


Summary
In mathematics, the determinant is a scalar value that is a certain function of the entries of a square matrix. The determinant of a matrix A is commonly denoted det(A), det A, or |A|. Its value characterizes some properties of the matrix and the linear map represented, on a given basis, by the matrix. In particular, the determinant is nonzero if and only if the matrix is invertible and the corresponding linear map is an isomorphism. The determinant of a product of matrices is the product of their determinants.
The determinant of a 2 × 2 matrix is

and the determinant of a 3 × 3 matrix is

The determinant of an n × n matrix can be defined in several equivalent ways, the most common being Leibniz formula, which expresses the determinant as a sum of (the factorial of n) signed products of matrix entries. It can be computed by the Laplace expansion, which expresses the determinant as a linear combination of determinants of submatrices, or with Gaussian elimination, which expresses the determinant as the product of the diagonal entries of a diagonal matrix that is obtained by a succession of elementary row operations.

Determinants can also be defined by some of their properties. Namely, the determinant is the unique function defined on the n × n matrices that has the four following properties:
- The determinant of the identity matrix is 1.
- The exchange of two rows multiplies the determinant by −1.
- Multiplying a row by a number multiplies the determinant by this number.
- Adding to a row a multiple of another row does not change the determinant.
The above properties relating to rows (properties 2-4) may be replaced by the corresponding statements with respect to columns.
The determinant of a square matrix can also be defined directly in terms of the associated linear endomorphism represented by the matrix. Because the determinant is invariant under a similarity transformation of matrices, it really only depends on the linear transformation, and can in principle be defined in a completely "coordinate-free" manner, that is, without using any choice of matrix representation.
Determinants occur throughout mathematics. For example, a matrix is often used to represent the coefficients in a system of linear equations, and determinants can be used to solve these equations (Cramer's rule), although other methods of solution are computationally much more efficient. Determinants are used for defining the characteristic polynomial of a square matrix, whose roots are the eigenvalues. In geometry, the signed n-dimensional volume of a n-dimensional parallelepiped is expressed by a determinant, and the determinant of a linear endomorphism determines how the orientation and the n-dimensional volume are transformed under the endomorphism. This is used in calculus with exterior differential forms and the Jacobian determinant, in particular for changes of variables in multiple integrals.
Two by two matrices edit
The determinant of a 2 × 2 matrix is denoted either by "det" or by vertical bars around the matrix, and is defined as


For example,

First properties edit
The determinant has several key properties that can be proved by direct evaluation of the definition for -matrices, and that continue to hold for determinants of larger matrices. They are as follows:[1] first, the determinant of the identity matrix is 1. Second, the determinant is zero if two rows are the same:



This holds similarly if the two columns are the same. Moreover,

Finally, if any column is multiplied by some number (i.e., all entries in that column are multiplied by that number), the determinant is also multiplied by that number:


Geometric meaning edit
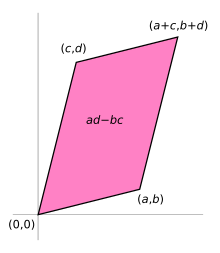
If the matrix entries are real numbers, the matrix A can be used to represent two linear maps: one that maps the standard basis vectors to the rows of A, and one that maps them to the columns of A. In either case, the images of the basis vectors form a parallelogram that represents the image of the unit square under the mapping. The parallelogram defined by the rows of the above matrix is the one with vertices at (0, 0), (a, b), (a + c, b + d), and (c, d), as shown in the accompanying diagram.
The absolute value of ad − bc is the area of the parallelogram, and thus represents the scale factor by which areas are transformed by A. (The parallelogram formed by the columns of A is in general a different parallelogram, but since the determinant is symmetric with respect to rows and columns, the area will be the same.)
The absolute value of the determinant together with the sign becomes the oriented area of the parallelogram. The oriented area is the same as the usual area, except that it is negative when the angle from the first to the second vector defining the parallelogram turns in a clockwise direction (which is opposite to the direction one would get for the identity matrix).
To show that ad − bc is the signed area, one may consider a matrix containing two vectors u ≡ (a, b) and v ≡ (c, d) representing the parallelogram's sides. The signed area can be expressed as |u| |v| sin θ for the angle θ between the vectors, which is simply base times height, the length of one vector times the perpendicular component of the other. Due to the sine this already is the signed area, yet it may be expressed more conveniently using the cosine of the complementary angle to a perpendicular vector, e.g. u⊥ = (−b, a), so that |u⊥| |v| cos θ′ becomes the signed area in question, which can be determined by the pattern of the scalar product to be equal to ad − bc according to the following equations:

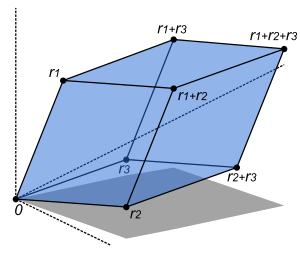
Thus the determinant gives the scaling factor and the orientation induced by the mapping represented by A. When the determinant is equal to one, the linear mapping defined by the matrix is equi-areal and orientation-preserving.
The object known as the bivector is related to these ideas. In 2D, it can be interpreted as an oriented plane segment formed by imagining two vectors each with origin (0, 0), and coordinates (a, b) and (c, d). The bivector magnitude (denoted by (a, b) ∧ (c, d)) is the signed area, which is also the determinant ad − bc.[2]
If an n × n real matrix A is written in terms of its column vectors , then
![{\displaystyle A=\left[{\begin{array}{c|c|c|c}\mathbf {a} _{1}&\mathbf {a} _{2}&\cdots &\mathbf {a} _{n}\end{array}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b1d60337c4cde7b2d5fc3e0365bc8ec5e699ea1a)

This means that maps the unit n-cube to the n-dimensional parallelotope defined by the vectors the region



The determinant gives the signed n-dimensional volume of this parallelotope, and hence describes more generally the n-dimensional volume scaling factor of the linear transformation produced by A.[3] (The sign shows whether the transformation preserves or reverses orientation.) In particular, if the determinant is zero, then this parallelotope has volume zero and is not fully n-dimensional, which indicates that the dimension of the image of A is less than n. This means that A produces a linear transformation which is neither onto nor one-to-one, and so is not invertible.

Definition edit
Let A be a square matrix with n rows and n columns, so that it can be written as

The entries etc. are, for many purposes, real or complex numbers. As discussed below, the determinant is also defined for matrices whose entries are in a commutative ring.

