


Summary
The Cauchy distribution, named after Augustin Cauchy, is a continuous probability distribution. It is also known, especially among physicists, as the Lorentz distribution (after Hendrik Lorentz), Cauchy–Lorentz distribution, Lorentz(ian) function, or Breit–Wigner distribution. The Cauchy distribution is the distribution of the x-intercept of a ray issuing from with a uniformly distributed angle. It is also the distribution of the ratio of two independent normally distributed random variables with mean zero.


|
Probability density function  The purple curve is the standard Cauchy distribution | |||
|
Cumulative distribution function  | |||
| Parameters |
location (real) scale (real) | ||
|---|---|---|---|
| Support | |||
| CDF | |||
| Quantile | |||
| Mean | undefined | ||
| Median | |||
| Mode | |||
| Variance | undefined | ||
| MAD | |||
| Skewness | undefined | ||
| Excess kurtosis | undefined | ||
| Entropy | |||
| MGF | does not exist | ||
| CF | |||
| Fisher information | |||



![{\displaystyle {\frac {1}{\pi \gamma \,\left[1+\left({\frac {x-x_{0}}{\gamma }}\right)^{2}\right]}}\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2fa7448ba911130c1e33621f1859393d3f00af5c)

![{\displaystyle x_{0}+\gamma \,\tan[\pi (p-{\tfrac {1}{2}})]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6b28bd2a0c25cb1d212b29f0fc22baf6f84e3e0f)




The Cauchy distribution is often used in statistics as the canonical example of a "pathological" distribution since both its expected value and its variance are undefined (but see § Moments below). The Cauchy distribution does not have finite moments of order greater than or equal to one; only fractional absolute moments exist.[1] The Cauchy distribution has no moment generating function.
In mathematics, it is closely related to the Poisson kernel, which is the fundamental solution for the Laplace equation in the upper half-plane.
It is one of the few stable distributions with a probability density function that can be expressed analytically, the others being the normal distribution and the Lévy distribution.
History edit

A function with the form of the density function of the Cauchy distribution was studied geometrically by Fermat in 1659, and later was known as the witch of Agnesi, after Agnesi included it as an example in her 1748 calculus textbook. Despite its name, the first explicit analysis of the properties of the Cauchy distribution was published by the French mathematician Poisson in 1824, with Cauchy only becoming associated with it during an academic controversy in 1853.[2] Poisson noted that if the mean of observations following such a distribution were taken, the mean error[further explanation needed] did not converge to any finite number. As such, Laplace's use of the central limit theorem with such a distribution was inappropriate, as it assumed a finite mean and variance. Despite this, Poisson did not regard the issue as important, in contrast to Bienaymé, who was to engage Cauchy in a long dispute over the matter.
Constructions edit
Here are the most important constructions.
Rotational symmetry edit
If one stands in front of a line and kicks a ball with a direction (more precisely, an angle) uniformly at random towards the line, then the distribution of the point where the ball hits the line is a Cauchy distribution.
More formally, consider a point at in the x-y plane, and select a line passing the point, with its direction (angle with the -axis) chosen uniformly (between -90° and +90°) at random. The intersection of the line with the x-axis is the Cauchy distribution with location and scale .


This definition gives a simple way to sample from the standard Cauchy distribution. Let be a sample from a uniform distribution from , then we can generate a sample, from the standard Cauchy distribution using

![{\displaystyle [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)

When and are two independent normally distributed random variables with expected value 0 and variance 1, then the ratio has the standard Cauchy distribution.



More generally, if is a rotationally symmetric distribution on the plane, then the ratio has the standard Cauchy distribution.

Probability density function (PDF) edit
The Cauchy distribution is the probability distribution with the following probability density function (PDF)[1][3]
![{\displaystyle f(x;x_{0},\gamma )={\frac {1}{\pi \gamma \left[1+\left({\frac {x-x_{0}}{\gamma }}\right)^{2}\right]}}={1 \over \pi }\left[{\gamma \over (x-x_{0})^{2}+\gamma ^{2}}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2026aa2c40888a5189ad754d4bc21731a032575a)
where is the location parameter, specifying the location of the peak of the distribution, and is the scale parameter which specifies the half-width at half-maximum (HWHM), alternatively is full width at half maximum (FWHM). is also equal to half the interquartile range and is sometimes called the probable error. Augustin-Louis Cauchy exploited such a density function in 1827 with an infinitesimal scale parameter, defining what would now be called a Dirac delta function.

