so much larger than Earth's, the Sun does not generally appear to react to the pull of Earth, but in fact it does, as demonstrated in the animation (not to precise scale). A correct way of describing the combined motion of both objects (ignoring all other celestial bodies for the moment) is to say that they both orbit around the center of mass, referred to in astronomy as the barycenter, of the combined system.
Supported mass edit
Any mass on earth is pulled down by the gravitational force of the earth; this force is also called its weight. The corresponding 'reaction' is the gravitational force that mass exerts on the planet.
If the object is supported so that it remains at rest, for instance by a cable from which it is hanging, or by a surface underneath, or by a liquid on which it is floating, there is also a support force in upward direction (tension force, normal force, buoyant force, respectively). This support force is an 'equal and opposite' force; we know this not because of Newton's third law, but because the object remains at rest, so that the forces must be balanced.
To this support force there is also a 'reaction': the object pulls down on the supporting cable, or pushes down on the supporting surface or liquid. In this case, there are therefore four forces of equal magnitude:
- F1. gravitational force by earth on object (downward)
- F2. gravitational force by object on earth (upward)
- F3. force by support on object (upward)
- F4. force by object on support (downward)
Forces F1 and F2 are equal, due to Newton's third law; the same is true for forces F3 and F4. Forces F1 and F3 are equal if and only if the object is in equilibrium, and no other forces are applied. (This has nothing to do with Newton's third law.)
Mass on a spring edit
If a mass is hanging from a spring, the same considerations apply as before. However, if this system is then perturbed (e.g., the mass is given a slight kick upwards or downwards, say), the mass starts to oscillate up and down. Because of these accelerations (and subsequent decelerations), we conclude from Newton's second law that a net force is responsible for the observed change in velocity. The gravitational force pulling down on the mass is no longer equal to the upward elastic force of the spring. In the terminology of the previous section, F1 and F3 are no longer equal.
However, it is still true that F1 = F2 and F3 = F4, as this is required by Newton's third law.
Causal misinterpretation edit
The terms 'action' and 'reaction' have the misleading suggestion of causality, as if the 'action' is the cause and 'reaction' is the effect. It is therefore easy to think of the second force as being there because of the first, and even happening some time after the first. This is incorrect; the forces are perfectly simultaneous, and are there for the same reason.[4]
When the forces are caused by a person's volition (e.g. a soccer player kicks a ball), this volitional cause often leads to an asymmetric interpretation, where the force by the player on the ball is considered the 'action' and the force by the ball on the player, the 'reaction'. But physically, the situation is symmetric. The forces on ball and player are both explained by their nearness, which results in a pair of contact forces (ultimately due to electric repulsion). That this nearness is caused by a decision of the player has no bearing on the physical analysis. As far as the physics is concerned, the labels 'action' and 'reaction' can be flipped.[4]
'Equal and opposite' edit
One problem frequently observed by physics educators is that students tend to apply Newton's third law to pairs of 'equal and opposite' forces acting on the same object.[5][6][7] This is incorrect; the third law refers to forces on two different objects. In contrast, a book lying on a table is subject to a downward gravitational force (exerted by the earth) and to an upward normal force by the table, both forces acting on the same book. Since the book is not accelerating, these forces must be exactly balanced, according to Newton's second law. They are therefore 'equal and opposite', yet they are acting on the same object, hence they are not action-reaction forces in the sense of Newton's third law. The actual action-reaction forces in the sense of Newton's third law are the weight of the book (the attraction of the Earth on the book) and the book's upward gravitational force on the earth. The book also pushes down on the table and the table pushes upwards on the book. Moreover, the forces acting on the book are not always equally strong; they will be different if the book is pushed down by a third force, or if the table is slanted, or if the table-and-book system is in an accelerating elevator. The case of any number of forces acting on the same object is covered by considering the sum of all forces.
A possible cause of this problem is that the third law is often stated in an abbreviated form: For every action there is an equal and opposite reaction,[8] without the details, namely that these forces act on two different objects. Moreover, there is a causal connection between the weight of something and the normal force: if an object had no weight, it would not experience support force from the table, and the weight dictates how strong the support force will be. This causal relationship is not due to the third law but to other physical relations in the system.