The determinant of A is denoted by det(A), or it can be denoted directly in terms of the matrix entries by writing enclosing bars instead of brackets:

There are various equivalent ways to define the determinant of a square matrix A, i.e. one with the same number of rows and columns: the determinant can be defined via the Leibniz formula, an explicit formula involving sums of products of certain entries of the matrix. The determinant can also be characterized as the unique function depending on the entries of the matrix satisfying certain properties. This approach can also be used to compute determinants by simplifying the matrices in question.
Leibniz formula edit
3 × 3 matrices edit
The Leibniz formula for the determinant of a 3 × 3 matrix is the following:

In this expression, each term has one factor from each row, all in different columns, arranged in increasing row order. For example, bdi has b from the first row second column, d from the second row first column, and i from the third row third column. The signs are determined by how many transpositions of factors are necessary to arrange the factors in increasing order of their columns (given that the terms are arranged left-to-right in increasing row order): positive for an even number of transpositions and negative for an odd number. For the example of bdi, the single transposition of bd to db gives dbi, whose three factors are from the first, second and third columns respectively; this is an odd number of transpositions, so the term appears with negative sign.

The rule of Sarrus is a mnemonic for the expanded form of this determinant: the sum of the products of three diagonal north-west to south-east lines of matrix elements, minus the sum of the products of three diagonal south-west to north-east lines of elements, when the copies of the first two columns of the matrix are written beside it as in the illustration. This scheme for calculating the determinant of a 3 × 3 matrix does not carry over into higher dimensions.
n × n matrices edit
Generalizing the above to higher dimensions, the determinant of an matrix is an expression involving permutations and their signatures. A permutation of the set is a bijective function from this set to itself, with values exhausting the entire set. The set of all such permutations, called the symmetric group, is commonly denoted . The signature of a permutation is if the permutation can be obtained with an even number of transpositions (exchanges of two entries); otherwise, it is








Given a matrix

the Leibniz formula for its determinant is, using sigma notation for the sum,

Using pi notation for the product, this can be shortened into
- .

The Levi-Civita symbol is defined on the n-tuples of integers in as 0 if two of the integers are equal, and otherwise as the signature of the permutation defined by the n-tuple of integers. With the Levi-Civita symbol, the Leibniz formula becomes



where the sum is taken over all n-tuples of integers in [4][5]

Properties of the determinant edit
Characterization of the determinant edit
The determinant can be characterized by the following three key properties. To state these, it is convenient to regard an -matrix A as being composed of its columns, so denoted as


where the column vector (for each i) is composed of the entries of the matrix in the i-th column.

- , where is an identity matrix.
- The determinant is multilinear: if the jth column of a matrix is written as a linear combination of two column vectors v and w and a number r, then the determinant of A is expressible as a similar linear combination:
- The determinant is alternating: whenever two columns of a matrix are identical, its determinant is 0:





If the determinant is defined using the Leibniz formula as above, these three properties can be proved by direct inspection of that formula. Some authors also approach the determinant directly using these three properties: it can be shown that there is exactly one function that assigns to any -matrix A a number that satisfies these three properties.[6] This also shows that this more abstract approach to the determinant yields the same definition as the one using the Leibniz formula.
To see this it suffices to expand the determinant by multi-linearity in the columns into a (huge) linear combination of determinants of matrices in which each column is a standard basis vector. These determinants are either 0 (by property 9) or else ±1 (by properties 1 and 12 below), so the linear combination gives the expression above in terms of the Levi-Civita symbol. While less technical in appearance, this characterization cannot entirely replace the Leibniz formula in defining the determinant, since without it the existence of an appropriate function is not clear.[citation needed]
Immediate consequences edit
These rules have several further consequences:
- The determinant is a homogeneous function, i.e., (for an matrix ).
- Interchanging any pair of columns of a matrix multiplies its determinant by −1. This follows from the determinant being multilinear and alternating (properties 2 and 3 above): This formula can be applied iteratively when several columns are swapped. For exampleYet more generally, any permutation of the columns multiplies the determinant by the sign of the permutation.
- If some column can be expressed as a linear combination of the other columns (i.e. the columns of the matrix form a linearly dependent set), the determinant is 0. As a special case, this includes: if some column is such that all its entries are zero, then the determinant of that matrix is 0.
- Adding a scalar multiple of one column to another column does not change the value of the determinant. This is a consequence of multilinearity and being alternative: by multilinearity the determinant changes by a multiple of the determinant of a matrix with two equal columns, which determinant is 0, since the determinant is alternating.
- If is a triangular matrix, i.e. , whenever or, alternatively, whenever , then its determinant equals the product of the diagonal entries: Indeed, such a matrix can be reduced, by appropriately adding multiples of the columns with fewer nonzero entries to those with more entries, to a diagonal matrix (without changing the determinant). For such a matrix, using the linearity in each column reduces to the identity matrix, in which case the stated formula holds by the very first characterizing property of determinants. Alternatively, this formula can also be deduced from the Leibniz formula, since the only permutation which gives a non-zero contribution is the identity permutation.







Example edit
These characterizing properties and their consequences listed above are both theoretically significant, but can also be used to compute determinants for concrete matrices. In fact, Gaussian elimination can be applied to bring any matrix into upper triangular form, and the steps in this algorithm affect the determinant in a controlled way. The following concrete example illustrates the computation of the determinant of the matrix using that method:

| Matrix |
|
|
| |
| Obtained by |
add the second column to the first |
add 3 times the third column to the second |
swap the first two columns |
add times the second column to the first |
| Determinant |
|
|
|









Combining these equalities gives

Transpose edit
The determinant of the transpose of equals the determinant of A:
- .