Properties of PDF edit
The maximum value or amplitude of the Cauchy PDF is , located at .


It is sometimes convenient to express the PDF in terms of the complex parameter


The special case when and is called the standard Cauchy distribution with the probability density function[4][5]



In physics, a three-parameter Lorentzian function is often used:
![{\displaystyle f(x;x_{0},\gamma ,I)={\frac {I}{\left[1+\left({\frac {x-x_{0}}{\gamma }}\right)^{2}\right]}}=I\left[{\gamma ^{2} \over (x-x_{0})^{2}+\gamma ^{2}}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ef75c5f31667a907f64963eb478d03f33f8374d2)
where is the height of the peak. The three-parameter Lorentzian function indicated is not, in general, a probability density function, since it does not integrate to 1, except in the special case where


Cumulative distribution function (CDF) edit
The Cauchy distribution is the probability distribution with the following cumulative distribution function (CDF):

and the quantile function (inverse cdf) of the Cauchy distribution is
![{\displaystyle Q(p;x_{0},\gamma )=x_{0}+\gamma \,\tan \left[\pi \left(p-{\tfrac {1}{2}}\right)\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/42c17241be79f1edbb111b82fc9a86ad55c9fd37)
It follows that the first and third quartiles are , and hence the interquartile range is .

For the standard distribution, the cumulative distribution function simplifies to arctangent function :


Other constructions edit
The standard Cauchy distribution is the Student's t-distribution with one degree of freedom, and so it may be constructed by any method that constructs the Student's t-distribution.
If is a positive-semidefinite covariance matrix with strictly positive diagonal entries, then for independent and identically distributed and any random -vector independent of and such that and (defining a categorical distribution) it holds that










Properties edit
The Cauchy distribution is an example of a distribution which has no mean, variance or higher moments defined. Its mode and median are well defined and are both equal to .
The Cauchy distribution is an infinitely divisible probability distribution. It is also a strictly stable distribution.[7]
Like all stable distributions, the location-scale family to which the Cauchy distribution belongs is closed under linear transformations with real coefficients. In addition, the Cauchy distribution is closed under linear fractional transformations with real coefficients.[8] In this connection, see also McCullagh's parametrization of the Cauchy distributions.
Sum of Cauchy distributions edit
If are IID samples from the standard Cauchy distribution, then their sample mean is also standard Cauchy distributed. In particular, the average does not converge to the mean, and so the standard Cauchy distribution does not follow the law of large numbers.


This can be proved by repeated integration with the PDF, or more conveniently, by using the characteristic function of the standard Cauchy distribution (see below):
![{\displaystyle \varphi _{X}(t)=\operatorname {E} \left[e^{iXt}\right]=e^{-|t|}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/57686177a5992b93dece0dba15fd1f64758dfb0d)


More generally, if are independent and Cauchy distributed with location parameters and scales , and are real numbers, then is Cauchy distributed with location and scale . We see that there is no law of large numbers for any weighted sum of independent Cauchy distributions.






This shows that the condition of finite variance in the central limit theorem cannot be dropped. It is also an example of a more generalized version of the central limit theorem that is characteristic of all stable distributions, of which the Cauchy distribution is a special case.
Central limit theorem edit
If are IID samples with PDF such that is finite, but nonzero, then converges in distribution to a Cauchy distribution with scale .[9]




Characteristic function edit
Let denote a Cauchy distributed random variable. The characteristic function of the Cauchy distribution is given by
![{\displaystyle \varphi _{X}(t)=\operatorname {E} \left[e^{iXt}\right]=\int _{-\infty }^{\infty }f(x;x_{0},\gamma )e^{ixt}\,dx=e^{ix_{0}t-\gamma |t|}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/90a76888a502d3e9959365d896466e4dee540d17)
which is just the Fourier transform of the probability density. The original probability density may be expressed in terms of the characteristic function, essentially by using the inverse Fourier transform:

The nth moment of a distribution is the nth derivative of the characteristic function evaluated at . Observe that the characteristic function is not differentiable at the origin: this corresponds to the fact that the Cauchy distribution does not have well-defined moments higher than the zeroth moment.

