


Summary
Ensembl genome database project is a scientific project at the European Bioinformatics Institute, which provides a centralized resource for geneticists, molecular biologists and other researchers studying the genomes of our own species and other vertebrates and model organisms.[2][3][4] Ensembl is one of several well known genome browsers for the retrieval of genomic information.
 | |
| Content | |
|---|---|
| Description | Ensembl |
| Contact | |
| Research center | |
| Primary citation | Yates, et al. (2020)[1] |
| Access | |
| Website | www |
Similar databases and browsers are found at NCBI and the University of California, Santa Cruz (UCSC).
History edit
The human genome consists of three billion base pairs, which code for approximately 20,000–25,000 genes. However the genome alone is of little use, unless the locations and relationships of individual genes can be identified. One option is manual annotation, whereby a team of scientists tries to locate genes using experimental data from scientific journals and public databases. However this is a slow, painstaking task. The alternative, known as automated annotation, is to use the power of computers to do the complex pattern-matching of protein to DNA.[5][6] The Ensembl project was launched in 1999 in response to the imminent completion of the Human Genome Project, with the initial goals of automatically annotate the human genome, integrate this annotation with available biological data and make all this knowledge publicly available.[2]
In the Ensembl project, sequence data are fed into the gene annotation system (a collection of software "pipelines" written in Perl) which creates a set of predicted gene locations and saves them in a MySQL database for subsequent analysis and display. Ensembl makes these data freely accessible to the world research community. All the data and code produced by the Ensembl project is available to download,[7] and there is also a publicly accessible database server allowing remote access. In addition, the Ensembl website provides computer-generated visual displays of much of the data.
Over time the project has expanded to include additional species (including key model organisms such as mouse, fruitfly and zebrafish) as well as a wider range of genomic data, including genetic variations and regulatory features. Since April 2009, a sister project, Ensembl Genomes, has extended the scope of Ensembl into invertebrate metazoa, plants, fungi, bacteria, and protists, focusing on providing taxonomic and evolutionary context to genes, whilst the original project continues to focus on vertebrates.[8][9]
As of 2020, Ensembl supported over 50 000 genomes across both Ensembl and Ensembl Genomes databases, adding some new innovative features such as Rapid Release, a new website designed to make genome annotation data available more quickly to users, and COVID-19, a new website to access to SARS-CoV-2 reference genome.
Displaying genomic data edit
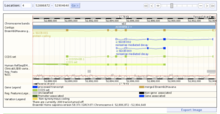
Central to the Ensembl concept is the ability to automatically generate graphical views of the alignment of genes and other genomic data against a reference genome. These are shown as data tracks, and individual tracks can be turned on and off, allowing the user to customise the display to suit their research interests. The interface also enables the user to zoom in to a region or move along the genome in either direction.
Other displays show data at varying levels of resolution, from whole karyotypes down to text-based representations of DNA and amino acid sequences, or present other types of display such as trees of similar genes (homologues) across a range of species. The graphics are complemented by tabular displays, and in many cases data can be exported directly from the page in a variety of standard file formats such as FASTA.
Externally produced data can also be added to the display by uploading a suitable file in one of the supported formats, such as BAM, BED, or PSL.
Graphics are generated using a suite of custom Perl modules based on GD, the standard Perl graphics display library.
Alternative access methods edit
In addition to its website, Ensembl provides a REST API and a Perl API[10] (Application Programming Interface) that models biological objects such as genes and proteins, allowing simple scripts to be written to retrieve data of interest. The same API is used internally by the web interface to display the data. It is divided in sections like the core API, the compara API (for comparative genomics data), the variation API (for accessing SNPs, SNVs, CNVs..), and the functional genomics API (to access regulatory data). The Ensembl website provides extensive information on how to install and use the API.
This software can be used to access the public MySQL database, avoiding the need to download enormous datasets. The users could even choose to retrieve data from the MySQL with direct SQL queries, but this requires an extensive knowledge of the current database schema.
Large datasets can be retrieved using the BioMart data-mining tool. It provides a web interface for downloading datasets using complex queries.
Last, there is an FTP server which can be used to download entire MySQL databases as well some selected data sets in other formats.