This can be proven by inspecting the Leibniz formula.[7] This implies that in all the properties mentioned above, the word "column" can be replaced by "row" throughout. For example, viewing an n × n matrix as being composed of n rows, the determinant is an n-linear function.
Multiplicativity and matrix groups edit
The determinant is a multiplicative map, i.e., for square matrices and of equal size, the determinant of a matrix product equals the product of their determinants:


This key fact can be proven by observing that, for a fixed matrix , both sides of the equation are alternating and multilinear as a function depending on the columns of . Moreover, they both take the value when is the identity matrix. The above-mentioned unique characterization of alternating multilinear maps therefore shows this claim.[8]

A matrix with entries in a field is invertible precisely if its determinant is nonzero. This follows from the multiplicativity of the determinant and the formula for the inverse involving the adjugate matrix mentioned below. In this event, the determinant of the inverse matrix is given by
- .
![{\displaystyle \det \left(A^{-1}\right)={\frac {1}{\det(A)}}=[\det(A)]^{-1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f4f6798a0a88679c1b82126428cf67aae28244fc)
In particular, products and inverses of matrices with non-zero determinant (respectively, determinant one) still have this property. Thus, the set of such matrices (of fixed size over a field ) forms a group known as the general linear group (respectively, a subgroup called the special linear group . More generally, the word "special" indicates the subgroup of another matrix group of matrices of determinant one. Examples include the special orthogonal group (which if n is 2 or 3 consists of all rotation matrices), and the special unitary group.



Because the determinant respects multiplication and inverses, it is in fact a group homomorphism from into the multiplicative group of nonzero elements of . This homomorphism is surjective and its kernel is (the matrices with determinant one). Hence, by the first isomorphism theorem, this shows that is a normal subgroup of , and that the quotient group is isomorphic to .



The Cauchy–Binet formula is a generalization of that product formula for rectangular matrices. This formula can also be recast as a multiplicative formula for compound matrices whose entries are the determinants of all quadratic submatrices of a given matrix.[9][10]
Laplace expansion edit
Laplace expansion expresses the determinant of a matrix recursively in terms of determinants of smaller matrices, known as its minors. The minor is defined to be the determinant of the -matrix that results from by removing the -th row and the -th column. The expression is known as a cofactor. For every , one has the equality






which is called the Laplace expansion along the ith row. For example, the Laplace expansion along the first row ( ) gives the following formula:


Unwinding the determinants of these -matrices gives back the Leibniz formula mentioned above. Similarly, the Laplace expansion along the -th column is the equality

Laplace expansion can be used iteratively for computing determinants, but this approach is inefficient for large matrices. However, it is useful for computing the determinants of highly symmetric matrix such as the Vandermonde matrix


Adjugate matrix edit
The adjugate matrix is the transpose of the matrix of the cofactors, that is,


For every matrix, one has[11]

Thus the adjugate matrix can be used for expressing the inverse of a nonsingular matrix:

Block matrices edit
The formula for the determinant of a -matrix above continues to hold, under appropriate further assumptions, for a block matrix, i.e., a matrix composed of four submatrices of dimension , , and , respectively. The easiest such formula, which can be proven using either the Leibniz formula or a factorization involving the Schur complement, is





If is invertible, then it follows with results from the section on multiplicativity that

which simplifies to when is a -matrix.



A similar result holds when is invertible, namely

Both results can be combined to derive Sylvester's determinant theorem, which is also stated below.
If the blocks are square matrices of the same size further formulas hold. For example, if and commute (i.e., ), then[12]



This formula has been generalized to matrices composed of more than blocks, again under appropriate commutativity conditions among the individual blocks.[13]
For and , the following formula holds (even if and do not commute)[citation needed]



Sylvester's determinant theorem edit
Sylvester's determinant theorem states that for A, an m × n matrix, and B, an n × m matrix (so that A and B have dimensions allowing them to be multiplied in either order forming a square matrix):

where Im and In are the m × m and n × n identity matrices, respectively.
From this general result several consequences follow.
- For the case of column vector c and row vector r, each with m components, the formula allows quick calculation of the determinant of a matrix that differs from the identity matrix by a matrix of rank 1:
- More generally,[14] for any invertible m × m matrix X,
- For a column and row vector as above:
- For square matrices and of the same size, the matrices and have the same characteristic polynomials (hence the same eigenvalues).





Sum edit
The determinant of the sum of two square matrices of the same size is not in general expressible in terms of the determinants of A and of B. However, for positive semidefinite matrices , and of equal size,



![{\displaystyle {\sqrt[{n}]{\det {\!(A+B)}}}\geq {\sqrt[{n}]{\det {\!(A)}}}+{\sqrt[{n}]{\det {\!(B)}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8e77020a4af805fa2f6e3d5b1a1eaab10c936bcb)
Sum identity for 2×2 matrices edit
For the special case of matrices with complex entries, the determinant of the sum can be written in terms of determinants and traces in the following identity:

This can be shown by writing out each term in components . The left-hand side is


Expanding gives

The terms which are quadratic in are seen to be , and similarly for , so the expression can be written


We can then write the cross-terms as

which can be recognized as

which completes the proof.
This has an application to matrix algebras. For example, consider the complex numbers as a matrix algebra. The complex numbers have a representation as matrices of the form







This result followed just from and .

Properties of the determinant in relation to other notions edit
Eigenvalues and characteristic polynomial edit
The determinant is closely related to two other central concepts in linear algebra, the eigenvalues and the characteristic polynomial of a matrix. Let be an -matrix with complex entries. Then, by the Fundamental Theorem of Algebra, must have exactly n eigenvalues . (Here it is understood that an eigenvalue with algebraic multiplicity μ occurs μ times in this list.) Then, it turns out the determinant of A is equal to the product of these eigenvalues,


The product of all non-zero eigenvalues is referred to as pseudo-determinant.
From this, one immediately sees that the determinant of a matrix is zero if and only if is an eigenvalue of . In other words, is invertible if and only if is not an eigenvalue of .

The characteristic polynomial is defined as[18]

Here, is the indeterminate of the polynomial and is the identity matrix of the same size as . By means of this polynomial, determinants can be used to find the eigenvalues of the matrix : they are precisely the roots of this polynomial, i.e., those complex numbers such that



A Hermitian matrix is positive definite if all its eigenvalues are positive. Sylvester's criterion asserts that this is equivalent to the determinants of the submatrices

being positive, for all between and .[19]


Trace edit
The trace tr(A) is by definition the sum of the diagonal entries of A and also equals the sum of the eigenvalues. Thus, for complex matrices A,

or, for real matrices A,

Here exp(A) denotes the matrix exponential of A, because every eigenvalue λ of A corresponds to the eigenvalue exp(λ) of exp(A). In particular, given any logarithm of A, that is, any matrix L satisfying

the determinant of A is given by

For example, for n = 2, n = 3, and n = 4, respectively,

cf. Cayley-Hamilton theorem. Such expressions are deducible from combinatorial arguments, Newton's identities, or the Faddeev–LeVerrier algorithm. That is, for generic n, detA = (−1)nc0 the signed constant term of the characteristic polynomial, determined recursively from