Kullback-Leibler divergence edit
The Kullback–Leibler divergence between two Cauchy distributions has the following symmetric closed-form formula:[10]

Any f-divergence between two Cauchy distributions is symmetric and can be expressed as a function of the chi-squared divergence.[11] Closed-form expression for the total variation, Jensen–Shannon divergence, Hellinger distance, etc are available.
Entropy edit
The entropy of the Cauchy distribution is given by:
![{\displaystyle {\begin{aligned}H(\gamma )&=-\int _{-\infty }^{\infty }f(x;x_{0},\gamma )\log(f(x;x_{0},\gamma ))\,dx\\[6pt]&=\log(4\pi \gamma )\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d648f0a9098d95824886093f233fb0681578a4eb)
The derivative of the quantile function, the quantile density function, for the Cauchy distribution is:
![{\displaystyle Q'(p;\gamma )=\gamma \,\pi \,{\sec }^{2}\left[\pi \left(p-{\tfrac {1}{2}}\right)\right].\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c98f59acfc3b417126a88a731035e87a4deaa16b)
The differential entropy of a distribution can be defined in terms of its quantile density,[12] specifically:

The Cauchy distribution is the maximum entropy probability distribution for a random variate for which
![{\displaystyle \operatorname {E} [\log(1+(X-x_{0})^{2}/\gamma ^{2})]=\log 4}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a7f6982d1d9f8690a4cd034887fe55c659e005b0)
In its standard form, it is the maximum entropy probability distribution for a random variate for which[13]
![{\displaystyle \operatorname {E} \!\left[\ln(1+X^{2})\right]=\ln 4.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d21003746c5e5935ead79eea3221bade73eac657)
Moments edit
The Cauchy distribution is usually used as an illustrative counterexample in elementary probability courses, as a distribution with no well-defined (or "indefinite") moments.
Sample moments edit
If we take IID samples from the standard Cauchy distribution, then the sequence of their sample mean is , which also has the standard Cauchy distribution. Consequently, no matter how many terms we take, the sample average does not converge.


Similarly, the sample variance also does not converge.


A typical trajectory of looks like long periods of slow convergence to zero, punctuated by large jumps away from zero, but never getting too far away. A typical trajectory of looks similar, but the jumps accumulate faster than the decay, diverging to infinity. These two kinds of trajectories are plotted in the figure.


Moments of sample lower than order 1 would converge to zero. Moments of sample higher than order 2 would diverge to infinity even faster than sample variance.
Mean edit
If a probability distribution has a density function , then the mean, if it exists, is given by

|
|
(1)
|

We may evaluate this two-sided improper integral by computing the sum of two one-sided improper integrals. That is,
|
|
(2)
|

for an arbitrary real number .

For the integral to exist (even as an infinite value), at least one of the terms in this sum should be finite, or both should be infinite and have the same sign. But in the case of the Cauchy distribution, both the terms in this sum (2) are infinite and have opposite sign. Hence (1) is undefined, and thus so is the mean.[14] When the mean of a probability distribution function (PDF) is undefined, no one can compute a reliable average over the experimental data points, regardless of the sample’s size.
Note that the Cauchy principal value of the mean of the Cauchy distribution is


Various results in probability theory about expected values, such as the strong law of large numbers, fail to hold for the Cauchy distribution.[14]
Smaller moments edit
The absolute moments for are defined. For we have


![{\displaystyle \operatorname {E} [|X|^{p}]=\gamma ^{p}\mathrm {sec} (\pi p/2).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/34e2a867bc2b1f3c8c5fe805aa71577f466e948c)
Higher moments edit
The Cauchy distribution does not have finite moments of any order. Some of the higher raw moments do exist and have a value of infinity, for example, the raw second moment:
![{\displaystyle {\begin{aligned}\operatorname {E} [X^{2}]&\propto \int _{-\infty }^{\infty }{\frac {x^{2}}{1+x^{2}}}\,dx=\int _{-\infty }^{\infty }1-{\frac {1}{1+x^{2}}}\,dx\\[8pt]&=\int _{-\infty }^{\infty }dx-\int _{-\infty }^{\infty }{\frac {1}{1+x^{2}}}\,dx=\int _{-\infty }^{\infty }dx-\pi =\infty .\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b821427592463519bb2fe3f38a52f61183af76cd)
By re-arranging the formula, one can see that the second moment is essentially the infinite integral of a constant (here 1). Higher even-powered raw moments will also evaluate to infinity. Odd-powered raw moments, however, are undefined, which is distinctly different from existing with the value of infinity. The odd-powered raw moments are undefined because their values are essentially equivalent to since the two halves of the integral both diverge and have opposite signs. The first raw moment is the mean, which, being odd, does not exist. (See also the discussion above about this.) This in turn means that all of the central moments and standardized moments are undefined since they are all based on the mean. The variance—which is the second central moment—is likewise non-existent (despite the fact that the raw second moment exists with the value infinity).