Centripetal and centrifugal force edit
Another common mistake is to state that "the centrifugal force that an object experiences is the reaction to the centripetal force on that object."[9][10]
If an object were simultaneously subject to both a centripetal force and an equal and opposite centrifugal force, the resultant force would vanish and the object could not experience a circular motion. The centrifugal force is sometimes called a fictitious force or pseudo force, to underscore the fact that such a force only appears when calculations or measurements are conducted in non-inertial reference frames.[11]
See also edit
References edit
- ^ Taylor, John R. (2005). Classical Mechanics. University Science Books. pp. 17–18. ISBN 9781891389221.
- ^ Shapiro, Ilya L.; de Berredo-Peixoto, Guilherme (2013). Lecture Notes on Newtonian Mechanics: Lessons from Modern Concepts. Springer Science & Business Media. p. 116. ISBN 978-1461478256. Retrieved 28 September 2016.
- ^ This translation of the third law and the commentary following it can be found in the "Principia" on page 20 of volume 1 of the 1729 translation.
- ^ a b Brown, David (1989). "Students' concept of force: the importance of understanding Newton's third law". Phys. Educ. 24 (6): 353–358. Bibcode:1989PhyEd..24..353B. doi:10.1088/0031-9120/24/6/007. S2CID 250771986.
Even though one body might be more 'active' than the other body and thus might seem to initiate the interaction (e.g. a bowling ball striking a pin), the force body A exerts on body B is always simultaneous with the force B exerts on A.
- ^ Colin Terry and George Jones (1986). "Alternative frameworks: Newton's third law and conceptual change". European Journal of Science Education. 8 (3): 291–298. Bibcode:1986IJSEd...8..291T. doi:10.1080/0140528860080305.
This report highlights some of the difficulties that children experience with Newton's third law.
- ^ Cornelis Hellingman (1992). "Newton's Third Law Revisited". Physics Education. 27 (2): 112–115. Bibcode:1992PhyEd..27..112H. doi:10.1088/0031-9120/27/2/011. S2CID 250891975.
... following question in writing: Newton's third law speaks about 'action' and 'reaction'. Imagine a bottle of wine standing on a table. If the gravitational force that attracts the bottle is called the action, what force is the reaction to this force according to Newton's third law? The answer most frequently given was: 'The normal force the table exerts on the bottle'.
- ^ French, Anthony (1971), Newtonian Mechanics, p. 314,
… Newton's third law, that action and reaction are equal and opposite
- ^ Hall, Nancy. "Newton's Third Law Applied to Aerodynamics". NASA. Archived from the original on 2018-10-03.
for every action (force) in nature there is an equal and opposite reaction
- ^ Adair, Aaron (2013), Student Misconceptions about Newtonian Mechanics: Origins and Solutions through Changes to Instruction, The Ohio State University, Bibcode:2013PhDT.......476A,
This was attacked by Newton who tried to have the centripetal force on the planets (from gravitational interactions) be matched by the centrifugal force so there would be a balance of forces based on his third law of motion
- ^ Aiton, Eric (1995), Swetz, Frank; et al. (eds.), An Episode in the History of Celestial Mechanics and its Utility in the Teaching of Applied Mathematics, Learn from the Masters, The Mathematical Association of America, ISBN 978-0883857038,
... in one of his attacks on Leibniz written in 1711, Newton says that centrifugal force is always equal and opposite to the force of gravity by the third law of motion.
- ^ Singh, Chandralekha (2009), "Centripetal Acceleration: Often Forgotten or Misinterpreted", Physics Education, 44 (5): 464–468, arXiv:1602.06361, Bibcode:2009PhyEd..44..464S, doi:10.1088/0031-9120/44/5/001, S2CID 118701050,
Another difficulty is that students often consider the pseudo forces, e.g., the centrifugal force, as though they were real forces acting in an inertial reference frame.
Bibliography edit
- Feynman, R. P., Leighton and Sands (1970) The Feynman Lectures on Physics, Volume 1, Addison Wesley Longman, ISBN 0-201-02115-3.
- Resnick, R. and D. Halliday (1966) Physics, Part 1, John Wiley & Sons, New York, 646 pp + Appendices.
- Warren, J. W. (1965) The Teaching of Physics, Butterworths, London,130 pp.