In the general case, this may also be obtained from[20]

where the sum is taken over the set of all integers kl ≥ 0 satisfying the equation

The formula can be expressed in terms of the complete exponential Bell polynomial of n arguments sl = −(l – 1)! tr(Al) as

This formula can also be used to find the determinant of a matrix AIJ with multidimensional indices I = (i1, i2, ..., ir) and J = (j1, j2, ..., jr). The product and trace of such matrices are defined in a natural way as

An important arbitrary dimension n identity can be obtained from the Mercator series expansion of the logarithm when the expansion converges. If every eigenvalue of A is less than 1 in absolute value,

where I is the identity matrix. More generally, if

is expanded as a formal power series in s then all coefficients of sm for m > n are zero and the remaining polynomial is det(I + sA).
Upper and lower bounds edit
For a positive definite matrix A, the trace operator gives the following tight lower and upper bounds on the log determinant

with equality if and only if A = I. This relationship can be derived via the formula for the Kullback-Leibler divergence between two multivariate normal distributions.
Also,

These inequalities can be proved by expressing the traces and the determinant in terms of the eigenvalues. As such, they represent the well-known fact that the harmonic mean is less than the geometric mean, which is less than the arithmetic mean, which is, in turn, less than the root mean square.
Derivative edit
The Leibniz formula shows that the determinant of real (or analogously for complex) square matrices is a polynomial function from to . In particular, it is everywhere differentiable. Its derivative can be expressed using Jacobi's formula:[21]



where denotes the adjugate of . In particular, if is invertible, we have

Expressed in terms of the entries of , these are

Yet another equivalent formulation is
- ,

using big O notation. The special case where , the identity matrix, yields


This identity is used in describing Lie algebras associated to certain matrix Lie groups. For example, the special linear group is defined by the equation . The above formula shows that its Lie algebra is the special linear Lie algebra consisting of those matrices having trace zero.



Writing a -matrix as where are column vectors of length 3, then the gradient over one of the three vectors may be written as the cross product of the other two:




History edit
Historically, determinants were used long before matrices: A determinant was originally defined as a property of a system of linear equations. The determinant "determines" whether the system has a unique solution (which occurs precisely if the determinant is non-zero). In this sense, determinants were first used in the Chinese mathematics textbook The Nine Chapters on the Mathematical Art (九章算術, Chinese scholars, around the 3rd century BCE). In Europe, solutions of linear systems of two equations were expressed by Cardano in 1545 by a determinant-like entity.[22]
Determinants proper originated separately from the work of Seki Takakazu in 1683 in Japan and parallelly of Leibniz in 1693.[23][24][25][26] Cramer (1750) stated, without proof, Cramer's rule.[27] Both Cramer and also Bezout (1779) were led to determinants by the question of plane curves passing through a given set of points.[28]
Vandermonde (1771) first recognized determinants as independent functions.[24] Laplace (1772) gave the general method of expanding a determinant in terms of its complementary minors: Vandermonde had already given a special case.[29] Immediately following, Lagrange (1773) treated determinants of the second and third order and applied it to questions of elimination theory; he proved many special cases of general identities.
Gauss (1801) made the next advance. Like Lagrange, he made much use of determinants in the theory of numbers. He introduced the word "determinant" (Laplace had used "resultant"), though not in the present signification, but rather as applied to the discriminant of a quantic.[30] Gauss also arrived at the notion of reciprocal (inverse) determinants, and came very near the multiplication theorem.[clarification needed]
The next contributor of importance is Binet (1811, 1812), who formally stated the theorem relating to the product of two matrices of m columns and n rows, which for the special case of m = n reduces to the multiplication theorem. On the same day (November 30, 1812) that Binet presented his paper to the Academy, Cauchy also presented one on the subject. (See Cauchy–Binet formula.) In this he used the word "determinant" in its present sense,[31][32] summarized and simplified what was then known on the subject, improved the notation, and gave the multiplication theorem with a proof more satisfactory than Binet's.[24][33] With him begins the theory in its generality.
Jacobi (1841) used the functional determinant which Sylvester later called the Jacobian.[34] In his memoirs in Crelle's Journal for 1841 he specially treats this subject, as well as the class of alternating functions which Sylvester has called alternants. About the time of Jacobi's last memoirs, Sylvester (1839) and Cayley began their work. Cayley 1841 introduced the modern notation for the determinant using vertical bars.[35][36]
The study of special forms of determinants has been the natural result of the completion of the general theory. Axisymmetric determinants have been studied by Lebesgue, Hesse, and Sylvester; persymmetric determinants by Sylvester and Hankel; circulants by Catalan, Spottiswoode, Glaisher, and Scott; skew determinants and Pfaffians, in connection with the theory of orthogonal transformation, by Cayley; continuants by Sylvester; Wronskians (so called by Muir) by Christoffel and Frobenius; compound determinants by Sylvester, Reiss, and Picquet; Jacobians and Hessians by Sylvester; and symmetric gauche determinants by Trudi. Of the textbooks on the subject Spottiswoode's was the first. In America, Hanus (1886), Weld (1893), and Muir/Metzler (1933) published treatises.
Applications edit
Cramer's rule edit
Determinants can be used to describe the solutions of a linear system of equations, written in matrix form as . This equation has a unique solution if and only if is nonzero. In this case, the solution is given by Cramer's rule:



where is the matrix formed by replacing the -th column of by the column vector . This follows immediately by column expansion of the determinant, i.e.


where the vectors are the columns of A. The rule is also implied by the identity


Cramer's rule can be implemented in time, which is comparable to more common methods of solving systems of linear equations, such as LU, QR, or singular value decomposition.[37]

Linear independence edit
Determinants can be used to characterize linearly dependent vectors: is zero if and only if the column vectors (or, equivalently, the row vectors) of the matrix are linearly dependent.[38] For example, given two linearly independent vectors , a third vector lies in the plane spanned by the former two vectors exactly if the determinant of the -matrix consisting of the three vectors is zero. The same idea is also used in the theory of differential equations: given functions (supposed to be times differentiable), the Wronskian is defined to be