The results for higher moments follow from Hölder's inequality, which implies that higher moments (or halves of moments) diverge if lower ones do.
Moments of truncated distributions edit
Consider the truncated distribution defined by restricting the standard Cauchy distribution to the interval [−10100, 10100]. Such a truncated distribution has all moments (and the central limit theorem applies for i.i.d. observations from it); yet for almost all practical purposes it behaves like a Cauchy distribution.[15]
Estimation of parameters edit
Because the parameters of the Cauchy distribution do not correspond to a mean and variance, attempting to estimate the parameters of the Cauchy distribution by using a sample mean and a sample variance will not succeed.[16] For example, if an i.i.d. sample of size n is taken from a Cauchy distribution, one may calculate the sample mean as:

Although the sample values will be concentrated about the central value , the sample mean will become increasingly variable as more observations are taken, because of the increased probability of encountering sample points with a large absolute value. In fact, the distribution of the sample mean will be equal to the distribution of the observations themselves; i.e., the sample mean of a large sample is no better (or worse) an estimator of than any single observation from the sample. Similarly, calculating the sample variance will result in values that grow larger as more observations are taken.

Therefore, more robust means of estimating the central value and the scaling parameter are needed. One simple method is to take the median value of the sample as an estimator of and half the sample interquartile range as an estimator of . Other, more precise and robust methods have been developed [17][18] For example, the truncated mean of the middle 24% of the sample order statistics produces an estimate for that is more efficient than using either the sample median or the full sample mean.[19][20] However, because of the fat tails of the Cauchy distribution, the efficiency of the estimator decreases if more than 24% of the sample is used.[19][20]
Maximum likelihood can also be used to estimate the parameters and . However, this tends to be complicated by the fact that this requires finding the roots of a high degree polynomial, and there can be multiple roots that represent local maxima.[21] Also, while the maximum likelihood estimator is asymptotically efficient, it is relatively inefficient for small samples.[22][23] The log-likelihood function for the Cauchy distribution for sample size is:


Maximizing the log likelihood function with respect to and by taking the first derivative produces the following system of equations:


Note that

is a monotone function in and that the solution must satisfy

Solving just for requires solving a polynomial of degree ,[21] and solving just for requires solving a polynomial of degree . Therefore, whether solving for one parameter or for both parameters simultaneously, a numerical solution on a computer is typically required. The benefit of maximum likelihood estimation is asymptotic efficiency; estimating using the sample median is only about 81% as asymptotically efficient as estimating by maximum likelihood.[20][24] The truncated sample mean using the middle 24% order statistics is about 88% as asymptotically efficient an estimator of as the maximum likelihood estimate.[20] When Newton's method is used to find the solution for the maximum likelihood estimate, the middle 24% order statistics can be used as an initial solution for .



The shape can be estimated using the median of absolute values, since for location 0 Cauchy variables , the the shape parameter.

Multivariate Cauchy distribution edit
A random vector is said to have the multivariate Cauchy distribution if every linear combination of its components has a Cauchy distribution. That is, for any constant vector , the random variable should have a univariate Cauchy distribution.[25] The characteristic function of a multivariate Cauchy distribution is given by:





where and are real functions with a homogeneous function of degree one and a positive homogeneous function of degree one.[25] More formally:[25]




for all .