Current species edit
The annotated genomes include most fully sequenced vertebrates and selected model organisms. All of them are eukaryotes, there are no prokaryotes. As of 2022, there are 271 species registered, this includes:[11]
Open source/mirrors edit
All data part of the Ensembl project is open access and all software is open source, being freely available to the scientific community, under a CC BY 4.0 license. Currently, Ensembl database website is mirrored at four different locations worldwide to improve the service.
| Official mirror sites |
|---|
| UK (Sanger Institute) ---- main website |
| US West (Amazon AWS) ---- Cloud-based mirror on West Coast of United States |
| US East (Amazon AWS) ---- Cloud-based mirror on East Coast of United States |
| Asia (Amazon AWS) ---- Cloud-based mirror in Singapore |
See also edit
References edit
- ^ Yates A. D.; et al. (January 2020). "Ensembl 2020". Nucleic Acids Res. 48 (D1): D682–D688. doi:10.1093/nar/gkz966. PMC 7145704. PMID 31691826.
- ^ a b Hubbard, T. (1 January 2002). "The Ensembl genome database project". Nucleic Acids Research. 30 (1): 38–41. doi:10.1093/nar/30.1.38. PMC 99161. PMID 11752248.
- ^ Flicek P, Amode MR, Barrell D, et al. (November 2010). "Ensembl 2011". Nucleic Acids Res. 39 (Database issue): D800–D806. doi:10.1093/nar/gkq1064. PMC 3013672. PMID 21045057.
- ^ Flicek P, Aken BL, Ballester B, et al. (January 2010). "Ensembl's 10th year". Nucleic Acids Res. 38 (Database issue): D557–62. doi:10.1093/nar/gkp972. PMC 2808936. PMID 19906699.
- ^ Davis, Charles Patrick (29 March 2021). "Medical definition of Genome Annotation". Archived from the original on 14 June 2021. Retrieved 7 August 2022.
- ^ Curwen, Val; Eyras, Eduardo; Andrews, T. Daniel; Clarke, Laura; Mongin, Emmanuel; Searle, Steven M. J.; Clamp, Michele (May 2004). "The Ensembl automatic gene annotation system". Genome Research. 14 (5): 942–950. doi:10.1101/gr.1858004. ISSN 1088-9051. PMC 479124. PMID 15123590.
- ^ Ruffier, Magali; Kähäri, Andreas; Komorowska, Monika; Keenan, Stephen; Laird, Matthew; Longden, Ian; Proctor, Glenn; Searle, Steve; Staines, Daniel; Taylor, Kieron; Vullo, Alessandro; Yates, Andrew; Zerbino, Daniel; Flicek, Paul (January 2017). "Ensembl core software resources: storage and programmatic access for DNA sequence and genome annotation". Database. 2017 (1): bax020. doi:10.1093/database/bax020. PMC 5467575. PMID 28365736.
- ^ Hubbard, T. J. P.; Aken, B. L.; Ayling, S.; Ballester, B.; Beal, K.; Bragin, E.; Brent, S.; Chen, Y.; Clapham, P.; Clarke, L.; Coates, G. (January 2009). "Ensembl 2009". Nucleic Acids Research. 37 (Database issue): D690–697. doi:10.1093/nar/gkn828. ISSN 1362-4962. PMC 2686571. PMID 19033362.
- ^ Howe, Kevin L.; Contreras-Moreira, Bruno; De Silva, Nishadi; Maslen, Gareth; Akanni, Wasiu; Allen, James; Alvarez-Jarreta, Jorge; Barba, Matthieu; Bolser, Dan M.; Cambell, Lahcen; Carbajo, Manuel (8 January 2020). "Ensembl Genomes 2020-enabling non-vertebrate genomic research". Nucleic Acids Research. 48 (D1): D689–D695. doi:10.1093/nar/gkz890. ISSN 1362-4962. PMC 6943047. PMID 31598706.
- ^ Stabenau A, McVicker G, Melsopp C, Proctor G, Clamp M, Birney E (February 2004). "The Ensembl Core Software Libraries". Genome Research. 14 (5): 929–933. doi:10.1101/gr.1857204. PMC 479122. PMID 15123588.
- ^ "Species List". uswest.ensembl.org. Archived from the original on 6 August 2022. Retrieved 5 August 2022.
External links edit
- Official website
- Vega
- Pre-Ensembl
- Ensembl genomes
- UCSC Genome Browser
- NCBI
- Ensembl: Browsing chordate genomes on EBI Train OnLine