It is non-zero (for some ) in a specified interval if and only if the given functions and all their derivatives up to order are linearly independent. If it can be shown that the Wronskian is zero everywhere on an interval then, in the case of analytic functions, this implies the given functions are linearly dependent. See the Wronskian and linear independence. Another such use of the determinant is the resultant, which gives a criterion when two polynomials have a common root.[39]
Orientation of a basis edit
The determinant can be thought of as assigning a number to every sequence of n vectors in Rn, by using the square matrix whose columns are the given vectors. The determinant will be nonzero if and only if the sequence of vectors is a basis for Rn. In that case, the sign of the determinant determines whether the orientation of the basis is consistent with or opposite to the orientation of the standard basis. In the case of an orthogonal basis, the magnitude of the determinant is equal to the product of the lengths of the basis vectors. For instance, an orthogonal matrix with entries in Rn represents an orthonormal basis in Euclidean space, and hence has determinant of ±1 (since all the vectors have length 1). The determinant is +1 if and only if the basis has the same orientation. It is −1 if and only if the basis has the opposite orientation.
More generally, if the determinant of A is positive, A represents an orientation-preserving linear transformation (if A is an orthogonal 2 × 2 or 3 × 3 matrix, this is a rotation), while if it is negative, A switches the orientation of the basis.
Volume and Jacobian determinant edit
As pointed out above, the absolute value of the determinant of real vectors is equal to the volume of the parallelepiped spanned by those vectors. As a consequence, if is the linear map given by multiplication with a matrix , and is any measurable subset, then the volume of is given by times the volume of .[40] More generally, if the linear map is represented by the -matrix , then the -dimensional volume of is given by:







By calculating the volume of the tetrahedron bounded by four points, they can be used to identify skew lines. The volume of any tetrahedron, given its vertices , , or any other combination of pairs of vertices that form a spanning tree over the vertices.


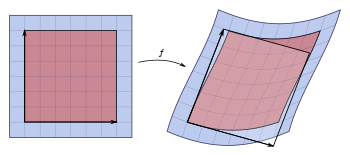

For a general differentiable function, much of the above carries over by considering the Jacobian matrix of f. For

the Jacobian matrix is the n × n matrix whose entries are given by the partial derivatives

Its determinant, the Jacobian determinant, appears in the higher-dimensional version of integration by substitution: for suitable functions f and an open subset U of Rn (the domain of f), the integral over f(U) of some other function φ : Rn → Rm is given by

The Jacobian also occurs in the inverse function theorem.
When applied to the field of Cartography, the determinant can be used to measure the rate of expansion of a map near the poles.[41]
Abstract algebraic aspects edit
Determinant of an endomorphism edit
The above identities concerning the determinant of products and inverses of matrices imply that similar matrices have the same determinant: two matrices A and B are similar, if there exists an invertible matrix X such that A = X−1BX. Indeed, repeatedly applying the above identities yields

The determinant is therefore also called a similarity invariant. The determinant of a linear transformation

for some finite-dimensional vector space V is defined to be the determinant of the matrix describing it, with respect to an arbitrary choice of basis in V. By the similarity invariance, this determinant is independent of the choice of the basis for V and therefore only depends on the endomorphism T.
Square matrices over commutative rings edit
The above definition of the determinant using the Leibniz rule holds works more generally when the entries of the matrix are elements of a commutative ring , such as the integers , as opposed to the field of real or complex numbers. Moreover, the characterization of the determinant as the unique alternating multilinear map that satisfies still holds, as do all the properties that result from that characterization.[42]



A matrix is invertible (in the sense that there is an inverse matrix whose entries are in ) if and only if its determinant is an invertible element in .[43] For , this means that the determinant is +1 or −1. Such a matrix is called unimodular.


The determinant being multiplicative, it defines a group homomorphism

between the general linear group (the group of invertible -matrices with entries in ) and the multiplicative group of units in . Since it respects the multiplication in both groups, this map is a group homomorphism.
Given a ring homomorphism , there is a map given by replacing all entries in by their images under . The determinant respects these maps, i.e., the identity




holds. In other words, the displayed commutative diagram commutes.
For example, the determinant of the complex conjugate of a complex matrix (which is also the determinant of its conjugate transpose) is the complex conjugate of its determinant, and for integer matrices: the reduction modulo of the determinant of such a matrix is equal to the determinant of the matrix reduced modulo (the latter determinant being computed using modular arithmetic). In the language of category theory, the determinant is a natural transformation between the two functors and .[44] Adding yet another layer of abstraction, this is captured by saying that the determinant is a morphism of algebraic groups, from the general linear group to the multiplicative group,




Exterior algebra edit
The determinant of a linear transformation of an -dimensional vector space or, more generally a free module of (finite) rank over a commutative ring can be formulated in a coordinate-free manner by considering the -th exterior power of .[45] The map induces a linear map




As is one-dimensional, the map is given by multiplying with some scalar, i.e., an element in . Some authors such as (Bourbaki 1998) use this fact to define the determinant to be the element in satisfying the following identity (for all ):



This definition agrees with the more concrete coordinate-dependent definition. This can be shown using the uniqueness of a multilinear alternating form on -tuples of vectors in . For this reason, the highest non-zero exterior power (as opposed to the determinant associated to an endomorphism) is sometimes also called the determinant of and similarly for more involved objects such as vector bundles or chain complexes of vector spaces. Minors of a matrix can also be cast in this setting, by considering lower alternating forms with .[46]



edit
Determinants as treated above admit several variants: the permanent of a matrix is defined as the determinant, except that the factors occurring in Leibniz's rule are omitted. The immanant generalizes both by introducing a character of the symmetric group in Leibniz's rule.
Determinants for finite-dimensional algebras edit
For any associative algebra that is finite-dimensional as a vector space over a field , there is a determinant map [47]


This definition proceeds by establishing the characteristic polynomial independently of the determinant, and defining the determinant as the lowest order term of this polynomial. This general definition recovers the determinant for the matrix algebra , but also includes several further cases including the determinant of a quaternion,

- ,

the norm of a field extension, as well as the Pfaffian of a skew-symmetric matrix and the reduced norm of a central simple algebra, also arise as special cases of this construction.