An example of a bivariate Cauchy distribution can be given by:[26]
![{\displaystyle f(x,y;x_{0},y_{0},\gamma )={1 \over 2\pi }\left[{\gamma \over ((x-x_{0})^{2}+(y-y_{0})^{2}+\gamma ^{2})^{3/2}}\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6d8819f3c50d69b56d61fe3055c18b1b53d37e50)
Note that in this example, even though the covariance between and is 0, and are not statistically independent.[26]

We also can write this formula for complex variable. Then the probability density function of complex cauchy is :
![{\displaystyle f(z;z_{0},\gamma )={1 \over 2\pi }\left[{\gamma \over (|z-z_{0}|^{2}+\gamma ^{2})^{3/2}}\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/de0257adbd6a9a7b9216baf7a6837e0da6255390)
Like how the standard Cauchy distribution is the Student t-distribution with one degree of freedom, the multidimensional Cauchy density is the multivariate Student distribution with one degree of freedom. The density of a dimension Student distribution with one degree of freedom is:

![{\displaystyle f({\mathbf {x} };{\mathbf {\mu } },{\mathbf {\Sigma } },k)={\frac {\Gamma \left({\frac {1+k}{2}}\right)}{\Gamma ({\frac {1}{2}})\pi ^{\frac {k}{2}}\left|{\mathbf {\Sigma } }\right|^{\frac {1}{2}}\left[1+({\mathbf {x} }-{\mathbf {\mu } })^{T}{\mathbf {\Sigma } }^{-1}({\mathbf {x} }-{\mathbf {\mu } })\right]^{\frac {1+k}{2}}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d9e1b5b8a0ffbbba9a4478b2acb4da449c1006d5)
The properties of multidimensional Cauchy distribution are then special cases of the multivariate Student distribution.
Transformation properties edit
- If then [27]
- If and are independent, then and
- If then
- McCullagh's parametrization of the Cauchy distributions:[28] Expressing a Cauchy distribution in terms of one complex parameter , define to mean . If then: where , , and are real numbers.
- Using the same convention as above, if then:[28] where is the circular Cauchy distribution.
















Lévy measure edit
The Cauchy distribution is the stable distribution of index 1. The Lévy–Khintchine representation of such a stable distribution of parameter is given, for by:


where

and can be expressed explicitly.[29] In the case of the Cauchy distribution, one has .


This last representation is a consequence of the formula

Related distributions edit
- Student's t distribution
- non-standardized Student's t distribution
- If independent, then
- If then
- If then
- If then
- The Cauchy distribution is a limiting case of a Pearson distribution of type 4[citation needed]
- The Cauchy distribution is a special case of a Pearson distribution of type 7.[1]
- The Cauchy distribution is a stable distribution: if , then .
- The Cauchy distribution is a singular limit of a hyperbolic distribution[citation needed]
- The wrapped Cauchy distribution, taking values on a circle, is derived from the Cauchy distribution by wrapping it around the circle.
- If , , then . For half-Cauchy distributions, the relation holds by setting .















Relativistic Breit–Wigner distribution edit
In nuclear and particle physics, the energy profile of a resonance is described by the relativistic Breit–Wigner distribution, while the Cauchy distribution is the (non-relativistic) Breit–Wigner distribution.[citation needed]
Occurrence and applications edit
- In spectroscopy, the Cauchy distribution describes the shape of spectral lines which are subject to homogeneous broadening in which all atoms interact in the same way with the frequency range contained in the line shape. Many mechanisms cause homogeneous broadening, most notably collision broadening.[30] Lifetime or natural broadening also gives rise to a line shape described by the Cauchy distribution.
- Applications of the Cauchy distribution or its transformation can be found in fields working with exponential growth. A 1958 paper by White [31] derived the test statistic for estimators of for the equation and where the maximum likelihood estimator is found using ordinary least squares showed the sampling distribution of the statistic is the Cauchy distribution.