Infinite matrices edit
For matrices with an infinite number of rows and columns, the above definitions of the determinant do not carry over directly. For example, in the Leibniz formula, an infinite sum (all of whose terms are infinite products) would have to be calculated. Functional analysis provides different extensions of the determinant for such infinite-dimensional situations, which however only work for particular kinds of operators.
The Fredholm determinant defines the determinant for operators known as trace class operators by an appropriate generalization of the formula

Another infinite-dimensional notion of determinant is the functional determinant.
Operators in von Neumann algebras edit
For operators in a finite factor, one may define a positive real-valued determinant called the Fuglede−Kadison determinant using the canonical trace. In fact, corresponding to every tracial state on a von Neumann algebra there is a notion of Fuglede−Kadison determinant.
Related notions for non-commutative rings edit
For matrices over non-commutative rings, multilinearity and alternating properties are incompatible for n ≥ 2,[48] so there is no good definition of the determinant in this setting.
For square matrices with entries in a non-commutative ring, there are various difficulties in defining determinants analogously to that for commutative rings. A meaning can be given to the Leibniz formula provided that the order for the product is specified, and similarly for other definitions of the determinant, but non-commutativity then leads to the loss of many fundamental properties of the determinant, such as the multiplicative property or that the determinant is unchanged under transposition of the matrix. Over non-commutative rings, there is no reasonable notion of a multilinear form (existence of a nonzero bilinear form[clarify] with a regular element of R as value on some pair of arguments implies that R is commutative). Nevertheless, various notions of non-commutative determinant have been formulated that preserve some of the properties of determinants, notably quasideterminants and the Dieudonné determinant. For some classes of matrices with non-commutative elements, one can define the determinant and prove linear algebra theorems that are very similar to their commutative analogs. Examples include the q-determinant on quantum groups, the Capelli determinant on Capelli matrices, and the Berezinian on supermatrices (i.e., matrices whose entries are elements of -graded rings).[49] Manin matrices form the class closest to matrices with commutative elements.

Calculation edit
Determinants are mainly used as a theoretical tool. They are rarely calculated explicitly in numerical linear algebra, where for applications such as checking invertibility and finding eigenvalues the determinant has largely been supplanted by other techniques.[50] Computational geometry, however, does frequently use calculations related to determinants.[51]
While the determinant can be computed directly using the Leibniz rule this approach is extremely inefficient for large matrices, since that formula requires calculating ( factorial) products for an -matrix. Thus, the number of required operations grows very quickly: it is of order . The Laplace expansion is similarly inefficient. Therefore, more involved techniques have been developed for calculating determinants.
Decomposition methods edit
Some methods compute by writing the matrix as a product of matrices whose determinants can be more easily computed. Such techniques are referred to as decomposition methods. Examples include the LU decomposition, the QR decomposition or the Cholesky decomposition (for positive definite matrices). These methods are of order , which is a significant improvement over .[52]

For example, LU decomposition expresses as a product

of a permutation matrix (which has exactly a single in each column, and otherwise zeros), a lower triangular matrix and an upper triangular matrix . The determinants of the two triangular matrices and can be quickly calculated, since they are the products of the respective diagonal entries. The determinant of is just the sign of the corresponding permutation (which is for an even number of permutations and is for an odd number of permutations). Once such a LU decomposition is known for , its determinant is readily computed as







Further methods edit
The order reached by decomposition methods has been improved by different methods. If two matrices of order can be multiplied in time , where for some , then there is an algorithm computing the determinant in time .[53] This means, for example, that an algorithm for computing the determinant exists based on the Coppersmith–Winograd algorithm. This exponent has been further lowered, as of 2016, to 2.373.[54]





In addition to the complexity of the algorithm, further criteria can be used to compare algorithms. Especially for applications concerning matrices over rings, algorithms that compute the determinant without any divisions exist. (By contrast, Gauss elimination requires divisions.) One such algorithm, having complexity is based on the following idea: one replaces permutations (as in the Leibniz rule) by so-called closed ordered walks, in which several items can be repeated. The resulting sum has more terms than in the Leibniz rule, but in the process several of these products can be reused, making it more efficient than naively computing with the Leibniz rule.[55] Algorithms can also be assessed according to their bit complexity, i.e., how many bits of accuracy are needed to store intermediate values occurring in the computation. For example, the Gaussian elimination (or LU decomposition) method is of order , but the bit length of intermediate values can become exponentially long.[56] By comparison, the Bareiss Algorithm, is an exact-division method (so it does use division, but only in cases where these divisions can be performed without remainder) is of the same order, but the bit complexity is roughly the bit size of the original entries in the matrix times .[57]