- The Cauchy distribution is often the distribution of observations for objects that are spinning. The classic reference for this is called the Gull's lighthouse problem[33] and as in the above section as the Breit–Wigner distribution in particle physics.
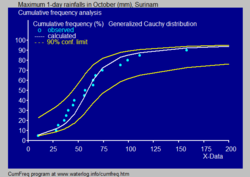
- In hydrology the Cauchy distribution is applied to extreme events such as annual maximum one-day rainfalls and river discharges. The blue picture illustrates an example of fitting the Cauchy distribution to ranked monthly maximum one-day rainfalls showing also the 90% confidence belt based on the binomial distribution. The rainfall data are represented by plotting positions as part of the cumulative frequency analysis.
- The expression for the imaginary part of complex electrical permittivity, according to the Lorentz model, is a Cauchy distribution.
- As an additional distribution to model fat tails in computational finance, Cauchy distributions can be used to model VAR (value at risk) producing a much larger probability of extreme risk than Gaussian Distribution.[34]
See also edit
- Lévy flight and Lévy process
- Laplace distribution, the Fourier transform of the Cauchy distribution
- Cauchy process
- Stable process
- Slash distribution
References edit
- ^ a b c N. L. Johnson; S. Kotz; N. Balakrishnan (1994). Continuous Univariate Distributions, Volume 1. New York: Wiley., Chapter 16.
- ^ Cauchy and the Witch of Agnesi in Statistics on the Table, S M Stigler Harvard 1999 Chapter 18
- ^ Feller, William (1971). An Introduction to Probability Theory and Its Applications, Volume II (2 ed.). New York: John Wiley & Sons Inc. pp. 704. ISBN 978-0-471-25709-7.
- ^ Riley, Ken F.; Hobson, Michael P.; Bence, Stephen J. (2006). Mathematical Methods for Physics and Engineering (3 ed.). Cambridge, UK: Cambridge University Press. pp. 1333. ISBN 978-0-511-16842-0.
- ^ Balakrishnan, N.; Nevrozov, V. B. (2003). A Primer on Statistical Distributions (1 ed.). Hoboken, New Jersey: John Wiley & Sons Inc. pp. 305. ISBN 0-471-42798-5.
- ^ Pillai N.; Meng, X.L. (2016). "An unexpected encounter with Cauchy and Lévy". The Annals of Statistics. 44 (5): 2089–2097. arXiv:1505.01957. doi:10.1214/15-AOS1407. S2CID 31582370.
- ^ Campbell B. Read; N. Balakrishnan; Brani Vidakovic; Samuel Kotz (2006). Encyclopedia of Statistical Sciences (2nd ed.). John Wiley & Sons. p. 778. ISBN 978-0-471-15044-2.
- ^ Knight, Franck B. (1976). "A characterization of the Cauchy type". Proceedings of the American Mathematical Society. 55 (1): 130–135. doi:10.2307/2041858. JSTOR 2041858.
- ^ "Updates to the Cauchy Central Limit". Quantum Calculus. 13 November 2022. Retrieved 21 June 2023.
- ^ Frederic, Chyzak; Nielsen, Frank (2019). "A closed-form formula for the Kullback-Leibler divergence between Cauchy distributions". arXiv:1905.10965 [cs.IT].
- ^ Nielsen, Frank; Okamura, Kazuki (2023). "On f-Divergences Between Cauchy Distributions". IEEE Transactions on Information Theory. 69 (5): 3150–3171. arXiv:2101.12459. doi:10.1109/TIT.2022.3231645. S2CID 231728407.
- ^ Vasicek, Oldrich (1976). "A Test for Normality Based on Sample Entropy". Journal of the Royal Statistical Society, Series B. 38 (1): 54–59. doi:10.1111/j.2517-6161.1976.tb01566.x.
- ^ Park, Sung Y.; Bera, Anil K. (2009). "Maximum entropy autoregressive conditional heteroskedasticity model" (PDF). Journal of Econometrics. 150 (2). Elsevier: 219–230. doi:10.1016/j.jeconom.2008.12.014. Archived from the original (PDF) on 2011-09-30. Retrieved 2011-06-02.
- ^ a b Kyle Siegrist. "Cauchy Distribution". Random. Archived from the original on 9 July 2021. Retrieved 5 July 2021.
- ^ Hampel, Frank (1998), "Is statistics too difficult?" (PDF), Canadian Journal of Statistics, 26 (3): 497–513, doi:10.2307/3315772, hdl:20.500.11850/145503, JSTOR 3315772, S2CID 53117661, archived from the original on 2022-01-25, retrieved 2019-09-25.
- ^ "Illustration of instability of sample means". Archived from the original on 2017-03-24. Retrieved 2014-11-22.