If the determinant of A and the inverse of A have already been computed, the matrix determinant lemma allows rapid calculation of the determinant of A + uvT, where u and v are column vectors.
Charles Dodgson (i.e. Lewis Carroll of Alice's Adventures in Wonderland fame) invented a method for computing determinants called Dodgson condensation. Unfortunately this interesting method does not always work in its original form.[58]
See also edit
Notes edit
- ^ Lang 1985, §VII.1
- ^ Wildberger, Norman J. (2010). Episode 4 (video lecture). WildLinAlg. Sydney, Australia: University of New South Wales. Archived from the original on 2021-12-11 – via YouTube.
- ^ "Determinants and Volumes". textbooks.math.gatech.edu. Retrieved 16 March 2018.
- ^ McConnell (1957). Applications of Tensor Analysis. Dover Publications. pp. 10–17.
- ^ Harris 2014, §4.7
- ^ Serge Lang, Linear Algebra, 2nd Edition, Addison-Wesley, 1971, pp 173, 191.
- ^ Lang 1987, §VI.7, Theorem 7.5
- ^ Alternatively, Bourbaki 1998, §III.8, Proposition 1 proves this result using the functoriality of the exterior power.
- ^ Horn & Johnson 2018, §0.8.7
- ^ Kung, Rota & Yan 2009, p. 306
- ^ Horn & Johnson 2018, §0.8.2.
- ^ Silvester, J. R. (2000). "Determinants of Block Matrices". Math. Gaz. 84 (501): 460–467. doi:10.2307/3620776. JSTOR 3620776. S2CID 41879675.
- ^ Sothanaphan, Nat (January 2017). "Determinants of block matrices with noncommuting blocks". Linear Algebra and Its Applications. 512: 202–218. arXiv:1805.06027. doi:10.1016/j.laa.2016.10.004. S2CID 119272194.
- ^ Proofs can be found in http://www.ee.ic.ac.uk/hp/staff/dmb/matrix/proof003.html
- ^ Lin, Minghua; Sra, Suvrit (2014). "Completely strong superadditivity of generalized matrix functions". arXiv:1410.1958 [math.FA].
- ^ Paksoy; Turkmen; Zhang (2014). "Inequalities of Generalized Matrix Functions via Tensor Products". Electronic Journal of Linear Algebra. 27: 332–341. doi:10.13001/1081-3810.1622.
- ^ Serre, Denis (Oct 18, 2010). "Concavity of det1/n over HPDn". MathOverflow.
- ^ Lang 1985, §VIII.2, Horn & Johnson 2018, Def. 1.2.3
- ^ Horn & Johnson 2018, Observation 7.1.2, Theorem 7.2.5
- ^ A proof can be found in the Appendix B of Kondratyuk, L. A.; Krivoruchenko, M. I. (1992). "Superconducting quark matter in SU(2) color group". Zeitschrift für Physik A. 344 (1): 99–115. Bibcode:1992ZPhyA.344...99K. doi:10.1007/BF01291027. S2CID 120467300.
- ^ Horn & Johnson 2018, § 0.8.10
- ^ Grattan-Guinness 2003, §6.6
- ^ Cajori, F. A History of Mathematics p. 80
- ^ a b c Campbell, H: "Linear Algebra With Applications", pages 111–112. Appleton Century Crofts, 1971
- ^ Eves 1990, p. 405
- ^ A Brief History of Linear Algebra and Matrix Theory at: "A Brief History of Linear Algebra and Matrix Theory". Archived from the original on 10 September 2012. Retrieved 24 January 2012.
- ^ Kleiner 2007, p. 80
- ^ Bourbaki (1994, p. 59)
- ^ Muir, Sir Thomas, The Theory of Determinants in the historical Order of Development [London, England: Macmillan and Co., Ltd., 1906]. JFM 37.0181.02
- ^ Kleiner 2007, §5.2
- ^ The first use of the word "determinant" in the modern sense appeared in: Cauchy, Augustin-Louis "Memoire sur les fonctions qui ne peuvent obtenir que deux valeurs égales et des signes contraires par suite des transpositions operées entre les variables qu'elles renferment," which was first read at the Institute de France in Paris on November 30, 1812, and which was subsequently published in the Journal de l'Ecole Polytechnique, Cahier 17, Tome 10, pages 29–112 (1815).
- ^ Origins of mathematical terms: http://jeff560.tripod.com/d.html
- ^ History of matrices and determinants: http://www-history.mcs.st-and.ac.uk/history/HistTopics/Matrices_and_determinants.html
- ^ Eves 1990, p. 494
- ^ Cajori 1993, Vol. II, p. 92, no. 462
- ^ History of matrix notation: http://jeff560.tripod.com/matrices.html
- ^ Habgood & Arel 2012
- ^ Lang 1985, §VII.3
- ^ Lang 2002, §IV.8
- ^ Lang 1985, §VII.6, Theorem 6.10
- ^ Lay, David (2021). Linear Algebra and It's Applications 6th Edition. Pearson. p. 172.
- ^ Dummit & Foote 2004, §11.4
- ^ Dummit & Foote 2004, §11.4, Theorem 30
- ^ Mac Lane 1998, §I.4. See also Natural transformation § Determinant.
- ^ Bourbaki 1998, §III.8
- ^ Lombardi & Quitté 2015, §5.2, Bourbaki 1998, §III.5
- ^ Garibaldi 2004
- ^ In a non-commutative setting left-linearity (compatibility with left-multiplication by scalars) should be distinguished from right-linearity. Assuming linearity in the columns is taken to be left-linearity, one would have, for non-commuting scalars a, b:
- ^ Varadarajan, V. S (2004), Supersymmetry for mathematicians: An introduction, American Mathematical Soc., ISBN 978-0-8218-3574-6.
- ^ "... we mention that the determinant, though a convenient notion theoretically, rarely finds a useful role in numerical algorithms.", see Trefethen & Bau III 1997, Lecture 1.
- ^ Fisikopoulos & Peñaranda 2016, §1.1, §4.3
- ^ Camarero, Cristóbal (2018-12-05). "Simple, Fast and Practicable Algorithms for Cholesky, LU and QR Decomposition Using Fast Rectangular Matrix Multiplication". arXiv:1812.02056 [cs.NA].
- ^ Bunch & Hopcroft 1974
- ^ Fisikopoulos & Peñaranda 2016, §1.1
- ^ Rote 2001
- ^ Fang, Xin Gui; Havas, George (1997). "On the worst-case complexity of integer Gaussian elimination" (PDF). Proceedings of the 1997 international symposium on Symbolic and algebraic computation. ISSAC '97. Kihei, Maui, Hawaii, United States: ACM. pp. 28–31. doi:10.1145/258726.258740. ISBN 0-89791-875-4. Archived from the original (PDF) on 2011-08-07. Retrieved 2011-01-22.
- ^ Fisikopoulos & Peñaranda 2016, §1.1, Bareiss 1968
- ^ Abeles, Francine F. (2008). "Dodgson condensation: The historical and mathematical development of an experimental method". Linear Algebra and Its Applications. 429 (2–3): 429–438. doi:10.1016/j.laa.2007.11.022.

References edit
- Anton, Howard (2005), Elementary Linear Algebra (Applications Version) (9th ed.), Wiley International
- Axler, Sheldon Jay (2015). Linear Algebra Done Right (3rd ed.). Springer. ISBN 978-3-319-11079-0.
- Bareiss, Erwin (1968), "Sylvester's Identity and Multistep Integer-Preserving Gaussian Elimination" (PDF), Mathematics of Computation, 22 (102): 565–578, doi:10.2307/2004533, JSTOR 2004533, archived (PDF) from the original on 2012-10-25
- de Boor, Carl (1990), "An empty exercise" (PDF), ACM SIGNUM Newsletter, 25 (2): 3–7, doi:10.1145/122272.122273, S2CID 62780452, archived (PDF) from the original on 2006-09-01
- Bourbaki, Nicolas (1998), Algebra I, Chapters 1-3, Springer, ISBN 9783540642435
- Bunch, J. R.; Hopcroft, J. E. (1974). "Triangular Factorization and Inversion by Fast Matrix Multiplication". Mathematics of Computation. 28 (125): 231–236. doi:10.1090/S0025-5718-1974-0331751-8. hdl:1813/6003.
- Dummit, David S.; Foote, Richard M. (2004), Abstract algebra (3rd ed.), Hoboken, NJ: Wiley, ISBN 9780471452348, OCLC 248917264
- Fisikopoulos, Vissarion; Peñaranda, Luis (2016), "Faster geometric algorithms via dynamic determinant computation", Computational Geometry, 54: 1–16, arXiv:1206.7067, doi:10.1016/j.comgeo.2015.12.001
- Garibaldi, Skip (2004), "The characteristic polynomial and determinant are not ad hoc constructions", American Mathematical Monthly, 111 (9): 761–778, arXiv:math/0203276, doi:10.2307/4145188, JSTOR 4145188, MR 2104048
- Habgood, Ken; Arel, Itamar (2012). "A condensation-based application of Cramer's rule for solving large-scale linear systems" (PDF). Journal of Discrete Algorithms. 10: 98–109. doi:10.1016/j.jda.2011.06.007. Archived (PDF) from the original on 2019-05-05.
- Harris, Frank E. (2014), Mathematics for Physical Science and Engineering, Elsevier, ISBN 9780128010495
- Kleiner, Israel (2007), Kleiner, Israel (ed.), A history of abstract algebra, Birkhäuser, doi:10.1007/978-0-8176-4685-1, ISBN 978-0-8176-4684-4, MR 2347309
- Kung, Joseph P.S.; Rota, Gian-Carlo; Yan, Catherine (2009), Combinatorics: The Rota Way, Cambridge University Press, ISBN 9780521883894
- Lay, David C. (August 22, 2005), Linear Algebra and Its Applications (3rd ed.), Addison Wesley, ISBN 978-0-321-28713-7
- Lombardi, Henri; Quitté, Claude (2015), Commutative Algebra: Constructive Methods, Springer, ISBN 9789401799447
- Mac Lane, Saunders (1998), Categories for the Working Mathematician, Graduate Texts in Mathematics 5 (2nd ed.), Springer-Verlag, ISBN 0-387-98403-8
- Meyer, Carl D. (February 15, 2001), Matrix Analysis and Applied Linear Algebra, Society for Industrial and Applied Mathematics (SIAM), ISBN 978-0-89871-454-8, archived from the original on 2009-10-31
- Muir, Thomas (1960) [1933], A treatise on the theory of determinants, Revised and enlarged by William H. Metzler, New York, NY: Dover
- Poole, David (2006), Linear Algebra: A Modern Introduction (2nd ed.), Brooks/Cole, ISBN 0-534-99845-3
- G. Baley Price (1947) "Some identities in the theory of determinants", American Mathematical Monthly 54:75–90 MR0019078
- Horn, Roger Alan; Johnson, Charles Royal (2018) [1985]. Matrix Analysis (2nd ed.). Cambridge University Press. ISBN 978-0-521-54823-6.
- Lang, Serge (1985), Introduction to Linear Algebra, Undergraduate Texts in Mathematics (2 ed.), Springer, ISBN 9780387962054
- Lang, Serge (1987), Linear Algebra, Undergraduate Texts in Mathematics (3 ed.), Springer, ISBN 9780387964126
- Lang, Serge (2002). Algebra. Graduate Texts in Mathematics. New York, NY: Springer. ISBN 978-0-387-95385-4.
- Leon, Steven J. (2006), Linear Algebra With Applications (7th ed.), Pearson Prentice Hall
- Rote, Günter (2001), "Division-free algorithms for the determinant and the Pfaffian: algebraic and combinatorial approaches" (PDF), Computational discrete mathematics, Lecture Notes in Comput. Sci., vol. 2122, Springer, pp. 119–135, doi:10.1007/3-540-45506-X_9, ISBN 978-3-540-42775-9, MR 1911585, archived from the original (PDF) on 2007-02-01, retrieved 2020-06-04
- Trefethen, Lloyd; Bau III, David (1997), Numerical Linear Algebra (1st ed.), Philadelphia: SIAM, ISBN 978-0-89871-361-9
Historical references edit
- Bourbaki, Nicolas (1994), Elements of the history of mathematics, translated by Meldrum, John, Springer, doi:10.1007/978-3-642-61693-8, ISBN 3-540-19376-6
- Cajori, Florian (1993), A history of mathematical notations: Including Vol. I. Notations in elementary mathematics; Vol. II. Notations mainly in higher mathematics, Reprint of the 1928 and 1929 originals, Dover, ISBN 0-486-67766-4, MR 3363427
- Bezout, Étienne (1779), Théorie générale des equations algébriques, Paris
- Cayley, Arthur (1841), "On a theorem in the geometry of position", Cambridge Mathematical Journal, 2: 267–271
- Cramer, Gabriel (1750), Introduction à l'analyse des lignes courbes algébriques, Genève: Frères Cramer & Cl. Philibert, doi:10.3931/e-rara-4048
- Eves, Howard (1990), An introduction to the history of mathematics (6 ed.), Saunders College Publishing, ISBN 0-03-029558-0, MR 1104435
- Grattan-Guinness, I., ed. (2003), Companion Encyclopedia of the History and Philosophy of the Mathematical Sciences, vol. 1, Johns Hopkins University Press, ISBN 9780801873966
- Jacobi, Carl Gustav Jakob (1841), "De Determinantibus functionalibus", Journal für die reine und angewandte Mathematik, 1841 (22): 320–359, doi:10.1515/crll.1841.22.319, S2CID 123637858
- Laplace, Pierre-Simon, de (1772), "Recherches sur le calcul intégral et sur le systéme du monde", Histoire de l'Académie Royale des Sciences (seconde partie), Paris: 267–376
{{citation}}: CS1 maint: multiple names: authors list (link)
External links edit
- Suprunenko, D.A. (2001) [1994], "Determinant", Encyclopedia of Mathematics, EMS Press
- Weisstein, Eric W. "Determinant". MathWorld.
- O'Connor, John J.; Robertson, Edmund F., "Matrices and determinants", MacTutor History of Mathematics Archive, University of St Andrews
- Determinant Interactive Program and Tutorial
- Linear algebra: determinants. Archived 2008-12-04 at the Wayback Machine Compute determinants of matrices up to order 6 using Laplace expansion you choose.
- Determinant Calculator Calculator for matrix determinants, up to the 8th order.
- Matrices and Linear Algebra on the Earliest Uses Pages
- Determinants explained in an easy fashion in the 4th chapter as a part of a Linear Algebra course.