- ^ Cane, Gwenda J. (1974). "Linear Estimation of Parameters of the Cauchy Distribution Based on Sample Quantiles". Journal of the American Statistical Association. 69 (345): 243–245. doi:10.1080/01621459.1974.10480163. JSTOR 2285535.
- ^ Zhang, Jin (2010). "A Highly Efficient L-estimator for the Location Parameter of the Cauchy Distribution". Computational Statistics. 25 (1): 97–105. doi:10.1007/s00180-009-0163-y. S2CID 123586208.
- ^ a b Rothenberg, Thomas J.; Fisher, Franklin, M.; Tilanus, C.B. (1964). "A note on estimation from a Cauchy sample". Journal of the American Statistical Association. 59 (306): 460–463. doi:10.1080/01621459.1964.10482170.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - ^ a b c d Bloch, Daniel (1966). "A note on the estimation of the location parameters of the Cauchy distribution". Journal of the American Statistical Association. 61 (316): 852–855. doi:10.1080/01621459.1966.10480912. JSTOR 2282794.
- ^ a b Ferguson, Thomas S. (1978). "Maximum Likelihood Estimates of the Parameters of the Cauchy Distribution for Samples of Size 3 and 4". Journal of the American Statistical Association. 73 (361): 211–213. doi:10.1080/01621459.1978.10480031. JSTOR 2286549.
- ^ Cohen Freue, Gabriella V. (2007). "The Pitman estimator of the Cauchy location parameter" (PDF). Journal of Statistical Planning and Inference. 137 (6): 1901. doi:10.1016/j.jspi.2006.05.002. Archived from the original (PDF) on 2011-08-16.
- ^ Wilcox, Rand (2012). Introduction to Robust Estimation & Hypothesis Testing. Elsevier.
- ^ Barnett, V. D. (1966). "Order Statistics Estimators of the Location of the Cauchy Distribution". Journal of the American Statistical Association. 61 (316): 1205–1218. doi:10.1080/01621459.1966.10482205. JSTOR 2283210.
- ^ a b c Ferguson, Thomas S. (1962). "A Representation of the Symmetric Bivariate Cauchy Distribution". The Annals of Mathematical Statistics. 33 (4): 1256–1266. doi:10.1214/aoms/1177704357. JSTOR 2237984. Retrieved 2017-01-07.
- ^ a b Molenberghs, Geert; Lesaffre, Emmanuel (1997). "Non-linear Integral Equations to Approximate Bivariate Densities with Given Marginals and Dependence Function" (PDF). Statistica Sinica. 7: 713–738. Archived from the original (PDF) on 2009-09-14.
- ^ Lemons, Don S. (2002), "An Introduction to Stochastic Processes in Physics", American Journal of Physics, 71 (2), The Johns Hopkins University Press: 35, Bibcode:2003AmJPh..71..191L, doi:10.1119/1.1526134, ISBN 0-8018-6866-1
- ^ a b McCullagh, P., "Conditional inference and Cauchy models", Biometrika, volume 79 (1992), pages 247–259. PDF Archived 2010-06-10 at the Wayback Machine from McCullagh's homepage.
- ^ Kyprianou, Andreas (2009). Lévy processes and continuous-state branching processes:part I (PDF). p. 11. Archived (PDF) from the original on 2016-03-03. Retrieved 2016-05-04.
- ^ E. Hecht (1987). Optics (2nd ed.). Addison-Wesley. p. 603.
- ^ White, J.S. (December 1958). "The Limiting Distribution of the Serial Correlation Coefficient in the Explosive Case". The Annals of Mathematical Statistics. 29 (4): 1188–1197. doi:10.1214/aoms/1177706450.
- ^ "CumFreq, free software for cumulative frequency analysis and probability distribution fitting". Archived from the original on 2018-02-21.
- ^ Gull, S.F. (1988) Bayesian Inductive Inference and Maximum Entropy. Kluwer Academic Publishers, Berlin. https://doi.org/10.1007/978-94-009-3049-0_4 Archived 2022-01-25 at the Wayback Machine
- ^ Tong Liu (2012), An intermediate distribution between Gaussian and Cauchy distributions. https://arxiv.org/pdf/1208.5109.pdf Archived 2020-06-24 at the Wayback Machine
External links edit
- "Cauchy distribution", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Earliest Uses: The entry on Cauchy distribution has some historical information.
- Weisstein, Eric W. "Cauchy Distribution". MathWorld.
- GNU Scientific Library – Reference Manual
- Ratios of Normal Variables by George Marsaglia